[[파일:The heap.png|섬네일|233x233픽셀|Figure 1. The heap]]
프로그래머들은 가상 메모리(virtual memory)를 습득하고 사용해야 할때, malloc() 함수와 같은 동적 메모리 할당기(dynamic memory allocator)를 사용한다. 동적 메모리 할당기는 프로세스의 가상 메모리 내에 있는 (heap)이라고 불리는 영역을 관리한다. 이때 각 프로세스마다 커널은 힙의 맨위를 가리키는 brk라고 하는 변수를 유지한다. Figure 1은 가상 메모리를 시각적으로 보여준다.
동적 메모리 할당기는 힙을 크기가 다양한 블록 들의 집합으로 유지한다. 이때 각 블록은 연속적인 가상 메모리 조각이며, 할당되었거나(allocated) 비어있다(free). 할당된 블록은 애플리케이션에 의해 명시적으로 사용하기 위해 예약된 블록이다. 또한 비어 있는 블록(free block)은 할당이 가능한 상태이며, 애플리케이션에 의해 명시적으로 할당될 때까지는 계속 비어 있는 상태로 남는다. 할당된 블록은 애플리케이션이 명시적으로 free 하거나, 메모리 할당기 자체가 암묵적으로 해제할 때까지는 계속 할당된 상태이다.
동적 메모리 할당기는 두 가지의 기본적인 스타일로 나뉜다. 이때 두 스타일 모두 애플리케이션이 명시적으로 블록을 할당해야 한다는 점은 공통되며, 할당된 블록을 누가 해제하는지에 따라 차이가 있다:
* 명시적 할당기(explicit allocators): 애플리케이션이 할당한 블록을 명시적으로 해제해야 한다.
** 예를 들어, C 표준 라이브러리의 malloc 패키지가 이에 해당한다. C 프로그램은 <code>malloc()</code> 함수를 호출해 블록을 할당하고, <code>free()</code> 함수를 호출해 블록을 해제한다. C++의 new와 delete 호출도 이와 유사하다.
* 암시적 할당기(implicit allocators): 애플리케이션이 더 이상 할당된 블록을 사용하지 않게 되었음을 할당기가 감지해서 자동으로 해제한다.
** 암시적 할당기는 가비지 컬렉터(garbage collectors)라고도 불리며, 사용되지 않는 할당된 블록을 자동으로 해제하는 과정을 가비지 컬렉션(garbage collection)이라고 한다.
** 예를 들어, Lisp, ML, Java 같은 고급 언어들은 가비지 컬렉션에 의존해서 할당된 블록을 해제한다.
하지만, 해당 문서에서는 명시적 할당기의 설계와 구현에 대해 논의한다. 또한 앞으로 word 사이즈는 int를 기준으로 하고, 바이트가 아닌, 워드 단위로 주소를 사용한다고 가정한다.
==The malloc and free Functions==
C 표준 라이브러리는 malloc 패키지로 알려진 명시적 할당기를 제공한다. 프로그램은 malloc 함수를 호출하여 힙에서 블록을 할당한다:
<code>malloc()</code> 함수는 size 바이트 크기의 메모리 블록을 반환하며, 해당 블록에 포함될 수 있는 데이터 객체가 적절하게 정렬(alignment)되도록 한다. 실제로 이 정렬 방식은 코드가 32비트 모드(gcc -m32)로 컴파일되었는지 64비트 모드로 컴파일 되었는지에 따라 달라진다. 32비트 모드에서는, malloc이 반환하는 블록의 주소는 항상 8의 배수이고, 64비트 모드에서는, 그 주소가 항상 16의 배수이다(바이트 기준).
만약 초기화된 동적 메모리가 필요한 경우, 프로그램은 <code>calloc()</code> 함수를 사용할 수 있으며, <code>calloc()</code> 함수는 내부적으로 malloc을 호출하고 할당된 메모리를 0으로 초기화한다. 이미 할당된 블록의 크기를 변경하고 싶은 경우에는, <code>realloc()</code> 함수를 사용하면 된다. malloc을 통해 동적으로 할당된 공간을 해제하고자 할때는, free() 함수를 이용하면 된다:
<syntaxhighlight lang="c">
#include <stdlib.h>
void free(void *ptr); //반환값 없음
</syntaxhighlight>
[[파일:Allocating and freeing blocks with malloc and free.png|섬네일|Figure 2. Allocating and freeing blocks with malloc and free]]
이때 ptr 인자는 malloc, calloc, 또는 realloc을 통해 할당된 블록의 시작 주소를 가리켜야 한다. 그렇지 않은 경우, free의 동작은 정의되지 않는다(undefined behavior). Figure 2는 malloc과 free가 어떻게 작은 힙을 관리할 수 있는지를 보여준다. 이때 각 상자는 4바이트 워드를 나타내며, 따라서 해당 시스템은 32비트 시스템이다. 초기에는 힙이 더블 워드(8바이트) 정렬되어 있는 빈 메모리 공간이다:
# Figure 2(a)에서는 프로그램이 4워드 블록을 요청한다. malloc은 비어 있는 블록의 앞쪽에서 4워드를 잘라 새 블록으로 만들고, 그 첫 번째 워드의 주소를 반환한다.
# Figure 2(b)에서는 프로그램이 5워드 블록을 요청한다. 정렬을 유지하기 위해 malloc은 앞쪽에서 6워드 블록을 할당해준다.
# Figure 2(c)에서는 프로그램이 6워드 블록을 요청하고, malloc은 비어 있는 블록에서 6워드를 잘라서 할당한다.
# Figure 2(d)에서는 프로그램이 (b)에서 할당된 6워드 블록을 해제한다. free 호출이 끝난 후에도, 포인터 p2는 여전히 해제된 블록을 가리킨다.
#* 포인터 p2를 사용하지 않는 것은 애플리케이션에게 달려있다.
# Figure 2(e)에서는 프로그램이 2워드 블록을 요청한다. malloc은 이전 단계에서 해제된 블록 중 일부를 재사용하여 새 블록을 할당하고, 해당 주소를 반환한다.
==Allocator Requirements and Goals==
===Allocator Requirements===
명시적 할당기(explicit allocator)는 몇 가지 매우 엄격한 제약 조건 내에서 동작해야 한다:
# 임의의 요청 시퀀스를 처리해야 한다.
#* 애플리케이션은 임의의 할당 및 해제 요청 시퀀스를 만들 수 있으며, 단 각 해제 요청은 이전의 할당 요청으로부터 얻은 현재 할당된 블록에 해당해야 한다는 제약을 가진다. 따라서, 할당기는 할당과 해제 요청의 순서에 대해 어떤 가정도 할 수 없다.
# 할당기는 할당 요청에 즉시 응답해야 한다.
#* 즉, 성능 향상을 위해 요청을 재정렬하거나 버퍼링하는 것은 허용되지 않는다.
# 할당기가 확장 가능(scalable)하려면, 할당기에서 사용하는 모든 비스칼라(nonscalar) 자료구조는 힙 내에 저장되어야 한다.
# 할당기는 블록을 어떤 타입의 데이터 객체든 담을 수 있도록 정렬해서 제공해야 한다.
# 할당기는 비어 있는(free) 블록만 조작하거나 변경할 수 있으며, 한 번 할당된 블록은 수정하거나 이동할 수 없다.
===Allocator Goals===
이러한 제약 조건 안에서, 할당기 설계자는 성능 목표들, 즉 처리량(throughput)과 메모리 활용률(utilization)을 달성해야 한다. 하지만 이 둘은 종종 상충하는 목표이다.
어떤 길이 n을 가지는 할당 및 해제 요청 시퀀스 R<sub>0</sub>, R<sub>1</sub>, ..., R<sub>k</sub>, ..., R<sub>n-1</sub>이 주어졌을 때, 할당기의 처리량을 최대화해야 한다. 이때 처리량은 단위 시간당 처리한 요청 수로 정의된다. 예를 들어, 어떤 할당기가 1초 동안 malloc 500회, free 500회를 처리했다면, 그 처리량은 초당 1,000개의 연산이다. 일반적으로, 처리량을 높이기 위해서는 할당 및 해제 요청을 처리하는 평균 시간을 최소화해야 한다.
힙을 얼마나 효율적으로 사용하는지 측정하는 방법은 여러 가지가 있지만, 가장 유용한 척도는 최고 활용률(peak utilization)이다. 앞과 같이 할당 및 해제 요청 시퀀스 R<sub>0</sub>, R<sub>1</sub>, ..., R<sub>k</sub>, ..., R<sub>n-1</sub>이 주어졌다고 하자. 이때 애플리케이션이 p 바이트 크기의 블록을 요청했다면, 그 결과 할당된 블록에서 p 바이트는 payload에 해당한다. 요청 R<sub>k</sub>까지 완료된 후, 현재 할당된 모든 블록의 payload 총합을 P<sub>k</sub>라고 하고, 힙의 현재 크기를 H<sub>k</sub>라고 하자. 이 경우 그러면, 첫 k+1개 요청에 대한 최고 활용률 U<sub>k</sub>는 다음과 같이 정의된다:
힙 활용률이 낮은 주요한 원인은 단편화(fragmentation)이라고 알려진 현상 때문이다. 단편화는 실제로 사용되지 않는 메모리가 존재함에도 불구하고 할당 요청을 만족시킬 수 없는 상황에서 발생한다. 이때 단편화에는 두 가지 형태가 있다:
* 내부 단편화(internal fragmentation)
* 외부 단편화(external fragmentation)
===Internal Fragmentation===
내부 단편화는 할당된 블록의 크기가 그 payload보다 큰 경우 발생한다. 이러한 현상은 여러 이유로 인해 발생할 수 있다. 예를 들어:
* 동적 메모리 할당기가 요청된 payload보다 큰 최소 블록 크기를 강제하도록 강제하였다.
* 동적 매모리 할당기가 정렬 조건을 만족시키기 위해 블록 크기를 늘릴 수도 있다.
이때 어떤 시점에서의 내부 단편화로 인한 낭비되는 메모리의 양은 이전 요청의 패턴과 할당기 구현 방식에만 의존하므로 정량화(quantify)가 간단하다. 이는 할당된 각 블록의 크기와 그 payload의 차이를 모두 합한 것이다.
===External Fragmentation===
외부 단편화는 전체 비어 있는 메모리 총량은 충분하지만, 어떤 단일한 free 블록도 요청된 크기를 만족시킬 만큼 크지 않은 경우에 발생한다. 예를 들어, figure 2에서 (e)의 요청이 2워드가 아니라 8워드였다면, 힙에는 총 8워드의 free 메모리가 있지만, 두 개의 작은 free 블록으로 나뉘어 있기 때문에 요청을 만족시킬 수 없다. 이 문제는, 그 8워드가 서로 다른 두 블록에 분산되어 있기 때문에 발생한다. 따라서 외부 단편화는 내부 단편화보다 훨씬 정량화하기 어려운데, 이는 이전 요청 패턴, 할당기 구현, 미래 요청 패턴 모두에 의존하기 때문이다. 예를 들어, k번의 요청 이후 모든 free 블록이 정확히 4워드 크기라고 가정하면, 해당 힙이 외부 단편화를 겪고 있는가에 대한 질문의 답은 미래 요청 패턴에 따라 달라진다. 만약 앞으로의 모든 요청이 4워드 이하라면, 외부 단편화는 없다. 하지만 하나라도 4워드 초과 요청이 발생한다면, 힙은 외부 단편화를 겪고 있다고 할 수 있다.
===Implementation Issues===
가장 단순하게 상상할 수 있는 할당기는, 힙을 바이트 배열로 구성하고, 포인터 p를 사용해 그 배열의 첫 번째 바이트를 가리키도록 하는 것이다:
# malloc이 size 바이트를 할당할 때, 현재 p의 값을 스택에 저장하고,
# p를 size만큼 증가시킨 다음,
# 이전의 p 값을 호출자에게 반환한다.
# free는 단순히 아무 작업도 하지 않고 호출자에게 복귀한다.
하지만 이는 단순히 너무 naive하다. 각 malloc과 free가 몇 개의 명령어만 실행하기 때문에, 처리량은 매우 우수할지 몰라도, 블록을 전혀 재사용하지 않기 때문에, 메모리 활용률(memory utilization)은 매우 나쁘다. 현실적인 할당기는 처리량과 메모리 활용률 사이의 더 나은 균형을 추구해야 하며, 다음과 같은 문제들을 고려해야 한다:
* Free block 조직 (Free block organization): 비어 있는 블록들을 어떻게 추적할 것인가?
* 배치 (Placement): 새롭게 할당할 블록을 어떤 free 블록에 배치할 것인가?
* 분할 (Splitting): 어떤 free 블록에 새로 할당된 블록을 배치한 후, 남는 공간은 어떻게 처리할 것인가?
* 병합 (Coalescing): 방금 해제된 블록은 어떻게 처리할 것인가? 인접한 free 블록들과 합칠 것인가?
==Implicit Free Lists==
[[파일:Format of a simple heap block.png|섬네일|400x400픽셀|Figure 3. Format of a simple heap block]]
모든 실용적인 할당기는 블록 경계를 구분하고 할당된 블록과 비어 있는 블록을 구분할 수 있도록 하는 자료구조를 필요로 한다. 이때 대부분의 할당기는 이 정보를 블록 내부에 직접 포함시킨다. Figure 3은 이에 대한 한 간단한 접근 방식이다. 이 경우 하나의 블록은 다음과 같은 구성으로 이루어진다:
* 1워드짜리 헤더(header)
* 헤더는 블록의 전체 크기(헤더 포함)와, 해당 블록이 할당되어있는지의 여부를 나타낸다.
* payload(추가적인 padding이 있을 수 있음)
만약 더블 워드 정렬(double-word alignment) 조건을 강제한다면, 블록 크기는 항상 8의 배수가 되고, 따라서 블록 크기의 하위 3비트는 항상 0이다. 이 경우, 우리는 상위 29비트에 블록 크기 정보를 저장하고, 남은 하위 3비트 중 일부를 다른 정보(예: 할당 여부)에 사용할 수 있다. 예를 들어, 24바이트 크기(0x18)의 할당된 블록이 있다면, 헤더는 (0x00000018 | 0x1) = 0x00000019와 같이 구성된다. 헤더 뒤에는 malloc 호출 시 애플리케이션이 요청한 payload가 따라오며, 그 뒤에는 padding이 올 수 있다. 이러한 padding은 외부 단편화를 완화하기 위해서 혹은 정렬 조건을 만족시키기 위해 사용될 수도 있다.
[[파일:Organizing the heap with an implicit free list.png|가운데|섬네일|500x500픽셀|Figure 4. Organizing the heap with an implicit free list]]
Figure 3를 바탕으로 하는 블록의 형식을 기준으로, 힙을 figure 4와 같이 할당 블록과 비어 있는 블록의 시퀀스로 구성할 수 있다. 이러한 구성을 implicit free list라고 부르는데, free 블록들이 헤더의 size 필드를 통해 암시적으로 연결되어 있기 때문이다. 따라서 할당기는 힙 내의 모든 블록을 순회함으로써, 간접적으로 모든 free 블록들을 탐색할 수 있다. 이때 특별히 표시된 종료 블록(end block)이 필요하다. 이 예에서는, 할당 비트가 설정되고 크기가 0인 헤더가 끝을 나타낸다.
이때 중요한 점은, 시스템의 정렬 요구 사항과 할당기가 선택한 블록 형식이 동적 메모리 할당기에서 허용할 수 있는 최소 블록 크기를 결정한다는 것이다.즉, 어떤 블록도 이 최소 크기보다 작을 수 없다. 예를 들어, 더블 워드 정렬을 만족해야 한다면, 각 블록의 크기는 반드시 2워드(8바이트)의 배수여야 한다. figure 3를 기준으로는 최소 블록 크기는 2워드이며, 하나는 헤더용으로, 다른 하나는 정렬 조건을 유지하기 위한 용도이다. 즉 애플리케이션이 1바이트만 요청하더라도, 할당기는 2워드짜리 블록을 생성한다.
===Implicit List: Finding a Free Block===
Implicit free list의 장점은 매우 단순하다는 것이다. 하지만 free 리스트를 탐색하는 연산을 수행할 때 힙 내 모든 할당/비어 있는 블록 수에 대해 선형 시간(linear time)이 걸린다는 단점이 있다. 이때, implicit free list에서 free 블록을 탐색하는 배치 정책(placement)에는 3가지 방식이 있다.
첫번째 방식은 처음부터 순차적으로 탐색하여, 처음으로 맞는(fit) 빈 블록을 사용하는 first fit방식이다. 이는 아래와 같은 코드를 사용한다.
<syntaxhighlight lang="c">
p = start;
while ((p < end) && // 끝까지 가지 않았고
((*p & 1) || // *p & 1 : 이 비트가 1이면 할당된 블록
(*p <= len))) // *p & -2 : 블록의 실제 크기 (하위 1비트 제거 → alignment 맞추기)
p = p + (*p & -2); // 다음 블록으로 이동 (정렬 비트 제거)
</syntaxhighlight>
이 방식의 장점은 리스트 끝 부분에 큰 free 블록을 보존하는 경향이 있다는 것이다. 하지만 리스트 앞 부분에 작은 free 블록 조각(splinter)가 생기기 쉽다는 단점도 존재한다.
또다른 방식으로는 next fit 방식이 있는데, 이는 first fit과 비슷하지만, 이전 탐색이 끝난 지점부터 다시 시작하는 방식이다. 이는 앞쪽에 이미 안 맞는 블록을 다시 확인하지 않는다는 장점이 존재하지만, 일부 연구에서는 단편화(fragmentation)를 조장한다는 단점이 있다.
마지막으로 best fit이라는 방식도 있는데, 이는 전체 리스트를 끝까지 탐색해, 가장 딱 맞는 블록을 선택하는 방식이다. 이는 작은 free 블록 조각을 감소시켜 메모리 활용도가 증가한다는 장점이 있지만, 탐색 비용이 크다는 단점이 있다. 힙 전체를 탐색하지 않고도 best-fit 정책을 근사적으로 구현하기 위해서는 구분된 free 리스트(segregrated free list) 방식을 사용해야 한다.
==Splitting Free Blocks==
할당기가 요청에 맞는 free 블록을 찾고 나면, 그 후에는 그 free 블록 중 얼마나 할당할지에 대한 결정을 내려야 한다. 한 가지 선택지는 free 블록 전체를 사용하는 것이다. 이는 단순하고 빠르지만 내부 단편화(internal fragmentation)를 초래할 수 있다는 단점이 있다. 만약 배치 정책이 best fit과 같이 요청한 크기에 거의 딱 맞는 free 블록을 자주 찾아낸다면 어느 정도의 내부 단편화는 감수할 수 있다.
[[파일:Splitting a free block to satisfy a three-word allocation request.png|가운데|섬네일|500x500픽셀|Figure 5. Splitting a free block to satisfy a three-word allocation request]]
하지만 그렇지 않은 경우, 동적 메모리 할당기는 free 블록을 두 부분으로 분할한다. 첫 번째 부분은 할당된 블록이 되고, 나머지 부분은 새로운 free 블록이 된다. Figure 5는 Figure 3의 8워드짜리 free 블록을 어떻게 분할하는지에 대해 보여준다.
==Coalescing Free Blocks==
할당기가 할당된 블록을 해제(free)할 때, 그 새롭게 해제된 블록의 인접한 위치에 다른 free 블록이 존재할 수 있다. 이러한 인접한 free 블록들은 가짜 단편화(false fragmentation)라고 불리는 현상을 유발할 수 있다. 즉, 사용 가능한 free 메모리가 작고 쓸모없는 조각들로 쪼개져 있어서 실제로는 충분한 양의 메모리가 있음에도 불구하고, 요청을 만족시키지 못하는 상황이 발생하는 것이다.
[[파일:An example of false fragmentation.png|가운데|섬네일|500x500픽셀|Figure 6. An example of false fragmentation]]
Figure 6는 figure 5에서 할당된 블록을 해제한 후의 결과를 보여준다. 결과적으로, payload가 각각 3워드인 인접한 두 개의 free 블록이 생긴다. 이 경우, 만약 어떤 요청이 4워드 payload를 요구한다면, 전체 free 블록 크기는 충분하지만, 연속된 하나의 블록이 아니기 때문에 할당에 실패하게 된다. 이러한 false fragmentation을 방지하기 위해, 실용적인 동적 메모리 할당기라면 반드시 인접한 free 블록들을 병합(coalescing)해야 한다.
이때 병합을 언제 수행할 지는 매우 중요한 질문이다. 할당기는 다음 중 하나를 선택할 수 있다:
* 즉시 병합(immediate coalescing): 블록이 해제될 때마다 인접한 free 블록이 있다면 바로 병합한다.
* 지연 병합(deferred coalescing): 병합을 나중 시점까지 미루고, 특정 조건이 충족될 때 한꺼번에 수행한다.
** 예: 할당 요청이 실패했을 때 힙 전체를 스캔하여 모든 free 블록을 병합하는 방식이다.
즉시 병합은 구현이 단순하고, 상수 시간 내에 수행할 수 있다. 하지만 어떤 요청 패턴에서는 thrashing이라 불리는 비효율이 생길 수 있다. 예를 들면 어떤 블록이 해제되어 병합된 직후, 다시 할당되면서 다시 분할되는 일이 반복되는 경우이다. 해당 문서에서는 즉시 병합(immediate coalescing)을 전제로 하지만, 현실에서는 지연 병합(deferred coalescing)을 선택하는 경우가 많다.
===Coalescing with Boundary Tags===
우리가 해제하려는 블록을 현재 블록(current block)이라고 하자. 그러면 현재 블록의 다음 블록(next block)을 병합하는 것은 직관적이고 효율적이다. 현재 블록의 헤더는 다음 블록의 헤더를 가리키므로, 그 헤더를 검사해 다음 블록이 free인지 여부를 확인할 수 있다. 만약 다음 블록이 free라면, 그 크기를 현재 블록의 크기에 더하면 되고, 이를 통해 상수 시간 내에 병합할 수 있다.
하지만 이전 블록(previous block)을 병합은 더욱 까다롭다. 암시적 free 리스트에서는 각 블록에 헤더만 있으므로, 현재 블록에 도달할 때까지 리스트 전체를 순차적으로 탐색하며 이전 블록의 위치를 기억해야 한다. 즉, 암시적 free 리스트에서 free를 호출할 때, 필요한 시간은 힙 크기에 대해 선형 시간(linear time)이 된다.
[[파일:Format of heap block that uses a boundary tag.png|섬네일|200x200픽셀|Figure 7. Format of heap block that uses a boundary tag]]
이러한 문제를 해결하기 위해서 도입된 기법이 경계 태그(boundary tags)이며, 이는 이전 블록과의 병합을 상수 시간에 수행할 수 있게 해준다. 해당 방식의 핵심적인 아이디어는 figure 7과 같이 각 블록의 끝 부분에 header의 복사본인 footer(경계 태그)를 추가하는 것이다. 이렇게 하면, 현재 블록 기준으로 한 워드 앞에 있는 footer를 확인하여 이전 블록의 시작 위치 및 상태(할당/비어있음)를 알 수 있다.
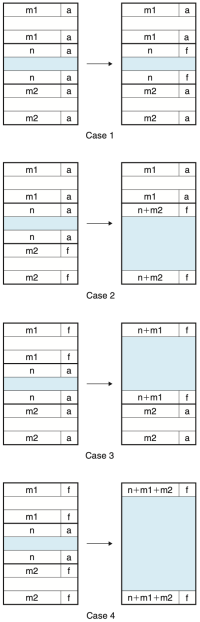
할당기가 어떤 블록을 해제할 때, 발생 가능한 경우의 수는 다음 네 가지이다:
# 이전 블록과 다음 블록이 모두 할당됨
# [[파일:Coalescing with boundary tags.png|섬네일|622x622픽셀|Figure 8. Coalescing with boundary tags]]이전 블록은 할당됨, 다음 블록은 free
# 이전 블록은 free, 다음 블록은 할당됨
# 이전 블록과 다음 블록이 모두 free
Figure 8은 이 네 가지 경우 각각에서 어떻게 병합이 수행되는지 보여준다.
* Case 1: 양쪽 블록이 모두 할당됨 → 병합 불가
** 따라서, 현재 블록의 상태만 allocated → free로 변경
* Case2: 현재 블록과 다음 블록을 병합
** 현재 블록의 헤더와 다음 블록의 footer를 합쳐진 크기로 업데이트
* Case3: 이전 블록과 현재 블록을 병합
** 이전 블록의 헤더와 현재 블록의 footer를 합쳐진 크기로 업데이트
* Case4: 이전, 현재, 다음 블록 모두 병합
** 이전 블록의 헤더와 다음 블록의 footer를 세 블록 크기의 합으로 업데이트
이 모든 경우에서 병합은 상수 시간에 수행된다.
경계 태그 기법은 단순하고 우아하며, 다양한 형태의 할당기와 free 리스트 조직에 일반적으로 적용 가능하다. 하지만 각 블록에 header와 footer를 모두 넣어야 하므로, 작은 블록을 많이 사용하는 애플리케이션에서는 메모리 오버헤드가 커질 수 있다는 단점이 있다. 이러한 단점을 극복하기 위해, 할당된 블록에는 footer를 생략할 수 있는 최적화 기법이 존재한다. 따라서, 현재 블록의 low-order bit 중 여분 비트 하나에 이전 블록의 할당 여부 비트를 저장하면, 할당된 블록에서는 footer 없이도 이전 블록 상태를 추론할 수 있다.
==Explicit Free Lists==
[[파일:Format of heap blocks that use doubly linked free lists.png|대체글=Figure 9. Format of heap blocks that use doubly linked free lists|가운데|섬네일|Figure 9. Format of heap blocks that use doubly linked free lists]]
Implicit free list는 힙에 존재하는 전체 블록 수에 대해 선형 시간(linear)이 걸리기 때문에, 범용 할당기(general-purpose allocator)로는 적합하지 않다. 더 나은 접근법은, free 블록들을 어떤 형태의 명시적(explicit) 데이터 구조로 조직하는 것이다. 정의상, free 블록의 내부(body)는 프로그램에서 사용되지 않으므로, 포인터들을 그 내부에 저장할 수 있다. 예를 들어, 힙을 이중 연결 리스트(doubly linked list)로 구성할 수 있다. 이는 figure 9에 잘 나타나 있다.
암시적 프리 리스트 대신 이중 연결 리스트를 사용하면, first-fit 할당 시간이 전체 블록 수에 대해 선형이던 것이 free 블록 수에 대해 선형 시간으로 감소한다. 또한 이를 활용한 다른 한 가지 방법은 free 리스트를 LIFO(후입선출) 순서로 유지하는 것이다. 즉, 새로 해제된 블록을 리스트의 맨 앞에 삽입한다. 이 경우 LIFO 순서 + first-fit 배치 정책을 함께 쓰면 할당기는 최근에 사용되었던 블록부터 검사한다. 따라서 free 연산은 상수 시간에 수행 가능하다. 또한 boundary tag를 사용하면, 병합(coalescing)도 상수 시간에 수행 가능하다.
다른 방식은 free 리스트를 주소 순서로 유지하는 것이다. 즉, 리스트 내에서 각 블록의 주소는 그 다음 블록의 주소보다 작다. 하지만 이 방식의 장점은 해당 방식의 first-fit이 LIFO 순서의 first-fit보다 메모리 활용률이 더 좋다는 점이다. 하지만 이는 블록을 해제할 때, 적절한 선행 블록(predecessor)을 찾기 위한 선형 탐색이 필요하다는 단점이 있다.
==Segregated Free Lists==
[[파일:Each size class of blocks has its own free list.png|섬네일|Figure 10. Each ''size class'' of blocks has its own free list ]]
Segregated Free List는 각기 다른 크기의 블록들을 별도의 리스트(free list)에 저장하는 방식이다. 이를 size class라고 부르며 figure 10에 잘 나타나 있다. 이때 작은 크기일수록 더 정밀하게 클래스 구분을 하며, 큰 크기일수록 두 배 단위(power-of-two)로 묶어 관리(예: 16–31, 32–63 등)한다.
해당 방식에서는 <code>malloc(n)</code> 요청 시 크기 n보다 크거나 같은 클래스(m > n)을 찾는다. 해당 클래스에 대해 적절한 free 블록이 있으면 해당 블록을 사용한다. 이때 해당 블록을 쓰고 공간이 남으면 이를 split하여 남은 부분을 다른 free list로 보낼 수 있다. 만약 해당 클래스에 적절한 free 블록이 없다면, 다음으로 큰 사이즈의 클래스로 이동해 이를 반복한다. 만약 그래도 없다면, <code>sbrk()</code>로 OS에서 새로운 힙 메모리를 요청한다. 그리고 필요한 만큼 할당하고, 나머지는 가장 큰 클래스에 free 함수를 통해 넣는다.
블록을 해제할 때는 해제된 블록을 인접 블록과 병합(coalescing)한 뒤, 병합된 블록의 사이즈에 해당하는 클래스의 free list에 넣으면 된다.
이 방식의 장점은 로그 시간에 탐색 연산이 가능하므로, 처리량이 높게 뽑힌다는 점이다. 또한 메모리 활용이 높은데, 이는 해당 방식의 first-fit 탐색이 best-fit과 유사한 성능을 제공하기 때문이다. 만약 모든 크기에 대해 별도의 클래스를 제공한다면, best-fit과 일치하는 성능을 제공한다.
==[[Garbage Collection]]==
자세한 내용은 [[Garbage Collection]] 문서를 참조하십시오.
==Common Memory-Related Bugs in C Programs==
가상 메모리를 관리하고 사용하는 일은 C 프로그래머에게 어렵고 실수가 잦은 작업이다. 메모리 관련 버그는 특히 두려운 종류인데, 그 이유는 버그의 원인과 증상이 시간적으로나 공간적으로 멀리 떨어져서 나타나기 때문이다. 메모리 관련 버그는 특히 두려운 종류인데, 그 이유는 버그의 원인과 증상이 시간적으로나 공간적으로 멀리 떨어져서 나타나기 때문이다.
===Dereferencing Bad Pointers===
프로세스의 가상 주소 공간에는 의미 있는 데이터로 매핑되지 않은 큰 구멍(hole)들이 존재한다. 만약 우리가 이런 구멍 중 하나를 가리키는 포인터를 역참조하려 한다면, 운영체제는 프로그램을 segmentation exception로 종료시킨다. 또한, 가상 메모리 중 일부 영역은 읽기 전용(read-only)일 수 있다. 이런 영역에 쓰기를 시도하면, 프로그램은 protection exception로 종료된다.
잘못된 포인터 역참조의 대표적인 예시는 scanf 버그이다. 예를 들어, 우리가 scanf를 사용하여
stdin으로부터 정수를 읽어와 변수에 저장하고자 한다면, 올바른 방법은 다음과 같이 scanf에 서식 문자열과 변수의 주소를 전달하는 것이다:
<syntaxhighlight lang="c">
scanf("%d", &val);
</syntaxhighlight>
하지만, 아래와 같이 실수로 변수 val의 값 자체를 전달할 수 있다:
<syntaxhighlight lang="c">
scanf("%d", val); // 잘못된 예
</syntaxhighlight>
이 경우, scanf는 val의 내용을 주소로 해석해서 그 주소에 정수 값을 쓰려고 시도한다. 운이 좋다면 그 주소가 존재하지 않는 가상 메모리 주소이며, 프로그램은 즉시 예외와 함께 종료된다. 하지만 운이 나쁘다면 val의 내용이 정상적인 읽기/쓰기 메모리 영역의 주소일 수 있고, 그 결과, scanf는 해당 메모리를 덮어쓰게 된다. 이 경우 프로그램은 그 순간에는 멀쩡히 실행되지만, 훨씬 나중에 알 수 없는 방식으로 심각한 오류를 발생시킨다.
===Reading Uninitialized Memory===
bss 메모리 영역(예: 초기화되지 않은 전역 C 변수)은 로더(loader)에 의해 항상 0으로 초기화된다. 하지만 힙(heap) 메모리는 자동으로 0으로 초기화되지 않는다. 하지만 실수로 힙 메모리도 0으로 초기화되어 있다고 가정한다면 오류가 발생한다. 아래는 그 예시이다:
<syntaxhighlight lang="c">
/* Return y = Ax */
int *matvec(int **A, int *x, int n) {
int i, j;
int *y = (int *)Malloc(n * sizeof(int));
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
y[i] += A[i][j] * x[j];
return y;
}
</syntaxhighlight>
이 예제에서, 프로그래머는 벡터 y가 0으로 초기화되어 있다고 잘못 가정하고 있다. 하지만 Malloc은 초기화를 하지 않기 때문에, y[i]는 garbage를 가지고, 그 상태에서 += 연산을 하므로 결과가 의도한 대로 나오지 않는다. 이 코드를 올바르게 구현하려면, y[i]를 명시적으로 0으로 초기화하거나, 또는 calloc을 사용해야 한다:
<syntaxhighlight lang="c">
int *y = (int *)Calloc(n, sizeof(int)); // calloc은 자동으로 0으로 초기화함
</syntaxhighlight>
===Allowing Stack Buffer Overflows===
프로그램이 입력 문자열의 크기를 확인하지 않고 스택에 있는 대상 버퍼에 데이터를 쓸 때, 이는 buffer overflow 버그이다. 예를 들어, 다음 함수는 버퍼 오버플로우 버그를 가지고 있다. 그 이유는 gets 함수가 길이에 제한 없이 문자열을 복사하기 때문이다:
<syntaxhighlight lang="c">
void bufoverflow() {
char buf[64];
gets(buf); /* 여기에서 스택 버퍼 오버플로우 발생 */
return;
}
</syntaxhighlight>
이 문제를 해결하려면, 입력 문자열의 크기를 제한하는 fgets() 함수를 사용해야 한다.
===Allocating the (possibly) wrong sized object===
이 오류는 프로그래머가 동적으로 할당한 배열의 크기를 헷갈려할 때 발생한다. 이는 아래와 같다:
<syntaxhighlight lang="c">
void error_code() {
int **p;
p = malloc(N*sizeof(int));
for (i=0; i<N; i++) {
p[i] = malloc(M*sizeof(int));
}
}
</syntaxhighlight>
===Making Off-by-One Errors===
Off-by-one 오류(한 칸 차이 오류)는 메모리 덮어쓰기(overwriting) 버그의 또 다른 흔한 원인이다:
<syntaxhighlight lang="c">
/* Create an nxm array */
int **makeArray2(int n, int m) {
int i;
int **A = (int **)Malloc(n * sizeof(int *)); // ← n개의 포인터를 위한 배열 생성
for (i = 0; i <= n; i++) // ← 문제 발생 지점: i <= n
A[i] = (int *)Malloc(m * sizeof(int));
return A;
}
</syntaxhighlight>
5번째 줄에서, n개의 포인터를 저장할 수 있는 배열을 생성했는데 7~8번째 줄에서는 n + 1개의 요소를 초기화하려고 시도하고 있다. 그 결과, A 배열 다음에 위치한 다른 메모리를 덮어쓰게 된다. 이는 전형적인 off-by-one 오류이며, 메모리 손상이나 프로그램의 예기치 않은 동작을 유발할 수 있다.
===Misunderstanding Pointer Arithmetic===
또 하나의 흔한 실수는, 포인터에 대한 산술 연산이 바이트 단위가 아니라, 해당 포인터가 가리키는 객체의 크기 단위로 수행된다는 사실을 잊는 것이다. 예를 들어, 다음 함수의 의도는 정수 배열을 탐색하여 val 값을 처음으로 갖는 위치를 가리키는 포인터를 반환하는 것이다:
<syntaxhighlight lang="c">
int *search(int *p, int val) {
while (*p && *p != val)
p += sizeof(int); /* 잘못된 부분: 실제로는 p++이어야 함 */
return p;
}
</syntaxhighlight>
하지만 위 코드에서 4번째 줄은 p를 매번 4씩 증가시키고 있다. 그 결과, 이 함수는 배열의 모든 요소를 탐색하는 것이 아니라,
매 4번째 정수만 검사하게 된다. 즉, 배열의 일부만 잘못 탐색하며, val을 놓칠 수 있다. 올바른 구현은 다음과 같이 p++을 사용하는 것이다:
<syntaxhighlight lang="c">
while (*p && *p != val)
p++;
</syntaxhighlight>
===Referencing a Pointer Instead of the Object It Points To===
C 언어의 연산자 우선순위(precedence)와 결합법칙(associativity)에 대해 주의하지 않으면, 포인터가 가리키는 객체가 아닌, 포인터 그 자체를 잘못 조작하는 실수를 저지를 수 있다. 예를 들어, 아래 함수는 다음을 수행하려는 목적이다:
* *size개의 아이템을 가진 이진 힙(binary heap)에서 첫 번째 아이템을 제거한 뒤,
* 남은 *size - 1개의 아이템을 재정렬(reheapify)하는 것
<syntaxhighlight lang="c">
int *binheapDelete(int **binheap, int *size) {
int *packet = binheap[0];
binheap[0] = binheap[*size - 1];
*size--; /* 이 줄이 문제: 실제 의도는 (*size)-- 여야 함 */
heapify(binheap, *size, 0);
return(packet);
}
</syntaxhighlight>
6번째 줄에서의 의도는, 포인터 size가 가리키는 정수 값, 즉 *size를 감소시키는 것이다. 하지만 실제 코드에서는 단항 연산자 *와 --는 우선순위가 같고, 결합법칙은 오른쪽에서 왼쪽이기 때문에, *size--는 다음과 같이 해석된다:
<syntaxhighlight lang="c">
*(size--)
</syntaxhighlight>
즉, 포인터 자체(size)를 먼저 감소시키고, 감소 전 주소가 가리키던 값을 읽는다.
===Referencing Nonexistent Variables===
아래는 이미 유효하지 않은 지역 변수를 참조하는 실수를 보여주는 코드이다:
<syntaxhighlight lang="c">
int *stackref() {
int val;
return &val;
}
</syntaxhighlight>
이 함수는 스택에 존재하는 지역 변수 val의 주소를 반환한다. 그리고 곧바로 스택 프레임이 pop되면서 함수는 종료된다. 이후에도 p는 여전히 유효한 메모리 주소를 가리키고 있긴 하지만, 더 이상 유효한 변수는 아니다. 결국 나중에 *p에 어떤 값을 저장하려고 하면, 실은 다른 함수의 스택 프레임을 덮어쓰는 것이다.
===Memory Leaks===
메모리 누수(Memory leaks)는 느리고 조용하게 프로그램을 죽이는 문제로, 프로그래머가 할당한 힙 메모리를 free하지 않고 잊어버릴 때 발생한다. 예를 들어, 아래 함수는 힙 블록 x를 할당한 뒤, 이를 해제하지 않고 그냥 return한다:
<syntaxhighlight lang="c">
void leak(int n) {
int *x = (int *)Malloc(n * sizeof(int));
return; // 이 시점에서 x는 가비지(더 이상 접근 불가)
}
</syntaxhighlight>
이 함수가 자주 호출된다면, 힙은 점차적으로 가비지로 채워지고, 최악의 경우 가상 주소 공간 전체를 소모할 수도 있다.
프로그래머들은 가상 메모리(virtual memory)를 습득하고 사용해야 할때, malloc() 함수와 같은 동적 메모리 할당기(dynamic memory allocator)를 사용한다. 동적 메모리 할당기는 프로세스의 가상 메모리 내에 있는 (heap)이라고 불리는 영역을 관리한다. 이때 각 프로세스마다 커널은 힙의 맨위를 가리키는 brk라고 하는 변수를 유지한다. Figure 1은 가상 메모리를 시각적으로 보여준다.
동적 메모리 할당기는 힙을 크기가 다양한 블록 들의 집합으로 유지한다. 이때 각 블록은 연속적인 가상 메모리 조각이며, 할당되었거나(allocated) 비어있다(free). 할당된 블록은 애플리케이션에 의해 명시적으로 사용하기 위해 예약된 블록이다. 또한 비어 있는 블록(free block)은 할당이 가능한 상태이며, 애플리케이션에 의해 명시적으로 할당될 때까지는 계속 비어 있는 상태로 남는다. 할당된 블록은 애플리케이션이 명시적으로 free 하거나, 메모리 할당기 자체가 암묵적으로 해제할 때까지는 계속 할당된 상태이다.
동적 메모리 할당기는 두 가지의 기본적인 스타일로 나뉜다. 이때 두 스타일 모두 애플리케이션이 명시적으로 블록을 할당해야 한다는 점은 공통되며, 할당된 블록을 누가 해제하는지에 따라 차이가 있다:
명시적 할당기(explicit allocators): 애플리케이션이 할당한 블록을 명시적으로 해제해야 한다.
예를 들어, C 표준 라이브러리의 malloc 패키지가 이에 해당한다. C 프로그램은 malloc() 함수를 호출해 블록을 할당하고, free() 함수를 호출해 블록을 해제한다. C++의 new와 delete 호출도 이와 유사하다.
암시적 할당기(implicit allocators): 애플리케이션이 더 이상 할당된 블록을 사용하지 않게 되었음을 할당기가 감지해서 자동으로 해제한다.
암시적 할당기는 가비지 컬렉터(garbage collectors)라고도 불리며, 사용되지 않는 할당된 블록을 자동으로 해제하는 과정을 가비지 컬렉션(garbage collection)이라고 한다.
예를 들어, Lisp, ML, Java 같은 고급 언어들은 가비지 컬렉션에 의존해서 할당된 블록을 해제한다.
하지만, 해당 문서에서는 명시적 할당기의 설계와 구현에 대해 논의한다. 또한 앞으로 word 사이즈는 int를 기준으로 하고, 바이트가 아닌, 워드 단위로 주소를 사용한다고 가정한다.
The malloc and free Functions
C 표준 라이브러리는 malloc 패키지로 알려진 명시적 할당기를 제공한다. 프로그램은 malloc 함수를 호출하여 힙에서 블록을 할당한다:
#include<stdlib.h>void*malloc(size_tsize);//반환값: 성공하면 할당된 블록을 가리키는 포인터, 실패하면 NULL 반환
malloc() 함수는 size 바이트 크기의 메모리 블록을 반환하며, 해당 블록에 포함될 수 있는 데이터 객체가 적절하게 정렬(alignment)되도록 한다. 실제로 이 정렬 방식은 코드가 32비트 모드(gcc -m32)로 컴파일되었는지 64비트 모드로 컴파일 되었는지에 따라 달라진다. 32비트 모드에서는, malloc이 반환하는 블록의 주소는 항상 8의 배수이고, 64비트 모드에서는, 그 주소가 항상 16의 배수이다(바이트 기준).
만약 초기화된 동적 메모리가 필요한 경우, 프로그램은 calloc() 함수를 사용할 수 있으며, calloc() 함수는 내부적으로 malloc을 호출하고 할당된 메모리를 0으로 초기화한다. 이미 할당된 블록의 크기를 변경하고 싶은 경우에는, realloc() 함수를 사용하면 된다. malloc을 통해 동적으로 할당된 공간을 해제하고자 할때는, free() 함수를 이용하면 된다:
#include<stdlib.h>voidfree(void*ptr);//반환값 없음
Figure 2. Allocating and freeing blocks with malloc and free
이때 ptr 인자는 malloc, calloc, 또는 realloc을 통해 할당된 블록의 시작 주소를 가리켜야 한다. 그렇지 않은 경우, free의 동작은 정의되지 않는다(undefined behavior). Figure 2는 malloc과 free가 어떻게 작은 힙을 관리할 수 있는지를 보여준다. 이때 각 상자는 4바이트 워드를 나타내며, 따라서 해당 시스템은 32비트 시스템이다. 초기에는 힙이 더블 워드(8바이트) 정렬되어 있는 빈 메모리 공간이다:
Figure 2(a)에서는 프로그램이 4워드 블록을 요청한다. malloc은 비어 있는 블록의 앞쪽에서 4워드를 잘라 새 블록으로 만들고, 그 첫 번째 워드의 주소를 반환한다.
Figure 2(b)에서는 프로그램이 5워드 블록을 요청한다. 정렬을 유지하기 위해 malloc은 앞쪽에서 6워드 블록을 할당해준다.
Figure 2(c)에서는 프로그램이 6워드 블록을 요청하고, malloc은 비어 있는 블록에서 6워드를 잘라서 할당한다.
Figure 2(d)에서는 프로그램이 (b)에서 할당된 6워드 블록을 해제한다. free 호출이 끝난 후에도, 포인터 p2는 여전히 해제된 블록을 가리킨다.
포인터 p2를 사용하지 않는 것은 애플리케이션에게 달려있다.
Figure 2(e)에서는 프로그램이 2워드 블록을 요청한다. malloc은 이전 단계에서 해제된 블록 중 일부를 재사용하여 새 블록을 할당하고, 해당 주소를 반환한다.
Allocator Requirements and Goals
Allocator Requirements
명시적 할당기(explicit allocator)는 몇 가지 매우 엄격한 제약 조건 내에서 동작해야 한다:
임의의 요청 시퀀스를 처리해야 한다.
애플리케이션은 임의의 할당 및 해제 요청 시퀀스를 만들 수 있으며, 단 각 해제 요청은 이전의 할당 요청으로부터 얻은 현재 할당된 블록에 해당해야 한다는 제약을 가진다. 따라서, 할당기는 할당과 해제 요청의 순서에 대해 어떤 가정도 할 수 없다.
할당기는 할당 요청에 즉시 응답해야 한다.
즉, 성능 향상을 위해 요청을 재정렬하거나 버퍼링하는 것은 허용되지 않는다.
할당기가 확장 가능(scalable)하려면, 할당기에서 사용하는 모든 비스칼라(nonscalar) 자료구조는 힙 내에 저장되어야 한다.
할당기는 블록을 어떤 타입의 데이터 객체든 담을 수 있도록 정렬해서 제공해야 한다.
할당기는 비어 있는(free) 블록만 조작하거나 변경할 수 있으며, 한 번 할당된 블록은 수정하거나 이동할 수 없다.
Allocator Goals
이러한 제약 조건 안에서, 할당기 설계자는 성능 목표들, 즉 처리량(throughput)과 메모리 활용률(utilization)을 달성해야 한다. 하지만 이 둘은 종종 상충하는 목표이다.
어떤 길이 n을 가지는 할당 및 해제 요청 시퀀스 R0, R1, ..., Rk, ..., Rn-1이 주어졌을 때, 할당기의 처리량을 최대화해야 한다. 이때 처리량은 단위 시간당 처리한 요청 수로 정의된다. 예를 들어, 어떤 할당기가 1초 동안 malloc 500회, free 500회를 처리했다면, 그 처리량은 초당 1,000개의 연산이다. 일반적으로, 처리량을 높이기 위해서는 할당 및 해제 요청을 처리하는 평균 시간을 최소화해야 한다.
힙을 얼마나 효율적으로 사용하는지 측정하는 방법은 여러 가지가 있지만, 가장 유용한 척도는 최고 활용률(peak utilization)이다. 앞과 같이 할당 및 해제 요청 시퀀스 R0, R1, ..., Rk, ..., Rn-1이 주어졌다고 하자. 이때 애플리케이션이 p 바이트 크기의 블록을 요청했다면, 그 결과 할당된 블록에서 p 바이트는 payload에 해당한다. 요청 Rk까지 완료된 후, 현재 할당된 모든 블록의 payload 총합을 Pk라고 하고, 힙의 현재 크기를 Hk라고 하자. 이 경우 그러면, 첫 k+1개 요청에 대한 최고 활용률 Uk는 다음과 같이 정의된다:
Uk = (maxi<=k{Pi})/Hk
Fragmentation
힙 활용률이 낮은 주요한 원인은 단편화(fragmentation)이라고 알려진 현상 때문이다. 단편화는 실제로 사용되지 않는 메모리가 존재함에도 불구하고 할당 요청을 만족시킬 수 없는 상황에서 발생한다. 이때 단편화에는 두 가지 형태가 있다:
내부 단편화(internal fragmentation)
외부 단편화(external fragmentation)
Internal Fragmentation
내부 단편화는 할당된 블록의 크기가 그 payload보다 큰 경우 발생한다. 이러한 현상은 여러 이유로 인해 발생할 수 있다. 예를 들어:
동적 메모리 할당기가 요청된 payload보다 큰 최소 블록 크기를 강제하도록 강제하였다.
동적 매모리 할당기가 정렬 조건을 만족시키기 위해 블록 크기를 늘릴 수도 있다.
이때 어떤 시점에서의 내부 단편화로 인한 낭비되는 메모리의 양은 이전 요청의 패턴과 할당기 구현 방식에만 의존하므로 정량화(quantify)가 간단하다. 이는 할당된 각 블록의 크기와 그 payload의 차이를 모두 합한 것이다.
External Fragmentation
외부 단편화는 전체 비어 있는 메모리 총량은 충분하지만, 어떤 단일한 free 블록도 요청된 크기를 만족시킬 만큼 크지 않은 경우에 발생한다. 예를 들어, figure 2에서 (e)의 요청이 2워드가 아니라 8워드였다면, 힙에는 총 8워드의 free 메모리가 있지만, 두 개의 작은 free 블록으로 나뉘어 있기 때문에 요청을 만족시킬 수 없다. 이 문제는, 그 8워드가 서로 다른 두 블록에 분산되어 있기 때문에 발생한다. 따라서 외부 단편화는 내부 단편화보다 훨씬 정량화하기 어려운데, 이는 이전 요청 패턴, 할당기 구현, 미래 요청 패턴 모두에 의존하기 때문이다. 예를 들어, k번의 요청 이후 모든 free 블록이 정확히 4워드 크기라고 가정하면, 해당 힙이 외부 단편화를 겪고 있는가에 대한 질문의 답은 미래 요청 패턴에 따라 달라진다. 만약 앞으로의 모든 요청이 4워드 이하라면, 외부 단편화는 없다. 하지만 하나라도 4워드 초과 요청이 발생한다면, 힙은 외부 단편화를 겪고 있다고 할 수 있다.
Implementation Issues
가장 단순하게 상상할 수 있는 할당기는, 힙을 바이트 배열로 구성하고, 포인터 p를 사용해 그 배열의 첫 번째 바이트를 가리키도록 하는 것이다:
malloc이 size 바이트를 할당할 때, 현재 p의 값을 스택에 저장하고,
p를 size만큼 증가시킨 다음,
이전의 p 값을 호출자에게 반환한다.
free는 단순히 아무 작업도 하지 않고 호출자에게 복귀한다.
하지만 이는 단순히 너무 naive하다. 각 malloc과 free가 몇 개의 명령어만 실행하기 때문에, 처리량은 매우 우수할지 몰라도, 블록을 전혀 재사용하지 않기 때문에, 메모리 활용률(memory utilization)은 매우 나쁘다. 현실적인 할당기는 처리량과 메모리 활용률 사이의 더 나은 균형을 추구해야 하며, 다음과 같은 문제들을 고려해야 한다:
Free block 조직 (Free block organization): 비어 있는 블록들을 어떻게 추적할 것인가?
배치 (Placement): 새롭게 할당할 블록을 어떤 free 블록에 배치할 것인가?
분할 (Splitting): 어떤 free 블록에 새로 할당된 블록을 배치한 후, 남는 공간은 어떻게 처리할 것인가?
병합 (Coalescing): 방금 해제된 블록은 어떻게 처리할 것인가? 인접한 free 블록들과 합칠 것인가?
Implicit Free Lists
Figure 3. Format of a simple heap block
모든 실용적인 할당기는 블록 경계를 구분하고 할당된 블록과 비어 있는 블록을 구분할 수 있도록 하는 자료구조를 필요로 한다. 이때 대부분의 할당기는 이 정보를 블록 내부에 직접 포함시킨다. Figure 3은 이에 대한 한 간단한 접근 방식이다. 이 경우 하나의 블록은 다음과 같은 구성으로 이루어진다:
1워드짜리 헤더(header)
헤더는 블록의 전체 크기(헤더 포함)와, 해당 블록이 할당되어있는지의 여부를 나타낸다.
payload(추가적인 padding이 있을 수 있음)
만약 더블 워드 정렬(double-word alignment) 조건을 강제한다면, 블록 크기는 항상 8의 배수가 되고, 따라서 블록 크기의 하위 3비트는 항상 0이다. 이 경우, 우리는 상위 29비트에 블록 크기 정보를 저장하고, 남은 하위 3비트 중 일부를 다른 정보(예: 할당 여부)에 사용할 수 있다. 예를 들어, 24바이트 크기(0x18)의 할당된 블록이 있다면, 헤더는 (0x00000018 | 0x1) = 0x00000019와 같이 구성된다. 헤더 뒤에는 malloc 호출 시 애플리케이션이 요청한 payload가 따라오며, 그 뒤에는 padding이 올 수 있다. 이러한 padding은 외부 단편화를 완화하기 위해서 혹은 정렬 조건을 만족시키기 위해 사용될 수도 있다.
Figure 4. Organizing the heap with an implicit free list
Figure 3를 바탕으로 하는 블록의 형식을 기준으로, 힙을 figure 4와 같이 할당 블록과 비어 있는 블록의 시퀀스로 구성할 수 있다. 이러한 구성을 implicit free list라고 부르는데, free 블록들이 헤더의 size 필드를 통해 암시적으로 연결되어 있기 때문이다. 따라서 할당기는 힙 내의 모든 블록을 순회함으로써, 간접적으로 모든 free 블록들을 탐색할 수 있다. 이때 특별히 표시된 종료 블록(end block)이 필요하다. 이 예에서는, 할당 비트가 설정되고 크기가 0인 헤더가 끝을 나타낸다.
이때 중요한 점은, 시스템의 정렬 요구 사항과 할당기가 선택한 블록 형식이 동적 메모리 할당기에서 허용할 수 있는 최소 블록 크기를 결정한다는 것이다.즉, 어떤 블록도 이 최소 크기보다 작을 수 없다. 예를 들어, 더블 워드 정렬을 만족해야 한다면, 각 블록의 크기는 반드시 2워드(8바이트)의 배수여야 한다. figure 3를 기준으로는 최소 블록 크기는 2워드이며, 하나는 헤더용으로, 다른 하나는 정렬 조건을 유지하기 위한 용도이다. 즉 애플리케이션이 1바이트만 요청하더라도, 할당기는 2워드짜리 블록을 생성한다.
Implicit List: Finding a Free Block
Implicit free list의 장점은 매우 단순하다는 것이다. 하지만 free 리스트를 탐색하는 연산을 수행할 때 힙 내 모든 할당/비어 있는 블록 수에 대해 선형 시간(linear time)이 걸린다는 단점이 있다. 이때, implicit free list에서 free 블록을 탐색하는 배치 정책(placement)에는 3가지 방식이 있다.
첫번째 방식은 처음부터 순차적으로 탐색하여, 처음으로 맞는(fit) 빈 블록을 사용하는 first fit방식이다. 이는 아래와 같은 코드를 사용한다.
p=start;while((p<end)&&// 끝까지 가지 않았고((*p&1)||// *p & 1 : 이 비트가 1이면 할당된 블록(*p<=len)))// *p & -2 : 블록의 실제 크기 (하위 1비트 제거 → alignment 맞추기)p=p+(*p&-2);// 다음 블록으로 이동 (정렬 비트 제거)
이 방식의 장점은 리스트 끝 부분에 큰 free 블록을 보존하는 경향이 있다는 것이다. 하지만 리스트 앞 부분에 작은 free 블록 조각(splinter)가 생기기 쉽다는 단점도 존재한다.
또다른 방식으로는 next fit 방식이 있는데, 이는 first fit과 비슷하지만, 이전 탐색이 끝난 지점부터 다시 시작하는 방식이다. 이는 앞쪽에 이미 안 맞는 블록을 다시 확인하지 않는다는 장점이 존재하지만, 일부 연구에서는 단편화(fragmentation)를 조장한다는 단점이 있다.
마지막으로 best fit이라는 방식도 있는데, 이는 전체 리스트를 끝까지 탐색해, 가장 딱 맞는 블록을 선택하는 방식이다. 이는 작은 free 블록 조각을 감소시켜 메모리 활용도가 증가한다는 장점이 있지만, 탐색 비용이 크다는 단점이 있다. 힙 전체를 탐색하지 않고도 best-fit 정책을 근사적으로 구현하기 위해서는 구분된 free 리스트(segregrated free list) 방식을 사용해야 한다.
Splitting Free Blocks
할당기가 요청에 맞는 free 블록을 찾고 나면, 그 후에는 그 free 블록 중 얼마나 할당할지에 대한 결정을 내려야 한다. 한 가지 선택지는 free 블록 전체를 사용하는 것이다. 이는 단순하고 빠르지만 내부 단편화(internal fragmentation)를 초래할 수 있다는 단점이 있다. 만약 배치 정책이 best fit과 같이 요청한 크기에 거의 딱 맞는 free 블록을 자주 찾아낸다면 어느 정도의 내부 단편화는 감수할 수 있다.
Figure 5. Splitting a free block to satisfy a three-word allocation request
하지만 그렇지 않은 경우, 동적 메모리 할당기는 free 블록을 두 부분으로 분할한다. 첫 번째 부분은 할당된 블록이 되고, 나머지 부분은 새로운 free 블록이 된다. Figure 5는 Figure 3의 8워드짜리 free 블록을 어떻게 분할하는지에 대해 보여준다.
Coalescing Free Blocks
할당기가 할당된 블록을 해제(free)할 때, 그 새롭게 해제된 블록의 인접한 위치에 다른 free 블록이 존재할 수 있다. 이러한 인접한 free 블록들은 가짜 단편화(false fragmentation)라고 불리는 현상을 유발할 수 있다. 즉, 사용 가능한 free 메모리가 작고 쓸모없는 조각들로 쪼개져 있어서 실제로는 충분한 양의 메모리가 있음에도 불구하고, 요청을 만족시키지 못하는 상황이 발생하는 것이다.
Figure 6. An example of false fragmentation
Figure 6는 figure 5에서 할당된 블록을 해제한 후의 결과를 보여준다. 결과적으로, payload가 각각 3워드인 인접한 두 개의 free 블록이 생긴다. 이 경우, 만약 어떤 요청이 4워드 payload를 요구한다면, 전체 free 블록 크기는 충분하지만, 연속된 하나의 블록이 아니기 때문에 할당에 실패하게 된다. 이러한 false fragmentation을 방지하기 위해, 실용적인 동적 메모리 할당기라면 반드시 인접한 free 블록들을 병합(coalescing)해야 한다.
이때 병합을 언제 수행할 지는 매우 중요한 질문이다. 할당기는 다음 중 하나를 선택할 수 있다:
즉시 병합(immediate coalescing): 블록이 해제될 때마다 인접한 free 블록이 있다면 바로 병합한다.
지연 병합(deferred coalescing): 병합을 나중 시점까지 미루고, 특정 조건이 충족될 때 한꺼번에 수행한다.
예: 할당 요청이 실패했을 때 힙 전체를 스캔하여 모든 free 블록을 병합하는 방식이다.
즉시 병합은 구현이 단순하고, 상수 시간 내에 수행할 수 있다. 하지만 어떤 요청 패턴에서는 thrashing이라 불리는 비효율이 생길 수 있다. 예를 들면 어떤 블록이 해제되어 병합된 직후, 다시 할당되면서 다시 분할되는 일이 반복되는 경우이다. 해당 문서에서는 즉시 병합(immediate coalescing)을 전제로 하지만, 현실에서는 지연 병합(deferred coalescing)을 선택하는 경우가 많다.
Coalescing with Boundary Tags
우리가 해제하려는 블록을 현재 블록(current block)이라고 하자. 그러면 현재 블록의 다음 블록(next block)을 병합하는 것은 직관적이고 효율적이다. 현재 블록의 헤더는 다음 블록의 헤더를 가리키므로, 그 헤더를 검사해 다음 블록이 free인지 여부를 확인할 수 있다. 만약 다음 블록이 free라면, 그 크기를 현재 블록의 크기에 더하면 되고, 이를 통해 상수 시간 내에 병합할 수 있다.
하지만 이전 블록(previous block)을 병합은 더욱 까다롭다. 암시적 free 리스트에서는 각 블록에 헤더만 있으므로, 현재 블록에 도달할 때까지 리스트 전체를 순차적으로 탐색하며 이전 블록의 위치를 기억해야 한다. 즉, 암시적 free 리스트에서 free를 호출할 때, 필요한 시간은 힙 크기에 대해 선형 시간(linear time)이 된다.
Figure 7. Format of heap block that uses a boundary tag
이러한 문제를 해결하기 위해서 도입된 기법이 경계 태그(boundary tags)이며, 이는 이전 블록과의 병합을 상수 시간에 수행할 수 있게 해준다. 해당 방식의 핵심적인 아이디어는 figure 7과 같이 각 블록의 끝 부분에 header의 복사본인 footer(경계 태그)를 추가하는 것이다. 이렇게 하면, 현재 블록 기준으로 한 워드 앞에 있는 footer를 확인하여 이전 블록의 시작 위치 및 상태(할당/비어있음)를 알 수 있다.
할당기가 어떤 블록을 해제할 때, 발생 가능한 경우의 수는 다음 네 가지이다:
이전 블록과 다음 블록이 모두 할당됨
Figure 8. Coalescing with boundary tags이전 블록은 할당됨, 다음 블록은 free
이전 블록은 free, 다음 블록은 할당됨
이전 블록과 다음 블록이 모두 free
Figure 8은 이 네 가지 경우 각각에서 어떻게 병합이 수행되는지 보여준다.
Case 1: 양쪽 블록이 모두 할당됨 → 병합 불가
따라서, 현재 블록의 상태만 allocated → free로 변경
Case2: 현재 블록과 다음 블록을 병합
현재 블록의 헤더와 다음 블록의 footer를 합쳐진 크기로 업데이트
Case3: 이전 블록과 현재 블록을 병합
이전 블록의 헤더와 현재 블록의 footer를 합쳐진 크기로 업데이트
Case4: 이전, 현재, 다음 블록 모두 병합
이전 블록의 헤더와 다음 블록의 footer를 세 블록 크기의 합으로 업데이트
이 모든 경우에서 병합은 상수 시간에 수행된다.
경계 태그 기법은 단순하고 우아하며, 다양한 형태의 할당기와 free 리스트 조직에 일반적으로 적용 가능하다. 하지만 각 블록에 header와 footer를 모두 넣어야 하므로, 작은 블록을 많이 사용하는 애플리케이션에서는 메모리 오버헤드가 커질 수 있다는 단점이 있다. 이러한 단점을 극복하기 위해, 할당된 블록에는 footer를 생략할 수 있는 최적화 기법이 존재한다. 따라서, 현재 블록의 low-order bit 중 여분 비트 하나에 이전 블록의 할당 여부 비트를 저장하면, 할당된 블록에서는 footer 없이도 이전 블록 상태를 추론할 수 있다.
Explicit Free Lists
Figure 9. Format of heap blocks that use doubly linked free lists
Implicit free list는 힙에 존재하는 전체 블록 수에 대해 선형 시간(linear)이 걸리기 때문에, 범용 할당기(general-purpose allocator)로는 적합하지 않다. 더 나은 접근법은, free 블록들을 어떤 형태의 명시적(explicit) 데이터 구조로 조직하는 것이다. 정의상, free 블록의 내부(body)는 프로그램에서 사용되지 않으므로, 포인터들을 그 내부에 저장할 수 있다. 예를 들어, 힙을 이중 연결 리스트(doubly linked list)로 구성할 수 있다. 이는 figure 9에 잘 나타나 있다.
암시적 프리 리스트 대신 이중 연결 리스트를 사용하면, first-fit 할당 시간이 전체 블록 수에 대해 선형이던 것이 free 블록 수에 대해 선형 시간으로 감소한다. 또한 이를 활용한 다른 한 가지 방법은 free 리스트를 LIFO(후입선출) 순서로 유지하는 것이다. 즉, 새로 해제된 블록을 리스트의 맨 앞에 삽입한다. 이 경우 LIFO 순서 + first-fit 배치 정책을 함께 쓰면 할당기는 최근에 사용되었던 블록부터 검사한다. 따라서 free 연산은 상수 시간에 수행 가능하다. 또한 boundary tag를 사용하면, 병합(coalescing)도 상수 시간에 수행 가능하다.
다른 방식은 free 리스트를 주소 순서로 유지하는 것이다. 즉, 리스트 내에서 각 블록의 주소는 그 다음 블록의 주소보다 작다. 하지만 이 방식의 장점은 해당 방식의 first-fit이 LIFO 순서의 first-fit보다 메모리 활용률이 더 좋다는 점이다. 하지만 이는 블록을 해제할 때, 적절한 선행 블록(predecessor)을 찾기 위한 선형 탐색이 필요하다는 단점이 있다.
Segregated Free Lists
Figure 10. Each size class of blocks has its own free list
Segregated Free List는 각기 다른 크기의 블록들을 별도의 리스트(free list)에 저장하는 방식이다. 이를 size class라고 부르며 figure 10에 잘 나타나 있다. 이때 작은 크기일수록 더 정밀하게 클래스 구분을 하며, 큰 크기일수록 두 배 단위(power-of-two)로 묶어 관리(예: 16–31, 32–63 등)한다.
해당 방식에서는 malloc(n) 요청 시 크기 n보다 크거나 같은 클래스(m > n)을 찾는다. 해당 클래스에 대해 적절한 free 블록이 있으면 해당 블록을 사용한다. 이때 해당 블록을 쓰고 공간이 남으면 이를 split하여 남은 부분을 다른 free list로 보낼 수 있다. 만약 해당 클래스에 적절한 free 블록이 없다면, 다음으로 큰 사이즈의 클래스로 이동해 이를 반복한다. 만약 그래도 없다면, sbrk()로 OS에서 새로운 힙 메모리를 요청한다. 그리고 필요한 만큼 할당하고, 나머지는 가장 큰 클래스에 free 함수를 통해 넣는다.
블록을 해제할 때는 해제된 블록을 인접 블록과 병합(coalescing)한 뒤, 병합된 블록의 사이즈에 해당하는 클래스의 free list에 넣으면 된다.
이 방식의 장점은 로그 시간에 탐색 연산이 가능하므로, 처리량이 높게 뽑힌다는 점이다. 또한 메모리 활용이 높은데, 이는 해당 방식의 first-fit 탐색이 best-fit과 유사한 성능을 제공하기 때문이다. 만약 모든 크기에 대해 별도의 클래스를 제공한다면, best-fit과 일치하는 성능을 제공한다.
가상 메모리를 관리하고 사용하는 일은 C 프로그래머에게 어렵고 실수가 잦은 작업이다. 메모리 관련 버그는 특히 두려운 종류인데, 그 이유는 버그의 원인과 증상이 시간적으로나 공간적으로 멀리 떨어져서 나타나기 때문이다. 메모리 관련 버그는 특히 두려운 종류인데, 그 이유는 버그의 원인과 증상이 시간적으로나 공간적으로 멀리 떨어져서 나타나기 때문이다.
Dereferencing Bad Pointers
프로세스의 가상 주소 공간에는 의미 있는 데이터로 매핑되지 않은 큰 구멍(hole)들이 존재한다. 만약 우리가 이런 구멍 중 하나를 가리키는 포인터를 역참조하려 한다면, 운영체제는 프로그램을 segmentation exception로 종료시킨다. 또한, 가상 메모리 중 일부 영역은 읽기 전용(read-only)일 수 있다. 이런 영역에 쓰기를 시도하면, 프로그램은 protection exception로 종료된다.
잘못된 포인터 역참조의 대표적인 예시는 scanf 버그이다. 예를 들어, 우리가 scanf를 사용하여
stdin으로부터 정수를 읽어와 변수에 저장하고자 한다면, 올바른 방법은 다음과 같이 scanf에 서식 문자열과 변수의 주소를 전달하는 것이다:
scanf("%d",&val);
하지만, 아래와 같이 실수로 변수 val의 값 자체를 전달할 수 있다:
scanf("%d",val);// 잘못된 예
이 경우, scanf는 val의 내용을 주소로 해석해서 그 주소에 정수 값을 쓰려고 시도한다. 운이 좋다면 그 주소가 존재하지 않는 가상 메모리 주소이며, 프로그램은 즉시 예외와 함께 종료된다. 하지만 운이 나쁘다면 val의 내용이 정상적인 읽기/쓰기 메모리 영역의 주소일 수 있고, 그 결과, scanf는 해당 메모리를 덮어쓰게 된다. 이 경우 프로그램은 그 순간에는 멀쩡히 실행되지만, 훨씬 나중에 알 수 없는 방식으로 심각한 오류를 발생시킨다.
Reading Uninitialized Memory
bss 메모리 영역(예: 초기화되지 않은 전역 C 변수)은 로더(loader)에 의해 항상 0으로 초기화된다. 하지만 힙(heap) 메모리는 자동으로 0으로 초기화되지 않는다. 하지만 실수로 힙 메모리도 0으로 초기화되어 있다고 가정한다면 오류가 발생한다. 아래는 그 예시이다:
/* Return y = Ax */int*matvec(int**A,int*x,intn){inti,j;int*y=(int*)Malloc(n*sizeof(int));for(i=0;i<n;i++)for(j=0;j<n;j++)y[i]+=A[i][j]*x[j];returny;}
이 예제에서, 프로그래머는 벡터 y가 0으로 초기화되어 있다고 잘못 가정하고 있다. 하지만 Malloc은 초기화를 하지 않기 때문에, y[i]는 garbage를 가지고, 그 상태에서 += 연산을 하므로 결과가 의도한 대로 나오지 않는다. 이 코드를 올바르게 구현하려면, y[i]를 명시적으로 0으로 초기화하거나, 또는 calloc을 사용해야 한다:
int*y=(int*)Calloc(n,sizeof(int));// calloc은 자동으로 0으로 초기화함
Allowing Stack Buffer Overflows
프로그램이 입력 문자열의 크기를 확인하지 않고 스택에 있는 대상 버퍼에 데이터를 쓸 때, 이는 buffer overflow 버그이다. 예를 들어, 다음 함수는 버퍼 오버플로우 버그를 가지고 있다. 그 이유는 gets 함수가 길이에 제한 없이 문자열을 복사하기 때문이다:
voidbufoverflow(){charbuf[64];gets(buf);/* 여기에서 스택 버퍼 오버플로우 발생 */return;}
이 문제를 해결하려면, 입력 문자열의 크기를 제한하는 fgets() 함수를 사용해야 한다.
Allocating the (possibly) wrong sized object
이 오류는 프로그래머가 동적으로 할당한 배열의 크기를 헷갈려할 때 발생한다. 이는 아래와 같다:
Off-by-one 오류(한 칸 차이 오류)는 메모리 덮어쓰기(overwriting) 버그의 또 다른 흔한 원인이다:
/* Create an nxm array */int**makeArray2(intn,intm){inti;int**A=(int**)Malloc(n*sizeof(int*));// ← n개의 포인터를 위한 배열 생성for(i=0;i<=n;i++)// ← 문제 발생 지점: i <= nA[i]=(int*)Malloc(m*sizeof(int));returnA;}
5번째 줄에서, n개의 포인터를 저장할 수 있는 배열을 생성했는데 7~8번째 줄에서는 n + 1개의 요소를 초기화하려고 시도하고 있다. 그 결과, A 배열 다음에 위치한 다른 메모리를 덮어쓰게 된다. 이는 전형적인 off-by-one 오류이며, 메모리 손상이나 프로그램의 예기치 않은 동작을 유발할 수 있다.
Misunderstanding Pointer Arithmetic
또 하나의 흔한 실수는, 포인터에 대한 산술 연산이 바이트 단위가 아니라, 해당 포인터가 가리키는 객체의 크기 단위로 수행된다는 사실을 잊는 것이다. 예를 들어, 다음 함수의 의도는 정수 배열을 탐색하여 val 값을 처음으로 갖는 위치를 가리키는 포인터를 반환하는 것이다:
int*search(int*p,intval){while(*p&&*p!=val)p+=sizeof(int);/* 잘못된 부분: 실제로는 p++이어야 함 */returnp;}
하지만 위 코드에서 4번째 줄은 p를 매번 4씩 증가시키고 있다. 그 결과, 이 함수는 배열의 모든 요소를 탐색하는 것이 아니라,
매 4번째 정수만 검사하게 된다. 즉, 배열의 일부만 잘못 탐색하며, val을 놓칠 수 있다. 올바른 구현은 다음과 같이 p++을 사용하는 것이다:
while(*p&&*p!=val)p++;
Referencing a Pointer Instead of the Object It Points To
C 언어의 연산자 우선순위(precedence)와 결합법칙(associativity)에 대해 주의하지 않으면, 포인터가 가리키는 객체가 아닌, 포인터 그 자체를 잘못 조작하는 실수를 저지를 수 있다. 예를 들어, 아래 함수는 다음을 수행하려는 목적이다:
*size개의 아이템을 가진 이진 힙(binary heap)에서 첫 번째 아이템을 제거한 뒤,
남은 *size - 1개의 아이템을 재정렬(reheapify)하는 것
int*binheapDelete(int**binheap,int*size){int*packet=binheap[0];binheap[0]=binheap[*size-1];*size--;/* 이 줄이 문제: 실제 의도는 (*size)-- 여야 함 */heapify(binheap,*size,0);return(packet);}
6번째 줄에서의 의도는, 포인터 size가 가리키는 정수 값, 즉 *size를 감소시키는 것이다. 하지만 실제 코드에서는 단항 연산자 *와 --는 우선순위가 같고, 결합법칙은 오른쪽에서 왼쪽이기 때문에, *size--는 다음과 같이 해석된다:
*(size--)
즉, 포인터 자체(size)를 먼저 감소시키고, 감소 전 주소가 가리키던 값을 읽는다.
Referencing Nonexistent Variables
아래는 이미 유효하지 않은 지역 변수를 참조하는 실수를 보여주는 코드이다:
int*stackref(){intval;return&val;}
이 함수는 스택에 존재하는 지역 변수 val의 주소를 반환한다. 그리고 곧바로 스택 프레임이 pop되면서 함수는 종료된다. 이후에도 p는 여전히 유효한 메모리 주소를 가리키고 있긴 하지만, 더 이상 유효한 변수는 아니다. 결국 나중에 *p에 어떤 값을 저장하려고 하면, 실은 다른 함수의 스택 프레임을 덮어쓰는 것이다.
Memory Leaks
메모리 누수(Memory leaks)는 느리고 조용하게 프로그램을 죽이는 문제로, 프로그래머가 할당한 힙 메모리를 free하지 않고 잊어버릴 때 발생한다. 예를 들어, 아래 함수는 힙 블록 x를 할당한 뒤, 이를 해제하지 않고 그냥 return한다:
voidleak(intn){int*x=(int*)Malloc(n*sizeof(int));return;// 이 시점에서 x는 가비지(더 이상 접근 불가)}
이 함수가 자주 호출된다면, 힙은 점차적으로 가비지로 채워지고, 최악의 경우 가상 주소 공간 전체를 소모할 수도 있다.