다른 명령
| 37번째 줄: | 37번째 줄: | ||
==Concurrent Programming with Processes== | ==Concurrent Programming with Processes== | ||
Concurrent 프로그래밍의 가장 단순한 방법은 fork(), exec(), waitpid()와 같은 함수들을 사용해 프로세스를 통해 구현하는 것이다. 예를 들어 concurrent 서버를 구축하는 방식 중 하나는 부모 프로세스에서 클라이언트의 연결 요청을 수락하고, 그 후에 각각의 클라이언트마다 새로운 자식 프로세스를 생성하여 서비스를 제공하는 것이다. | Concurrent 프로그래밍의 가장 단순한 방법은 fork(), exec(), waitpid()와 같은 함수들을 사용해 프로세스를 통해 구현하는 것이다. 예를 들어 concurrent 서버를 구축하는 방식 중 하나는 부모 프로세스에서 클라이언트의 연결 요청을 수락하고, 그 후에 각각의 클라이언트마다 새로운 자식 프로세스를 생성하여 서비스를 제공하는 것이다. | ||
<gallery caption="Figure 2" widths="200px" heights="200px"> | |||
이 방식이 어떻게 작동하는지 살펴보기 위해, 두 개의 클라이언트와 하나의 서버가 있고, 서버가 listening 디스크립터(예: listenfd(3))을 통해 연결 요청을 기다린다고 가정하자. 클라이언트 1이 먼저 서버에게 연결 요청을 보낸다면, 서버는 해당 요청을 수락하고 connected 디스크립터(예: connfd(4))를 반환한다. | Server accepts connection.png|Figure 2. Server accepts connection | ||
부모가 클라이언트 1을 위해 자식을 생성한 이후, 클라이언트 2가 새로운 연결 요청을 보낸다고 하자. 그러면 서버는 연결 요청을 수락하고, connfd(5)를 반환한다. | Server forks a child.png|Figure 3. Server forks a child | ||
Server accepts another connection.png|Figure 4. Server accepts another connection | |||
Server forks another child.png|Figure 5. Server forks another child | |||
</gallery> | |||
이 방식이 어떻게 작동하는지 살펴보기 위해, 두 개의 클라이언트와 하나의 서버가 있고, 서버가 listening 디스크립터(예: listenfd(3))을 통해 연결 요청을 기다린다고 가정하자. 클라이언트 1이 먼저 서버에게 연결 요청을 보낸다면, 서버는 해당 요청을 수락하고 connected 디스크립터(예: connfd(4))를 반환한다. 해당 요청을 수락한 후, 서버는 자식 프로세스를 fork()하고, 해당 자식 프로세스는 서버의 [[System-Level I/O#Sharing Files|디스크립터 테이블]]의 전체 복사본을 가진다. 따라서 자식은 listenfd(3)를 닫고, 부모는 connfd(4)를 닫는다. 이때, 부모 자식의 connfd는 동일한 [[System-Level I/O#Sharing Files|파일 테이블]] 항목을 가리키므로, 부모가 자신의 connfd를 반드시 닫아야 한다. 만약 그렇지 않다면, 해당 connfd의 파일 테이블 항목은 삭제되지 않고, 결과적으로 메모리 누수(memory leak)가 발생하여, 가용 메모리를 모두 소비하고 시스템이 다운될 수 있다.<br> | |||
부모가 클라이언트 1을 위해 자식을 생성한 이후, 클라이언트 2가 새로운 연결 요청을 보낸다고 하자. 그러면 서버는 연결 요청을 수락하고, connfd(5)를 반환한다. 이후 부모는 또 다른 자식 프로세스를 fork()하고, 이 자식 프로세스는 connfd(5)를 이용해 클라이언트 2에게 서비스를 제공한다. 이 시점에서, 부모는 다음 연결 요청을 기다리고 있으며, 두 자식은 각자의 클라이언트를 동시(concurrently)에 서비스하고 있다. 이 모든 과정들은 figure 2에 잘 나타나 있다. | |||
===Process-Based Concurrent Echo Server=== | |||
아래는 process-based concurrent 서버의 간단한 예시를 보여준다. 이때 아래 코드에서 나온 echo() 함수는 [[Network Programming#Example Echo Client and Server: Iterative|Network Programming]] 문서에서 설명된 코드를 그대로 사용하였다: | |||
<syntaxhighlight lang="c"> | |||
#include "csapp.h" | |||
void echo(int connfd); | |||
void sigchld_handler(int sig) | |||
{ | |||
while (waitpid(-1, 0, WNOHANG) > 0); //모든 좀비 프로세스를 수거한다. | |||
return; | |||
} | |||
int main(int argc, char **argv) | |||
{ | |||
int listenfd, connfd; | |||
socklen_t clientlen; | |||
struct sockaddr_storage clientaddr; | |||
if (argc != 2) { | |||
fprintf(stderr, "usage: %s <port>\n", argv[0]); | |||
exit(0); | |||
} | |||
Signal(SIGCHLD, sigchld_handler); //SIGCHLD에 대한 시그널 핸들러 등록 | |||
listenfd = Open_listenfd(argv[1]); //argv[1]에 해당하는 포트 번호로 서버용 소켓을 열고 bind, listen | |||
while (1) { | |||
clientlen = sizeof(struct sockaddr_storage); | |||
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen); ////클라이언트가 연결 요청을 보내면 수락, connfd 생성 | |||
if (Fork() == 0) { | |||
Close(listenfd); //자식 프로세스는 listeing 디스크립터가 필요없으므로 닫는다. | |||
echo(connfd); //echo() 함수를 통해 서버와 통신한다. | |||
Close(connfd); //해당 connfd를 다 썼으므로 닫는다. | |||
exit(0); | |||
} | |||
Close(connfd); //서버는 해당 connfd가 필요없으므로 닫는다. | |||
} | |||
} | |||
</syntaxhighlight> | |||
위 코드를 기반으로하는 서버는 몇가지 주의 사항을 가진다. 먼저 서버는 일반적으로 장기간 실행되므로, 좀비 프로세스를 수거하는 SIGCHLD 핸들러를 반드시 포함하여야 한다. 이때 리눅스의 시그널을 큐잉되지 않으므로, SIGCHLD 핸들러는 여러 좀비 프로세스들을 한번에 수거할 수 있어야 한다. 그리고, 부모와 자식은 각자의 connfd 복사본을 반드시 닫아야 한다. 특히 부모가 자신의 connfd 복사본을 닫지 않으면 메모리 누수가 생길 수 있다. 마지막으로, 소켓의 파일 테이블 내의 reference count 때문에, 부모 자식 모두의 connfd 복사본이 닫힐 때까지 클라이언트와의 연결은 종료되지 않는다. | |||
===Process-based Server Execution Model=== | |||
Process-based 방식은 부모 프로레스와 자식 프로세스 사이에서 명확하게 정의되는 공유 모델을 가지고 있다. 파일 테이블은 공유하지만, 파일 디스크립터와 전역 변수들은 서로 공유하지 않는다. 이는 간단하고 직관적이므로 장점이라고 볼 수 있다. 또한 프로세스 마다 주소 공간이 분리되어 있다는 특징을 가지고 있는데, 이는 장점이자 단점이다. 이는 하나의 프로세스가 실수로 다른 프로세스의 가상 메모리를 덮어쓰는 것이 불가능하게 만들며, 이는 여러 오류들을 없애 준다. 하지만 주소 공간이 분리되어 있으므로, 프로세스 사이에서의 정보 공유가 더욱 어려워지며 서로 정보를 공유하기 위해서는 명시적인 IPC(interprocess communications) 메커니즘을 사용해야 한다. 또 다른 단점은, 프로세스 제어와 IPC에 추가적인 오버헤드가 발생하여 속도가 느려지는 경향이 있다는 것이다. | |||
<syntaxhighlight lang="c"> | |||
</syntaxhighlight> | |||
<syntaxhighlight lang="c"> | |||
</syntaxhighlight> | |||
<syntaxhighlight lang="c"> | |||
</syntaxhighlight> | |||
<syntaxhighlight lang="c"> | |||
</syntaxhighlight> | |||
<syntaxhighlight lang="c"> | |||
</syntaxhighlight> | |||
<syntaxhighlight lang="c"> | |||
</syntaxhighlight> | |||
==각주== | ==각주== | ||
[[분류:컴퓨터 시스템]] | [[분류:컴퓨터 시스템]] | ||
2025년 5월 14일 (수) 05:15 판
상위 문서: 컴퓨터 시스템
개요
컴퓨터 공학에서, 동시성(concurrent)이란 control flow들이 시간상으로 겹치는 것을 의미한다. 이는 컴퓨터 시스텀의 여러 계층에서 나타나며, OS 커널이 여러 애플리케이션을 실행하기 위해 사용하는 메커니즘 중 하나이다. 하지만 concurrent라는 개념은 애플리케이션 수준에서도 적용되어 아래와 같이 사용될 수 있다:
- 느린 I/O 장치에 접근: I/O 장치는 상대적으로 느리게 실행되며, 이에 따라 CPU는 커널이 해당 작업을 수행하는 동안 다른 프로세스를 실행한다.
- 사람과의 상호 작용: 컴퓨터를 사용하는 사람들은 동시에 여러 작업을 수행하기를 원하며, 이를 지원하기 위해 concurrent 개념이 사용된다.
- 여러 네트워크 클라이언트 처리: Iterative server는 사실상 현실적이지 않은 서버이다. 이에 따라 concurrent 개념을 사용하여 각 클라이언트에 대해 별도의 control flow를 통해 처리할 수 있어야 한다.
- 멀티코어 머신에서의 병렬 계산: 요즘 최신 시스템은 여러 CPU로 구성된 멀티코어 프로세서를 사용한다. 여러 control flow를 활용하는 애플리케이션은 멀티코어 프로세서를 통해 더욱 빠르게 실행될 수 있는데, 이는 각각의 flow들이 교대로 실행되는 것이 아니라 병렬적으로 실행되기 때문이다.
애플리케이션 수준의 동시성을 사용하는 애플리케이션을 concurrent program이라고 하며, 현대의 OS는 이를 만들기 위해 세 가지 접근 방식을 기본적으로 제공한다:
- Process-based: 각각의 control flow를 커널이 스케쥴링하고 관리하는 하나의 프로세스로 다룬다.
- 이때 프로세스는 서로 다른 가상의 주소 공간을 가지므로, 서로 통신하기 위해서는 명시적인 프로세스 간 통신(IPC) 메커니즘을 사용해야 한다.
- Event-based: 애플리케이션이 하나의 프로세스 내에서 control flow들을 명시적으로 스케쥴링하는 방식이다.
- 이때 control flow는 FSM으로 모델링되며, 파일 디스크립터에서 데이터가 도착함에 따라 메인프로그램이 상태를 전이시키며, 이를 위해서 I/O multiplexing이라는 기술을 사용한다.
- 이 방식은 하나의 프로세스로 구성되어 있기 때문에 모든 flow들이 하나의 주소 공간을 공유한다.
- Thread-based: 해당 방식에서는 커널이 단일 프로세스 내에서 실행되는 thread들을 자동으로 관리한다.
- 이 방식은 process-based 방식과 같이 커널에 의해서 스케쥴링되면서, 동시에 event-based 방식과 같이 하나의 프로세스 내에서 같은 주소 공간을 공유한다는 점에서 하이브리드 방식이라고 볼 수 있다.
Iterative Servers

Iterative 서버(server)는 여러 클라이언트의 요청을 하나씩 순차적으로 처리하는 서버이다. 이러한 서버의 control flow는 figure 1에 잘 나타나있다. Figure 1은 다음과 같은 control flow를 설명하고 있다:
- Client 1이 서버에
connect()함수를 호출하여 연결을 요청하고, 서버가 이를accept()한다. - Client 1이
write()함수를 호출하여 데이터를 서버로 전송한다. - 서버가
read()함수를 통해 전송된 데이터를 읽고, 이를 처리하여write()함수를 통해서 client 1에게 데이터를 전송한다. - Client 1은 연결을
close()하고, 서버는 비로소 client 2의 연결 요청을accept()한다.
이를 client 2 입장에서 control flow를 다시 살펴보면, 다음과 같다:
connect(): 서버는 클라이언트의 연결 요청을 listen backlog 큐에 저장하고, 이에 따라connect()함수는 즉시 반환된다.- 클라이언트가
connect()함수를 호출했을 때, 클라이언트는 SYN 패킷을 서버로 보내고, 서버는 이에 대한 응답으로 ACK 패킷을 보낸다. - 클라이언트는 서버로부터 ACK 패킷을 받고, 최종 ACK 패킷을 다시 서버로 보내고 handshake를 완료한다.
- 이 상태에서 서버의 커널은 연결을 listen backlog 큐에 저장해두며, 서버가 나중에
accept()함수를 호출했을 때 해당 큐에서 연결을 하나 꺼내와서 처리한다. - 즉, 서버는 연결을 즉시 수락하지 않으며, 보류된 연결로서 큐에 저장한다. 다른 의미로 보면,
accept()함수는 이 큐에서 연결 하나를 꺼내는 함수이다.
- 클라이언트가
rio_writen(): 데이터를 클라이언트 TCP 소켓 버퍼에 작성하고, 커널이 이를 서버로 전송힌다.- 클라이언트의 I/O 동작은 서버의 상태와는 무관하게 동작하므로,[1] 해당 함수를 호출한 즉시 반환된다.
rio_readlineb(): 해당 함수는 서버가 연결을 실제로 accept() 하기 전까지 블로킹(blocking)된다.- 이는 서버가 아직 client 1과 통신 중이기 때문에 client 2의 요청을 아직 처리하지 않았기[2] 때문이다.
이러한 관점에서 볼 때, client 2는 매우 큰 불편함을 겪는다고 볼 수 있다. 또한 client 1이 서버와의 상호작용 도중 잠시 자리를 비운다면, 해당 서버는 그 동안 어떤 작업도 수행하지 않으므로 매우 큰 비효율성이 초래된다. 즉, 이에 대한 해결책이 필요하며, 그것이 바로 concurrent server이다.
Concurrent Programming with Processes
Concurrent 프로그래밍의 가장 단순한 방법은 fork(), exec(), waitpid()와 같은 함수들을 사용해 프로세스를 통해 구현하는 것이다. 예를 들어 concurrent 서버를 구축하는 방식 중 하나는 부모 프로세스에서 클라이언트의 연결 요청을 수락하고, 그 후에 각각의 클라이언트마다 새로운 자식 프로세스를 생성하여 서비스를 제공하는 것이다.
- Figure 2
-
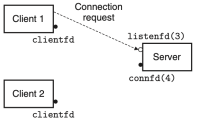 Figure 2. Server accepts connection
Figure 2. Server accepts connection -
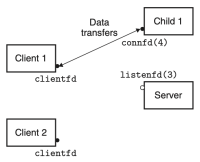 Figure 3. Server forks a child
Figure 3. Server forks a child -
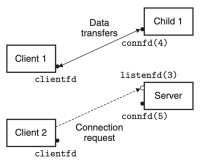 Figure 4. Server accepts another connection
Figure 4. Server accepts another connection -
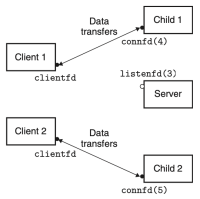 Figure 5. Server forks another child
Figure 5. Server forks another child




이 방식이 어떻게 작동하는지 살펴보기 위해, 두 개의 클라이언트와 하나의 서버가 있고, 서버가 listening 디스크립터(예: listenfd(3))을 통해 연결 요청을 기다린다고 가정하자. 클라이언트 1이 먼저 서버에게 연결 요청을 보낸다면, 서버는 해당 요청을 수락하고 connected 디스크립터(예: connfd(4))를 반환한다. 해당 요청을 수락한 후, 서버는 자식 프로세스를 fork()하고, 해당 자식 프로세스는 서버의 디스크립터 테이블의 전체 복사본을 가진다. 따라서 자식은 listenfd(3)를 닫고, 부모는 connfd(4)를 닫는다. 이때, 부모 자식의 connfd는 동일한 파일 테이블 항목을 가리키므로, 부모가 자신의 connfd를 반드시 닫아야 한다. 만약 그렇지 않다면, 해당 connfd의 파일 테이블 항목은 삭제되지 않고, 결과적으로 메모리 누수(memory leak)가 발생하여, 가용 메모리를 모두 소비하고 시스템이 다운될 수 있다.
부모가 클라이언트 1을 위해 자식을 생성한 이후, 클라이언트 2가 새로운 연결 요청을 보낸다고 하자. 그러면 서버는 연결 요청을 수락하고, connfd(5)를 반환한다. 이후 부모는 또 다른 자식 프로세스를 fork()하고, 이 자식 프로세스는 connfd(5)를 이용해 클라이언트 2에게 서비스를 제공한다. 이 시점에서, 부모는 다음 연결 요청을 기다리고 있으며, 두 자식은 각자의 클라이언트를 동시(concurrently)에 서비스하고 있다. 이 모든 과정들은 figure 2에 잘 나타나 있다.
Process-Based Concurrent Echo Server
아래는 process-based concurrent 서버의 간단한 예시를 보여준다. 이때 아래 코드에서 나온 echo() 함수는 Network Programming 문서에서 설명된 코드를 그대로 사용하였다:
#include "csapp.h"
void echo(int connfd);
void sigchld_handler(int sig)
{
while (waitpid(-1, 0, WNOHANG) > 0); //모든 좀비 프로세스를 수거한다.
return;
}
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
Signal(SIGCHLD, sigchld_handler); //SIGCHLD에 대한 시그널 핸들러 등록
listenfd = Open_listenfd(argv[1]); //argv[1]에 해당하는 포트 번호로 서버용 소켓을 열고 bind, listen
while (1) {
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen); ////클라이언트가 연결 요청을 보내면 수락, connfd 생성
if (Fork() == 0) {
Close(listenfd); //자식 프로세스는 listeing 디스크립터가 필요없으므로 닫는다.
echo(connfd); //echo() 함수를 통해 서버와 통신한다.
Close(connfd); //해당 connfd를 다 썼으므로 닫는다.
exit(0);
}
Close(connfd); //서버는 해당 connfd가 필요없으므로 닫는다.
}
}
위 코드를 기반으로하는 서버는 몇가지 주의 사항을 가진다. 먼저 서버는 일반적으로 장기간 실행되므로, 좀비 프로세스를 수거하는 SIGCHLD 핸들러를 반드시 포함하여야 한다. 이때 리눅스의 시그널을 큐잉되지 않으므로, SIGCHLD 핸들러는 여러 좀비 프로세스들을 한번에 수거할 수 있어야 한다. 그리고, 부모와 자식은 각자의 connfd 복사본을 반드시 닫아야 한다. 특히 부모가 자신의 connfd 복사본을 닫지 않으면 메모리 누수가 생길 수 있다. 마지막으로, 소켓의 파일 테이블 내의 reference count 때문에, 부모 자식 모두의 connfd 복사본이 닫힐 때까지 클라이언트와의 연결은 종료되지 않는다.
Process-based Server Execution Model
Process-based 방식은 부모 프로레스와 자식 프로세스 사이에서 명확하게 정의되는 공유 모델을 가지고 있다. 파일 테이블은 공유하지만, 파일 디스크립터와 전역 변수들은 서로 공유하지 않는다. 이는 간단하고 직관적이므로 장점이라고 볼 수 있다. 또한 프로세스 마다 주소 공간이 분리되어 있다는 특징을 가지고 있는데, 이는 장점이자 단점이다. 이는 하나의 프로세스가 실수로 다른 프로세스의 가상 메모리를 덮어쓰는 것이 불가능하게 만들며, 이는 여러 오류들을 없애 준다. 하지만 주소 공간이 분리되어 있으므로, 프로세스 사이에서의 정보 공유가 더욱 어려워지며 서로 정보를 공유하기 위해서는 명시적인 IPC(interprocess communications) 메커니즘을 사용해야 한다. 또 다른 단점은, 프로세스 제어와 IPC에 추가적인 오버헤드가 발생하여 속도가 느려지는 경향이 있다는 것이다.