Routing Algorithms
상위 문서: Network Layer
개요
라우팅 알고리즘(Routing algorithm)이란 송신 호스트에서 수신 호스트까지의 "좋은(good)" 경로(path)[1]들을 결정하는 알고리즘을 의미한다. 경로란 패킷이 출발지 호스트에서 목적지 호스트까지 이동할 때 거치는 라우터들의 순서를 의미한다. 이때 "좋은" 경로의 기준은 가장 비용이 적거나(least "cost"), 가장 빠르거나("fastest"), 가장 혼잡하지 않은("least congested") 경로를 의미한다.
Network graph notation

이때 라우팅 알고리즘은 figure 1과 같이 그래프를 사용하여 형식화된다. 그래프 G = (N, E)는 노드들의 집합 N과 간선(edge)들의 모음 E로 구성되며, 각 간선은 N에 속한 두 노드의 쌍이다. 이는 아래와 같이 나타내어 진다.
N = set of routers = {u, v, w, x, y, z}
E = set of links ={(u,v), (u,x), (v,x), (v,w), (x,w), (x,y), (w,y), (w,z), (y,z)}
이때 그래프의 각 노드는 라우터를 의미하며, 간선은 해당 라우터들 간의 물리적인 링크(link)를 의미한다. 간선은 해당 링크의 비용을 나타내는 값을 가진다. 일반적으로 간선의 비용은 해당 링크의 물리적인 길이와 링크의 혼잡도 등에 의해 결정된다. 이때 각 간선과 경로의 비용은 다음과 같이 표기한다.
(x, y) E, c(x,y) = cost of link (x,y) (x, y) E, c(x,y) = //해당 간선은 존재하지 않음 cost of path (x2, x2, x3, ⋯, xp) = c(x1,x2) + c(x2,x3) + ⋯ + c(xp-1,xp)
Routing algorithm classification
라우팅 알고리즘을 분류하는 한가지 방식은 중앙 집중형 라우팅 알고리즘(centralized routing algorithm)과 분산형 라우팅 알고리즘(decentralized routing algorithm)으로 구분하는 것이다. 라우팅 알고리즘을 분류하는 두 번째 방식은 그것이 정적(static)이냐 동적(dynamic)이냐에 따른 것이다.
Centralized vs. Decentralized
중앙 집중형 라우팅 알고리즘은 네트워크에 대한 전체적이고 전역적인 정보(topology[2])를 이용하여 출발지와 목적지 간의 최소 비용 경로를 계산한다. 따라서 해당 알고리즘은 모든 노드 간의 연결 정보와 각각의 링크의 비용을 필요로 한다. 해당 알고리즘은 흔히 LS(link-state) 알고리즘이라고 불린다.
분산형 라우팅 알고리즘은 각각의 라우터 들에 의해서 반복적이고 분산된 방식으로 수행된다. 이때 어떠한 노드도 전체 네트워크의 LS에 대한 완전한 정보를 가지고 있지 않다. 대신 각 노드는 자신에게 직접 연결된 링크들의 비용만 알고 있으므로, 각 노드는 이웃 노드들과의 정보 교환과 계산을 반복하여 최소 비용 경로를 점진적으로 계산한다. 해당 알고리즘은 흔히 DV(distance-vector) 알고리즘이라고 불린다. 왜냐하면 각 노드는 네트워크 내의 다른 모든 노드에 대한 비용의 추정치를 벡터 형태로 유지하기 때문이다.
Static vs. Dynamic
정적(Static) 라우팅 알고리즘에서는 패킷의 경로가 시간에 따라 매우 느리게 변화하며, 보통 사람의 개입을 통해서 변경된다.[3] 반면 동적(dynamic) 라우팅 알고리즘은 네트워크 트래픽 부하나 topology가 변할 때 라우팅 경로를 변경한다. 동적 알고리즘은 주기적으로 실행되거나 해당 변화에 직접적으로 반응하여 구현된다. 동적 알고리즘은 네트워크 변화에 더 잘 반응할 수 있지만, 라우팅 루프(routing loop)나 경로 진동(route oscillation) 같은 문제에 더 취약할 수 있다.
LS routing algorithm
LS 라우팅 알고리즘 중 가장 일반적인 알고리즘은 Dijkstra 알고리즘이다. 다익스트라 알고리즘은 네트워크 topology와 모든 링크 비용을 바탕으로 출발 노드(u)에서 다른 모든 노드들까지의 최소 비용 경로를 계산한다. 이때 각 노드는 자신과 연결된 링크들의 식별자와 비용을 담은 링크 상태 패킷(link-state packet)을 네트워크 내의 모든 다른 노드들에게 브로드캐스트(LS broadcast)하여 이를 구현할 수 있다. 다익스트라 알고리즘은 반복적이며, 알고리즘의 k번째 반복이 끝난 후에는, 목적지 노드 k개에 대한 최소 비용 경로가 계산된다는 특징이 있다. 이때 다익스트라 알고리즘을 설명하기 위한 표기는 다음과 같다:
D(v): 알고리즘의 현재 단계에서 출발 노드에서 목적지 노드 v까지의 최소 비용 경로의 비용 p(v): 출발 노드에서 목적지 노드 v까지의 현재 단계의 최소 비용 경로에서 v 직전 노드[4] N': 최소 비용 경로가 확정된 노드들의 부분집합이다. 즉, v N'는 출발 노드에서 v까지의 최소 비용 경로가 확정되었음을 의미한다.
다익스트라 알고리즘은 다음과 같다.
Initialization:
N' = {u}
//출발 노드 u와 인접한 노드들에서의 경로 비용을 계산한다.
for all nodes v
if v is a neighbor of u
then D(v) = c(u,v)
else D(v) = ∞
Loop
find w not in N' such that D(w) is a minimum
add w to N'
//N'에 포함되지 않은 모든 노드들에 대해서 D(v)를 계산한다.
update D(v) for each neighbor v of w and not in N':
//노드 v에 대한 새로 계산된 비용은 이전 단계에서의 비용, 혹은 u ~ w의 경로 비용에 c(w,v)를 더한 값이다.
D(v) = min(D(v), D(w) + c(w,v))
until N' = N
다익스트라 알고리즘은 초기화 단계와 반복 루프로 구성되며, 해당 알고리즘은 네트워크에 있는 노드 수 만큼 반복된다. 알고리즘이 종료되면 출발 노드 u에서 네트워크 내의 다른 모든 노드들까지의 최단 경로가 계산된다. Figure 2를 기준으로 최단 경로를 계산하면, 그 결과는 아래 표와 같다.

| Step | N' | D(v), p(v) | D(w), p(w) | D(x), p(x) | D(y), p(y) | D(z), p(z) |
|---|---|---|---|---|---|---|
| 0 | u | 2, u | 5, u | 1, u | ∞ | ∞ |
| 1 | ux | 2, u | 4, x | 2, x | ∞ | |
| 2 | uxy | 2, u | 3, y | 4, y | ||
| 3 | uxyv | 3, y | 4, y | |||
| 4 | uxyvw | 4, y | ||||
| 5 | uxyvwz |
Figure 2는 위의 최소 경로 계산 결과를 바탕으로 설정된 라우터 u에 대한 forwarding table이다.
Algorithm complexity
다익스트라 알고리즘의 복잡도는 n개의 노드가 주어졌을 때, O(n2)이다. 그 이유는 첫 번째 반복에서는, N'에 포함되지 않은 n개의 노드 전체를 검사하여 최소 비용 노드를 찾아야 하고, 두 번째 반복에서는 n−1개의 노드를 검사해야 하고, 세 번째 반복에서는 n−2개, ... 와 같은 방식으로 반복되므로 총 반복 동안 우리가 검사해야 할 노드의 수는 n(n+1)/2가 되기 때문이다.
Oscillation
- Figure 3. Oscillation example
-
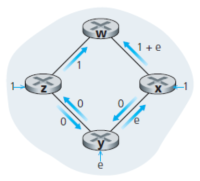 (a) Initial routing
(a) Initial routing -
 (b) x, y detect better path to w, clockwise
(b) x, y detect better path to w, clockwise -
 (c) x, y, z detect better path to w, counterclockwise
(c) x, y, z detect better path to w, counterclockwise -
(d) x, y, z detect better path to w, clockwise



LS 알고리즘은 oscillation 현상이라는 문제가 발생할 수 있다. Figure 3는 oscillation 현상이 일어나는 예시를 보여준다. 해당 예제에서 각각의 링크 비용은 해당 링크에서 처리되는 트래픽의 양을 반영하며, 비대칭적이다.[5]
Figure 3(a)에서 노드 z는 w를 목적지로 하는 트래픽 1 단위를 생성하며, 노드 x도 w를 목적지로 하는 트래픽 1 단위를 생성한다. 노드 y는 w로 향하는 트래픽을 e만큼 생성한다.
Figure 3(b)에서의 노드 y는 Figure 3(a)의 링크 비용을 기반으로 계산하여 시계 방향 경로가 비용 1이며, 자신이 이전에 사용하던 반시계 방향 경로의 비용은 1+e임을 파악한다. 따라서 y의 최소 비용 경로는 시계 방향으로 바뀐다. 마찬가지로, x도 자신의 새로운 최소 비용 경로가 시계 방향임을 판단하고, 결과는 그림 Figure 3(b)에 표시된 비용으로 나타난다.
Figure 3(c)에서의 x, y, z는 모두 반시계 방향 경로로의 경로 비용이 0임을 탐지하고, 모든 트래픽을 반시계 방향 경로로 라우팅한다. Figure 3(d)에서는 모두 시계 방향 경로로 다시 전환한다. 이러한 문제는 모든 라우터가 동기적으로 해당 알고리즘을 수행하면서 링크 비용이 동적으로 변하기 때문에 발생한다.
DV Routing algorithm
DV 라우팅 알고리즘은 Bellman-Ford 방정식을 기반으로 한다. Bellman-Ford 방정식은 를 노드 x에서 y까지의 최소 비용 경로의 비용이라고 할 때, 를 구하는 방정식이며 아래와 같다:
이때 는 x의 모든 이웃 v에 대해 계산된다. 예를 들어, figure 2에서 를 구하면 다음과 같다.
clearly, , ,

이를 바탕으로 DV 라우팅 알고리즘은 다음과 같은 방식으로 구현된다. 각 노드 x는 모든 목적지 y ∈ N에 대해 자신에서 y까지의 최소 경로 비용의 추정값 를 가진다. 이 추정값 전부를 DV(Distance Vector) 라고 한다. DV 알고리즘에서는 각 노드 x가 다음 정보를 유지한다:
- 각 이웃 v와의 직접 연결 비용 c(x,v)
- 노드 x의 거리 벡터
- x의 각 이웃 v의 거리 벡터
이 알고리즘에서는 각 노드가 수시로 자신의 DV를 모든 이웃 노드에게 전송한다. 노드 x가 어떤 이웃 w로부터 새로운 DV를 받으면, 그것을 저장한 뒤, Bellman-Ford 방정식을 이용하여 자신의 거리 벡터를 다음과 같이 갱신한다:
만약 해당 DV의 갱신 결과, x의 DV가 변경되었다면 x는 업데이트된 DV를 이웃들에게 전송하며, 그 이웃들도 자신의 DV를 갱신하게 된다. Figure 4는 해당 알고리즘이 어떻게 동작하는지 보여준다. 각 라우터의 초기 라우팅 테이블은 자신의 DV만을 포함하고, 그 외에는 ∞로 초기화되어 있다. 하지만 서로 DV를 이웃 라우터에게 보내고, 받은 DV를 이용해 자신의 DV를 갱신하고 이를 공유하는 작업을 반복하여 최종적인 결과를 가지게 된다.

이를 바탕으로 DV 라우팅 알고리즘의 특징을 구할 수 있다. 먼저 DV 라우팅 알고리즘은 반복적(iterative), 비동기적(asynchronous)이다:
- 각 노드에서의 지역 반복(local iteration) 두가지 경우에 발생한다.
- 직접 연결된 링크(local link)의 비용이 바뀔 때
- 이웃 노드로 부터 DV 업데이트 메시지를 받을 때
- 각 노드에서의 지역 반복은 위 두가지 경우가 발생하지 않을 때까지 반복된다.
또한 DV 라우팅 알고리즘은 아래와 같은 특징 때문에 분산적(distributed)이다:
- 각 노드는 자신의 DV가 바뀐 경우에만 이웃에게 알린다.
- Figure 5는 각각의 노드가 어떤 방식으로 동작하는지 보여준다.
Link-Cost Changes and Link Failure

DV 라우팅 알고리즘을 수행 중인 노드는 직접 연결된 링크(local link)의 비용이 바뀔 때 자신의 DV를 갱신하고, 최소 비용 경로의 비용에 변경이 생긴 경우 이웃 노드에게 갱신된 DV를 알린다. Figure 6(a)는 y에서 x로의 링크 비용이 4에서 1로 바뀌는 상황을 보여준다. 이때 목적지를 x로 하는 y와 z의 DV는 다음과 같이 변경된다.
- 시점 t0일 때, y는 링크 비용의 변경을 감지하고, DV 테이블을 갱신하며, 이를 이웃들에게 알린다.
- 시점 t1일 때, z는 y로부터의 업데이트를 수신하고 DV 테이블을 갱신한다. z는 x까지의 새로운 최소 비용을 계산(5 → 2)하고, 갱신된 DV를 이웃들에게 올린다.
- 시점 t2일 때, y는 z로부터의 업데이트를 수신하고 DV 테이블을 갱신한다. 그러나 y의 최소 비용에는 변화가 없으므로 이를 알리지 않는다.
위에서, DV 라우팅 알고리즘이 정지 상태에 도달하기 까지 단 두 번의 반복만이 필요하며, 링크 비용이 감소하였다는 "좋은 소식은 빨리 전파된다"는 것을 보여준다. Figure 6(b)는 x와 y 사이의 링크 비용이 4에서 60으로 증가한 상황을 보여준다. 시점 t0일 때, y는 링크 비용이 4에서 60으로 증가하였음을 감지하고, 목적지 x에 대한 최소 비용 경로를 다음과 같이 새로 계산한다.
물론 이는 네트워크의 전역적인 관점에서는 맞지 않지만 노드 y가 가진 유일한 정보는 자신에서 x까지 직접 가는 비용이 60이고, z가 이전에 알려준 x까지의 비용이 5라는 사실 뿐이다. 따라서 y는 x로 가기 위해 z를 경유하여 라우팅을 시도하고, z도 x로 가기 위해 y를 경유하여 라우팅한다. 이로 인해 시점 t1에는 라우팅 루프(routing loop)가 생긴다. 즉, x를 향하는 패킷이 y나 z에 도착하면, 이 패킷은 해당 두 노드 사이에서 사라지지 않고 끝없이 왕복한다.[6]
또한 노드 y는 x까지의 새로운 최소 비용 경로를 계산하였으므로, 시점 t1일때 z에게 자신의 새로운 DV를 알린다. 그후, z는 y로부터 새로운 DV를 수신하고, y가 x까지의 최소 비용이 6이라고 주장하는 것을 알게 된다. 이로 인해 z는 x까지의 최소 비용을 다음과 같이 새로 계산한다.
이때 z의 x까지의 최소 비용이 증가하였으므로, z는 이 정보를 다시 y에게 알린다. 이와 유사하게, z로부터 새로운 거리 벡터를 받은 후, y는 로 계산하고, z에게 다시 갱신된 DV를 보낸다. 또한 z는 로 계산하여 y에게 다시 보낸다. 이 과정은 y와 z 사이에서 총 44번의 갱신된 DV의 공유가 이루어져야 비로소 z는 y를 경유한 경로의 비용이 50을 초과함을 계산하고, z는 x까지의 최소 경로가 x로 직접 가는 것임을 알게된다. 이후 y는 z를 통해 x로 라우팅한다. 해당 예시는 링크 비용이 증가하였다는 "나쁜 소식은 매우 천천히 전파되었다."라는 것을 보여준다. 이러한 문제는 count-to-infinity라고 불린다.
Count-to-infinity 문제를 해결하기 위해서 사용되는 기번이 poisoned reverse이다. 해당 기법은 노드 z가 y를 경유해 목적지 x로 라우팅하고 있다면 z는 y에게 라고 거짓으로 알린다.[7] 즉, z는 y를 통해 x로 라우팅하는 한, 이 거짓말을 계속하여 y가 x로 직접 라우팅하도록 한다.
이는 실제로 count-to-infinity 문제를 해결할 수 있다. 위 예제에서 poisoned reverse 기법이 적용된다면 y의 DV 테이블에는 라고 되어 있다. 따라서 y는 시점 t0에 (x, y) 링크의 비용이 4에서 60으로 바뀌었을 때, y는 자신의 DV를 갱신하고, 더 높은 비용인 60을 감수하여 계속 x로 직접 라우팅한다. 그리고 z에게 자신이 x로 가는 새로운 비용인 을 알린다. 시점 t1에 z가 y로 부터 갱신된 DV를 받으면, z는 x로 가는 경로를 직접 연결된 (z, x) 링크를 통해 가는 경로로 즉시 바꾸고 그 경로인 을 y에게 다시 알린다. 이 업데이트를 수신한 후 y는 자신의 DV 테이블을 로 업데이트한다. 또한, z가 새롭게 x로 가는 y의 최소 비용 경로 위에 있으므로, y는 다시 z에게 라고 알린다.[8]
Poisoned reverse는 위의 count-to-infinity 문제를 해결하였지만, 일반적인 경우에서 해결할 수 있는 것은 아니다. 세 개 이상의 노드가 얽힌 루프에 대해서는 poisoned reverse 기법이 이를 감지하여 해결할 수 없기 때문이다.
A Comparison of LS and DV Routing Algorithms
메시지의 복잡도(Message complexity) 면에서, LS 알고리즘에서는 각 노드가 네트워크 내의 모든 링크 비용을 알아야 한다. 이를 위해서 총 O(NE)개의 메시지가 전송된다. 또한 링크 비용이 변경될 때마다 새로운 링크 비용은 모든 노드에게 전파된다. DV 알고리즘은 알고리즘이 수렴할 때까지 각 반복마다 직접 연결된 이웃들 사이의 메시지 교환을 요구한다. 링크 비용이 변경될 경우, 그 변경된 링크 비용이 그 링크에 연결된 노드 중 하나의 최소 경로 비용을 바꾸는 경우에만, DV 알고리즘은 그 변경 결과를 전파한다.
수렴 속도(Speed of convergence)의 측면에서는 LS 알고리즘이 O(N2)의 복잡도를 가지는 반면, oscillation 문제가 발생할 수 있다는 단점이 있다. DV 알고리즘은 수렴하는 동안 count-to-infinity 문제로 인해 라우팅 루프가 발생할 수 있어, 수렴 시간의 편차가 크다는 특징이 있다.
또한 두 알고리즘은 라우터가 고장나거나 오작동하는 등의 상황에 대처하는 견고성(robustness)의 측면에서 제공하는 정도가 다르다. LS 알고리즘에서는 하나의 라우터가 오직 자신과 연결된 "링크"에 대해서만 잘못된 비용을 브로드캐스트할 수 있다. 또한 LS 노드는 오직 자신의 forwarding table 만을 계산하므로, 다른 노드들도 각자 독립적으로 계산을 수행하므로 경로의 계산이 다소 분리되어 있어 어느 정도의 견고성을 제공한다.
반면 DV 알고리즘에서는 한 노드가 "모든" 목적지에 대한 "경로"에 대해서 잘못된 비용을 이웃에게 전달할 수 있다. 이때 각 반복마다 노드의 계산 결과가 이웃에게 전달되고, 이웃의 이웃에게도 간접적으로 전달된다. 이에 따라, 잘못된 계산이 네트워크 전체에 확산될 수도 있다.