다른 명령
새 문서: 상위 문서: 컴퓨터 시스템 ==개요== ==각주== 분류:컴퓨터 시스템 |
|||
| (같은 사용자의 중간 판 47개는 보이지 않습니다) | |||
| 2번째 줄: | 2번째 줄: | ||
==개요== | ==개요== | ||
컴퓨터 공학에서, 동시성(concurrent)이란 control flow들이 시간상으로 겹치는 것을 의미한다. 이는 컴퓨터 시스텀의 여러 계층에서 나타나며, OS 커널이 여러 애플리케이션을 실행하기 위해 사용하는 메커니즘 중 하나이다. 하지만 concurrent라는 개념은 애플리케이션 수준에서도 적용되어 아래와 같이 사용될 수 있다: | |||
* 느린 I/O 장치에 접근: I/O 장치는 상대적으로 느리게 실행되며, 이에 따라 CPU는 커널이 해당 작업을 수행하는 동안 다른 프로세스를 실행한다. | |||
* 사람과의 상호 작용: 컴퓨터를 사용하는 사람들은 동시에 여러 작업을 수행하기를 원하며, 이를 지원하기 위해 concurrent 개념이 사용된다. | |||
* 여러 네트워크 클라이언트 처리: [[Network Programming#Example Echo Client and Server: Iterative|Iterative server]]는 사실상 현실적이지 않은 서버이다. 이에 따라 concurrent 개념을 사용하여 각 클라이언트에 대해 별도의 control flow를 통해 처리할 수 있어야 한다. | |||
* 멀티코어 머신에서의 병렬 계산: 요즘 최신 시스템은 여러 CPU로 구성된 멀티코어 프로세서를 사용한다. 여러 control flow를 활용하는 애플리케이션은 멀티코어 프로세서를 통해 더욱 빠르게 실행될 수 있는데, 이는 각각의 flow들이 교대로 실행되는 것이 아니라 병렬적으로 실행되기 때문이다. | |||
애플리케이션 수준의 동시성을 사용하는 애플리케이션을 concurrent program이라고 하며, 현대의 OS는 이를 만들기 위해 세 가지 접근 방식을 기본적으로 제공한다: | |||
# Process-based: 각각의 '''control flow를 커널이 스케쥴링하고 관리하는 하나의 프로세스'''로 다룬다. | |||
#* 이때 프로세스는 서로 다른 가상의 주소 공간을 가지므로, 서로 통신하기 위해서는 명시적인 프로세스 간 통신(IPC) 메커니즘을 사용해야 한다. | |||
# Event-based: 애플리케이션이 하나의 프로세스 내에서 control flow들을 명시적으로 스케쥴링하는 방식이다. | |||
#* 이때 control flow는 FSM으로 모델링되며, 파일 디스크립터에서 데이터가 도착함에 따라 메인프로그램이 상태를 전이시키며, 이를 위해서 I/O multiplexing이라는 기술을 사용한다. | |||
#* 이 방식은 하나의 프로세스로 구성되어 있기 때문에 모든 flow들이 하나의 주소 공간을 공유한다. | |||
# Thread-based: 해당 방식에서는 커널이 단일 프로세스 내에서 실행되는 thread들을 자동으로 관리한다. | |||
#* 이 방식은 process-based 방식과 같이 커널에 의해서 스케쥴링되면서, 동시에 event-based 방식과 같이 하나의 프로세스 내에서 같은 주소 공간을 공유한다는 점에서 하이브리드 방식이라고 볼 수 있다. | |||
==Iterative Servers== | |||
[[파일:Iterative server control flow.png|대체글=Figure 1. Iterative server control flow|섬네일|Figure 1. Iterative server control flow]] | |||
Iterative 서버(server)는 여러 클라이언트의 요청을 하나씩 순차적으로 처리하는 서버이다. 이러한 서버의 control flow는 figure 1에 잘 나타나있다. Figure 1은 다음과 같은 control flow를 설명하고 있다: | |||
# Client 1이 서버에 <code>connect()</code> 함수를 호출하여 연결을 요청하고, 서버가 이를 <code>accept()</code> 한다. | |||
# Client 1이 <code>write()</code> 함수를 호출하여 데이터를 서버로 전송한다. | |||
# 서버가 <code>read()</code> 함수를 통해 전송된 데이터를 읽고, 이를 처리하여 <code>write()</code> 함수를 통해서 client 1에게 데이터를 전송한다. | |||
# Client 1은 연결을 <code>close()</code>하고, 서버는 비로소 client 2의 연결 요청을 <code>accept()</code> 한다. | |||
이를 client 2 입장에서 control flow를 다시 살펴보면, 다음과 같다: | |||
# <code>connect()</code>: 서버는 클라이언트의 연결 요청을 listen backlog 큐에 저장하고, 이에 따라 <code>connect()</code> 함수는 즉시 반환된다. | |||
#* 클라이언트가 <code>connect()</code> 함수를 호출했을 때, 클라이언트는 SYN 패킷을 서버로 보내고, 서버는 이에 대한 응답으로 ACK 패킷을 보낸다. | |||
#* 클라이언트는 서버로부터 ACK 패킷을 받고, 최종 ACK 패킷을 다시 서버로 보내고 handshake를 완료한다. | |||
#* 이 상태에서 서버의 커널은 연결을 listen backlog 큐에 저장해두며, 서버가 나중에 <code>accept()</code> 함수를 호출했을 때 해당 큐에서 연결을 하나 꺼내와서 처리한다. | |||
#* 즉, 서버는 연결을 즉시 수락하지 않으며, 보류된 연결로서 큐에 저장한다. 다른 의미로 보면, <code>accept()</code> 함수는 이 큐에서 연결 하나를 꺼내는 함수이다. | |||
# <code>rio_writen()</code>: 데이터를 클라이언트 TCP 소켓 버퍼에 작성하고, 커널이 이를 서버로 전송힌다. | |||
#* 클라이언트의 I/O 동작은 서버의 상태와는 무관하게 동작하므로,<ref>즉, 서버가 데이터를 실제로 read() 했는지 여부는 확인하지 않는다.</ref> 해당 함수를 호출한 즉시 반환된다. | |||
# <code>rio_readlineb()</code>: 해당 함수는 서버가 연결을 실제로 accept() 하기 전까지 블로킹(blocking)된다. | |||
#* 이는 서버가 아직 client 1과 통신 중이기 때문에 client 2의 요청을 아직 처리하지 않았기<ref>서버는 아직 Client 1만 처리 중이므로, Client 2에 대해 accept()도 하지 않았고, 데이터를 읽지도 않은 상태이다.</ref> 때문이다. | |||
이러한 관점에서 볼 때, client 2는 매우 큰 불편함을 겪는다고 볼 수 있다. 또한 client 1이 서버와의 상호작용 도중 잠시 자리를 비운다면, 해당 서버는 그 동안 어떤 작업도 수행하지 않으므로 매우 큰 비효율성이 초래된다. 즉, 이에 대한 해결책이 필요하며, 그것이 바로 concurrent server이다. | |||
==Concurrent Programming with Processes== | |||
Concurrent 프로그래밍의 가장 단순한 방법은 fork(), exec(), waitpid()와 같은 함수들을 사용해 프로세스를 통해 구현하는 것이다. 예를 들어 concurrent 서버를 구축하는 방식 중 하나는 부모 프로세스에서 클라이언트의 연결 요청을 수락하고, 그 후에 각각의 클라이언트마다 새로운 자식 프로세스를 생성하여 서비스를 제공하는 것이다. | |||
<gallery caption="Figure 2" widths="200px" heights="200px"> | |||
Server accepts connection.png|Figure 2.1. Server accepts connection | |||
Server forks a child.png|Figure 2.2. Server forks a child | |||
Server accepts another connection.png|Figure 2.3. Server accepts another connection | |||
Server forks another child.png|Figure 2.4. Server forks another child | |||
</gallery> | |||
이 방식이 어떻게 작동하는지 살펴보기 위해, 두 개의 클라이언트와 하나의 서버가 있고, 서버가 listening 디스크립터(예: listenfd(3))을 통해 연결 요청을 기다린다고 가정하자. 클라이언트 1이 먼저 서버에게 연결 요청을 보낸다면, 서버는 해당 요청을 수락하고 connected 디스크립터(예: connfd(4))를 반환한다. 해당 요청을 수락한 후, 서버는 자식 프로세스를 fork()하고, 해당 자식 프로세스는 서버의 [[System-Level I/O#Sharing Files|디스크립터 테이블]]의 전체 복사본을 가진다. 따라서 자식은 listenfd(3)를 닫고, 부모는 connfd(4)를 닫는다. 이때, 부모 자식의 connfd는 동일한 [[System-Level I/O#Sharing Files|파일 테이블]] 항목을 가리키므로, 부모가 자신의 connfd를 반드시 닫아야 한다. 만약 그렇지 않다면, 해당 connfd의 파일 테이블 항목은 삭제되지 않고, 결과적으로 메모리 누수(memory leak)가 발생하여, 가용 메모리를 모두 소비하고 시스템이 다운될 수 있다.<br> | |||
부모가 클라이언트 1을 위해 자식을 생성한 이후, 클라이언트 2가 새로운 연결 요청을 보낸다고 하자. 그러면 서버는 연결 요청을 수락하고, connfd(5)를 반환한다. 이후 부모는 또 다른 자식 프로세스를 fork()하고, 이 자식 프로세스는 connfd(5)를 이용해 클라이언트 2에게 서비스를 제공한다. 이 시점에서, 부모는 다음 연결 요청을 기다리고 있으며, 두 자식은 각자의 클라이언트를 동시(concurrently)에 서비스하고 있다. 이 모든 과정들은 figure 2에 잘 나타나 있다. | |||
이렇게 구현된 서버는 아래와 같은 특징들을 가진다: | |||
# 각 클라이언트는 자기 전용 자식 프로세스에 의해 처리된다. | |||
# 자식 프로세스들끼리는 메모리 등을 공유하지 않는다. | |||
즉, 안전하고 구조가 명확하지만 프로세스 자원이 많이 소모된다는 단점이 있다. | |||
===Process-Based Concurrent Echo Server=== | |||
아래는 process-based concurrent 서버의 간단한 예시를 보여준다. 이때 아래 코드에서 나온 echo() 함수는 [[Network Programming#Example Echo Client and Server: Iterative|Network Programming]] 문서에서 설명된 코드를 그대로 사용하였다: | |||
<syntaxhighlight lang="c"> | |||
#include "csapp.h" | |||
void echo(int connfd); | |||
void sigchld_handler(int sig) | |||
{ | |||
while (waitpid(-1, 0, WNOHANG) > 0); //모든 좀비 프로세스를 수거한다. | |||
return; | |||
} | |||
int main(int argc, char **argv) | |||
{ | |||
int listenfd, connfd; | |||
socklen_t clientlen; | |||
struct sockaddr_storage clientaddr; | |||
if (argc != 2) { | |||
fprintf(stderr, "usage: %s <port>\n", argv[0]); | |||
exit(0); | |||
} | |||
Signal(SIGCHLD, sigchld_handler); //SIGCHLD에 대한 시그널 핸들러 등록 | |||
listenfd = Open_listenfd(argv[1]); //argv[1]에 해당하는 포트 번호로 서버용 소켓을 열고 bind, listen | |||
while (1) { | |||
clientlen = sizeof(struct sockaddr_storage); | |||
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen); ////클라이언트가 연결 요청을 보내면 수락, connfd 생성 | |||
if (Fork() == 0) { | |||
Close(listenfd); //자식 프로세스는 listeing 디스크립터가 필요없으므로 닫는다. | |||
echo(connfd); //echo() 함수를 통해 서버와 통신한다. | |||
Close(connfd); //해당 connfd를 다 썼으므로 닫는다. | |||
exit(0); | |||
} | |||
Close(connfd); //서버는 해당 connfd가 필요없으므로 닫는다. | |||
} | |||
} | |||
</syntaxhighlight> | |||
위 코드를 기반으로하는 서버는 몇가지 주의 사항을 가진다. 먼저 서버는 일반적으로 장기간 실행되므로, 좀비 프로세스를 수거하는 SIGCHLD 핸들러를 반드시 포함하여야 한다. 이때 리눅스의 시그널을 큐잉되지 않으므로, SIGCHLD 핸들러는 여러 좀비 프로세스들을 한번에 수거할 수 있어야 한다. 그리고, 부모와 자식은 각자의 connfd 복사본을 반드시 닫아야 한다. 특히 부모가 자신의 connfd 복사본을 닫지 않으면 메모리 누수가 생길 수 있다. 마지막으로, 소켓의 파일 테이블 내의 reference count 때문에, 부모 자식 모두의 connfd 복사본이 닫힐 때까지 클라이언트와의 연결은 종료되지 않는다. | |||
===Pros and Cons of Process-based Servers=== | |||
Process-based 방식은 부모 프로레스와 자식 프로세스 사이에서 명확하게 정의되는 공유 모델을 가지고 있다. 파일 테이블은 공유하지만, 파일 디스크립터와 전역 변수들은 서로 공유하지 않는다. 이는 간단하고 직관적이므로 장점이라고 볼 수 있다. 또한 프로세스 마다 주소 공간이 분리되어 있다는 특징을 가지고 있는데, 이는 장점이자 단점이다. 이는 하나의 프로세스가 실수로 다른 프로세스의 가상 메모리를 덮어쓰는 것이 불가능하게 만들며, 이는 여러 오류들을 없애 준다. 하지만 주소 공간이 분리되어 있으므로, 프로세스 사이에서의 정보 공유가 더욱 어려워지며 서로 정보를 공유하기 위해서는 명시적인 IPC(interprocess communications) 메커니즘을 사용해야 한다. 또 다른 단점은, 프로세스 제어와 IPC에 추가적인 오버헤드가 발생하여 속도가 느려지는 경향이 있다는 것이다. | |||
==Concurrent Programming with I/O Multiplexing== | |||
사용자가 Standard I/O에 입력한 대화형 명령에도 응답할 수 있도록 해야 한다면, 서버는 동시에 아래 두가지 I/O 이벤트를 처리해야 한다: | |||
# Standard I/O을 통해 터미널에서 사용자의 입력을 받는 작업 | |||
# 네트워크 클라이언트로부터의 전송된 연결 요청을 처리하는 작업 | |||
위 둘중에서 어떤 이벤트를 우선적으로 처리해야 하는지는 확실하지 않다. 서버가 <code>accept()</code> 함수를 통해 클라이언트로부터의 연결 요청을 기다린다면, standard I/O로부터의 입력 명령어에는 응답할 수 없다. 마찬가지로 서버가 <code>read()</code> 함수를 통해서 입력 명령어를 기다리고 있다면, 네트워크 클라이언트로부터의 연결 요청을 처리할 수 없다. | |||
이러한 딜레마에 대한 하나의 해결책은 I/O multiplexing이라 불리는 기법이다. 서버는 기본적으로 여러 디스크립터를 가지고 있다. 이때 핵심적인 아이디어는 어떤 서버에 대해 프로세스를 여러 개 만드는 대신, 하나의 프로세스가 여러 소켓을 감시하며 이벤트가 발생한 것만 처리하는 방식이다. 이는 대략적으로 아래와 같은 반복 루프를 이용한다: | |||
# connfd와 listenfd 중 어떤 파일 디스크립터에 읽을 수 있는 데이터가 준비되었는지를 확인한다. | |||
# listenfd에 데이터가 있다면, 새로운 클라이언트 연결 요청이 들어왔다는 뜻이다. | |||
#* 이 경우 <code>accept()</code> 함수를 호출하여 새 연결을 수락하고, connfd[] 배열에 새로운 connfd[]를 등록한다. | |||
# 프로세스는 connfd[] 배열을 검사하여 입력이 존재하는 것만 찾아서 처리한다. | |||
이때 여러 파일 디스크립터에 대해서 I/O 이벤트를 감시하는 것은 <code>select(), epoll()</code> 함수들을 사용한다. 해당 함수들은 커널이 프로세스를 잠시 중단(block)시키고, 여러 파일 디스크립터에 대해 I/O 이벤트를 감시하도록 한다. 이때 하나 이상의 이벤트가 생기면 깨어나서 처리하도록 한다. 즉, I/O multiplexing을 간단하게 설명하면, '''<code>select(), epoll()</code> 함수를 사용하여 커널로 하여금 프로세스를 중지(suspend)시키고, 하나 이상의 I/O 이벤트가 발생했을 때, control을 애플리케이션으로 이전'''하는 것이다. | |||
* 디스크립터 집합 {0, 4} 중 하나가 읽을 수 있는 상태가 되면 반환된다. | |||
* 디스크립터 집합 {1, 2, 7}에 대해 하나가 쓸 수 있는 상태가 되면 반환된다. | |||
* select()는 최대 152.13초 동안 I/O 이벤트를 기다리며, 그 시간 안에 아무 이벤트도 발생하지 않으며, 타임아웃 상태가 되며, 0을 반환한다. | |||
<syntaxhighlight lang="c"> | |||
#include <sys/select.h> | |||
int select(int n, fd_set *fdset, NULL, NULL, NULL); | |||
FD_ZERO(fd_set *fdset); // fdset의 모든 비트를 0으로 초기화 | |||
FD_CLR(int fd, fd_set *fdset); // fdset에서 해당 fd 비트를 지움 | |||
FD_SET(int fd, fd_set *fdset); // fdset에서 해당 fd 비트를 켬 | |||
FD_ISSET(int fd, fd_set *fdset); // 해당 fd가 fdset에 포함되어 있는지 검사 | |||
</syntaxhighlight> | |||
논리적으로, 디스크립터 집합은 아래와 같은 n개의 비트 벡터로 생각할 수 있다. | |||
b<sub>n−1</sub>, ..., b<sub>1</sub>, b<sub>0</sub> | |||
각 비트 b<sub>k</sub>는 디스크립터 k에 해당하며, 디스크립터 k가 집합의 멤버인 경우에만 <code>b<sub>k</sub> = 1</code>이다. <code>select()</code> 함수가 받는 두 개의 인자는 read set이라고 불리는 디스크립터 집합과, 해당 집합의 크기<ref>해당 디스크립터 집합이 수용가능한 최대 디스크립터의 수를 의미한다.</ref>를 의미한다. <code>select()</code> 함수는 읽을 준비가 된 디스크립터가 하나 이상 생길 때까지 프로세스를 블록(block)하며, 어떤 I/O 이벤트가 발생하였을 때 I/O 작업에 대해 준비된 디스크립터의 개수를 반환한다.<ref>타임아웃이 발생하면 0을 반환하고, 오류 시에는 -1을 반환한다.</ref> 디스크립터 k가 읽을 준비가 되었다는 뜻은, 해당 디스크립터에서 1바이트를 읽으려는 요청이 블록되지 않는 경우를 의미한다.<ref>즉, <code>read()</code>와 같은 함수가 실행되었을 때 즉각적으로 데이터를 가져올 수 있는 상태를 의미한다.</ref><br> | |||
부가적인 효과로 <code>select()</code> 함수는 인자로 전달된 fd_set을 수정하여, read set의 부분 집합인 ready set을 표시한다. 이 ready set은 실제로 읽을 준비가 된 디스크립터들로 이루어지며, 함수의 반환값은 이 ready set의 크기를 의미한다. 주의할 점은, fd_set이 변경되기 때문에 <code>select()</code> 함수를 호출할 때마다 읽기 집합을 갱신해야 한다는 것이다. | |||
===Iterative server using I/O multiplexing=== | |||
아래는 <code>select()</code> 함수를 사용하여 standard I/O로부터 사용자의 명령어를 받을 뿐 아니라, 클라이언트로부터의 연결도 받는 iterative echo 서버를 구현한 예시 코드이다: | |||
<syntaxhighlight lang="c"> | |||
#include "csapp.h" | |||
void echo(int connfd); | |||
void command(void); | |||
int main(int argc, char **argv) | |||
{ | |||
int listenfd, connfd; | |||
socklen_t clientlen; | |||
struct sockaddr_storage clientaddr; | |||
fd_set read_set, ready_set; | |||
if (argc != 2) { | |||
fprintf(stderr, "usage: %s <port>\n", argv[0]); | |||
exit(0); | |||
} | |||
listenfd = Open_listenfd(argv[1]); //listening 소켓을 열고 bind, listen | |||
//read_set은 감시할 디스크립터 집합이며, 이는 고정되어 있다. | |||
FD_ZERO(&read_set); //빈 파일 디스크립터 집합 생성 | |||
FD_SET(STDIN_FILENO, &read_set); //표준 입력(stdin) 디스크립터 0 추가 | |||
FD_SET(listenfd, &read_set); //listening 디스크립터 3 추가 | |||
while (1) { | |||
ready_set = read_set; //원래의 read_set으로 복구한다. | |||
//accept() 함수를 호출해 연결 요청을 기다리는 대신 select() 함수를 호출하여 I/O 이벤트를 감시 | |||
Select(listenfd+1, &ready_set, NULL, NULL, NULL); | |||
if (FD_ISSET(STDIN_FILENO, &ready_set)) //Standard I/O에 명령어가 입력되었을 때 | |||
command(); //stdin으로부터 명령어를 읽는다. | |||
if (FD_ISSET(listenfd, &ready_set)) { //클라이언트로부터의 연결 요청이 들어왔을 때 | |||
clientlen = sizeof(struct sockaddr_storage); | |||
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); | |||
echo(connfd); //connfd 디스크립터를 이용해 클라이언트와 상호 작용 | |||
Close(connfd); | |||
} | |||
} | |||
} | |||
void command(void) { //터미널에 입력된 사용자 명령어를 읽어들이는 함수이다. | |||
char buf[MAXLINE]; | |||
if (!Fgets(buf, MAXLINE, stdin)) exit(0); //EOF를 만난 경우 exit | |||
printf("%s", buf); //사용자 명령어 출력 | |||
} | |||
</syntaxhighlight> | |||
[[파일:Fd set setting by FD ZERO.png|섬네일|Figure 3. fd_set setting by FD_ZERO]] | |||
[[파일:Fd set setting by FD SET.png|섬네일|Figure 4. fd_set setting by FD_SET]] | |||
[[파일:Select() returns fd set when user types "Enter".png|섬네일|Figure 5. select() returns fd_set when user types "Enter"]] | |||
위 코드에서는 <code>open_listenfd()</code> 함수를 사용하여 listening 디스크립터를 열고, <code>FD_ZERO()</code> 매크로 함수를 이용하여 빈 디스크립터 집합을 만든다. 그 다음의 두 줄에서는 read set에 stdin 디스크립터 0과 listening 디스크립터 3을 추가한다. 이때의 read set은 figure 3, 4와 같이 나타난다.<br> | |||
그 이후의 반복 루프 내에서는 <code>accept()</code>를 호출해 연결 요청을 기다리는 대신, <code>select()</code> 함수를 호출하여 listening 디스크립터 또는 stdin 중 어느 하나라도 읽을 준비가 될 때까지 블록한다. 예를 들어, 사용자가 Enter 키를 눌렀다면 stdin 디스크립터가 읽을 준비가 되므로, 이때 <code>select()</code> 함수는 figure 4와 같은 준비 집합을 반환한다. <code>select()</code> 함수가 반환되며, <code>FD_ISSET()</code> 매크로 함수를 사용하여 어떤 디스크립터가 읽을 준비가 되었는지를 확인한다. stdin이 준비되었으면, <code>command()</code> 함수를 호출하여 입력을 읽고, 파싱하고, 명령에 응답한 후 다시 반복문을 진행한다. Listening 디스크립터가 준비되었다면, <code>accept()</code> 함수를 호출하여 connected 디스크립터를 얻고, 이를 바탕으로 <code>echo()</code> 함수를 통해서 클라이언트가 자신의 연결을 닫을 때까지 전송된 각 줄을 읽고 다시 돌려보낸다. | |||
해당 프로그램은 <code>select()</code> 함수를 사용하는 좋은 예이지만, 여전히 아쉬운 점이 있다. 문제는 클라이언트와 연결되면, 클라이언트가 자신의 연결을 닫을 때까지 서버는 해당 연결에 구속된다는 것이다. 따라서 이 상태에서 stdin을 통해서 명령어를 입력하면, 클라이언트와의 연결이 종료될 때까지 해당 명령어를 실행할 수 없다. | |||
=== I/O Multiplexed Event Processing=== | |||
[[파일:FSM for concurrent event-based echo server.png|가운데|섬네일|Figure 6. FSM for concurrent event-based echo server]] | |||
I/O multiplexing은 특정한 이벤트의 결과를 통해서 흐름이 진행되는 concurrent event-driven 프로그램에 대한 기본적인 기법으로 사용될 수 있다. Figure 6는 concurrent event-driven echo 서버의 논리적인 흐름(logical flow)를 나타내는 FSM이다. 서버는 새로운 클라이언트 k에 대해, 새로운 FSM을 생성하고 이를 connected 디스크립터 dk와 연관시킨다. Figure 6에서 알 수 있듯이, FSM sk는 하나의 상태(state)<ref>"디스크립터 dk가 읽기 준비가 되기를 기다리는 중”</ref>, 하나의 입력 이벤트(event)<ref>“디스크립터 dk가 읽기 준비가 됨”</ref>, 하나의 전이(transition)<ref>“디스크립터 dk로부터 한 줄의 텍스트를 읽고 echo() 하기”</ref>만을 가진다. 서버는 <code>select()</code> 함수를 사용한 I/O multiplexing을 통해서 입력 이벤트의 발생을 감지한다. 각각의 connected 디스크립터가 읽기를 준비할 때마다, 서버는 해당 상태 기계의 전이를 실행한다. 아래는 이와 같은 메커니즘을 이용한 concurrent event-based echo 서버의 예시 코드이다: | |||
<syntaxhighlight lang="c"> | |||
#include "csapp.h" | |||
typedef struct { | |||
int maxfd; //read set 배열 내에서 최대 인덱스 | |||
int maxi; //clientfd 배열 내에서 최대 인덱스 | |||
fd_set read_set; //현재 서버가 감시할 모든 디스크립터 집합 | |||
fd_set ready_set; //select()에 의해 읽기 준비된 디스크립터 집합 | |||
int nready; //select() 함수를 통해 준비가 되어 있는 디스크립터들의 수 | |||
int clientfd[FD_SETSIZE]; //연결된 클라이언트의 소켓 디스크립터들 | |||
rio_t clientrio[FD_SETSIZE]; //Rio_readlineb()을 위한 읽기 버퍼들 | |||
} pool; //활성화된 클라이언트들의 집합을 관리하는 구조체 | |||
int byte_cnt = 0; //서버가 읽어들인 총 바이트 수 | |||
int main(int argc, char **argv) { | |||
int listenfd, connfd; | |||
socklen_t clientlen; | |||
struct sockaddr_storage clientaddr; | |||
static pool pool; | |||
if (argc != 2) { | |||
fprintf(stderr, "usage: %s <port>\n", argv[0]); | |||
exit(0); | |||
} | |||
listenfd = Open_listenfd(argv[1]); //listening 소켓을 열고 bind, listen | |||
init_pool(listenfd, &pool); //pool 구조체 초기화 | |||
while (1) { | |||
//select() 호출 → 리슨 소켓 또는 클라이언트 소켓에서 읽기 가능한 상태가 올 때까지 대기 | |||
pool.ready_set = pool.read_set; | |||
pool.nready = Select(pool.maxfd+1, &pool.ready_set, NULL, NULL, NULL); | |||
//listenfd가 준비되었다면 클라이언트가 연결 요청을 한 것 | |||
if (FD_ISSET(listenfd, &pool.ready_set)) { | |||
clientlen = sizeof(struct sockaddr_storage); | |||
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); | |||
add_client(connfd, &pool); | |||
} | |||
//연결된 클라이언트 중에서 select() 함수를 통해 준비가 감지된 소켓에서 echo() 수행 | |||
check_clients(&pool); | |||
} | |||
} | |||
</syntaxhighlight> | |||
위 코드에서 read set 집합은 poop이라는 구조체로 관리된다. 서버는 main 함수 내에서 <code>init_pool()</code> 함수를 호출해 pool을 초기화한 후, 무한 루프에 진입한다. 해당 무한 루프 내에서 서버는 <code>select()</code> 함수를 호출하여 두 가지의 입력 이벤트를 감지한다. 하나는 새로운 클라이언트로부터 연결 요청을 받는 것이고, 다른 하나는 기존 클라이언트에 연결된 connfd가 읽기 준비가 된 경우이다. 새 클라이언트로부터 연결 요청을 감지하면 서버는 <code>Accept()</code> 함수를 호출하여 연결을 열고, <code>add_client()</code> 함수를 호출하여 클라이언트를 pool 구조체를 통해 등록한다. 마지막으로 서버는 <code>check_clients()</code> 함수를 호출해 준비된 각 connected 디스크립터로부터 한 줄의 텍스트를 echo한다. | |||
<syntaxhighlight lang="c"> | |||
void init_pool(int listenfd, pool *p) { | |||
int i; | |||
p->maxi = -1; | |||
for (i = 0; i < FD_SETSIZE; i++) //clientfd 배열의 원소 비활성화 | |||
p->clientfd[i] = -1; | |||
p->maxfd = listenfd; | |||
FD_ZERO(&p->read_set); | |||
FD_SET(listenfd, &p->read_set); //초기 read_set의 유일한 원소는 listenfd | |||
} | |||
</syntaxhighlight> | |||
<code>init_pool()</code> 함수는 pool 구조체를 초기화한다. clientfd 배열은 연결된 디스크립터의 집합을 나타내며, 정수 -1은 사용 가능한 슬롯을 뜻한다. 초기에는 clientfd 배열은 비어 있고, read_set 배열은 listenfd 디스크립터 하나를 저장한다. | |||
<syntaxhighlight lang="c"> | |||
void add_client(int connfd, pool *p) | |||
{ | |||
int i; | |||
p->nready--; | |||
for (i = 0; i < FD_SETSIZE; i++) { | |||
if (p->clientfd[i] < 0) { //비어있는 clientfd 배열 항목 찾기 | |||
p->clientfd[i] = connfd; //비어있는 clientfd 배열 항목에 connfd 등록 | |||
Rio_readinitb(&p->clientrio[i], connfd); | |||
FD_SET(connfd, &p->read_set); //pool 구조체에 connfd 등록 | |||
if (connfd > p->maxfd) | |||
p->maxfd = connfd; //maxfd의 값 갱신 | |||
if (i > p->maxi) | |||
p->maxi = i; //maxi의 값 갱신 | |||
break; | |||
} | |||
} | |||
if (i == FD_SETSIZE) app_error("add_client error: Too many clients"); //더 이상 클라이언트 등록 불가 | |||
} | |||
</syntaxhighlight> | |||
<code>add_client()</code> 함수는 새로운 클라이언트와 연결된 connfd를 clientfd 배열에 추가한다. clientfd 배열에서 빈 슬롯을 찾은 후, 서버는 connfd를 배열에 추가하고, 해당 디스크립터에 대해 <code>rio_readlineb()</code> 함수 호출이 가능하도록 Rio 읽기 버퍼를 초기화한다. 그리고, <code>select()</code> 함수가 감시할 read set에 해당 디스크립터를 추가한다. | |||
<syntaxhighlight lang="c"> | |||
void check_clients(pool *p) { | |||
int i, connfd, n; | |||
char buf[MAXLINE]; | |||
rio_t rio; | |||
for (i = 0; (i <= p->maxi) && (p->nready > 0); i++) { //ready set에 속하는 원소 탐색 | |||
connfd = p->clientfd[i]; //알맞은 디스크립터 사용 | |||
rio = p->clientrio[i]; //알맞은 rio 버퍼 사용 | |||
if ((connfd > 0) && (FD_ISSET(connfd, &p->ready_set))) { //해당 디스크립터가 준비되었다면, echo함 | |||
p->nready--; | |||
if ((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) { //클라이언트로부터 읽어 들이기 | |||
byte_cnt += n; | |||
printf("Server received %d (%d total) bytes on fd %d\n", n, byte_cnt, connfd); | |||
Rio_writen(connfd, buf, n); //클라이언트에 echo하기 | |||
} else { //EOF가 감지되었다면, 해당 connfd를 clientfd 배열에서 제거 | |||
Close(connfd); | |||
FD_CLR(connfd, &p->read_set); | |||
p->clientfd[i] = -1; | |||
} | |||
} | |||
} | |||
} | |||
</syntaxhighlight> | |||
<code>check_clients()</code> 함수는 준비된 각 connfd로부터 텍스트 한 줄을 echo하는 함수이다. 풀어서 설명하면, 텍스트 줄 읽기에 성공하면 해당 줄을 클라이언트에게 다시 echo하며, echo한 문장열의 길이와 지금까지 모든 클라이언트로부터 echo한 문자열들의 총 바이트 수를 출력한다. 만약 클라이언트가 연결을 닫아 EOF가 감지되면, 서버는 자신의 연결도 닫고 해당 디스크립터를 clientfd 배열에서 제거한다. | |||
Figure 6의 FSM의 관점에서 보면, <code>select()</code> 함수는 입력 이벤트를 감지하고, <code>add_client()</code> 함수는 새로운 FSM을 생성한다. <code>check_clients()</code> 함수는 상태 전이를 수행하여 입력 라인을 echo하고, 클라이언트가 연결을 닫으면 FSM을 삭제한다. | |||
===Pros and Cons of Event-based Servers=== | |||
위에서 작성한 서버는 I/O multiplexing 기반의 event-driven 프로그래밍의 장점과 단점을 잘 보여주는 사례이다. 첫 번째 장점은 event-based 설계가 process-based 설계보다 프로그램의 동작에 대해 더 많은 control을 프로그래머에게 부여한다는 것이다. 위 서버 코드를 응용하면 어떤 클라이언트에게 우선 서비스를 제공하는 event-based concurrent 서버를 작성할 수 있는데, 이는 process-based 서버에서는 구현하기 어렵다.<br> | |||
또 다른 장점은 해당 서버가 하나의 control flow 내에서 실행되기 때문에 코드의 모든 부분이 그 프로세스의 전체 주소 공간에 접근할 수 있다는 것이다. 이는 각각의 flow 간에 데이터를 공유하기 쉽도록 만들어 준다. 또한 이와 같이 구현하면 gdb와 같은 디버깅 도구를 통해서 순차적인 control flow를 거치며 디버깅할 수 있다는 장접이 있다.<br> | |||
마지막으로, 프로세스나 쓰레드를 제어하는데 소요되는 오버헤드가 존재하지 않아 효율적으로 구현할 수 있다는 장점이 있다. 이러한 장점 덕분에 높은 퍼포먼스를 요구하는 웹 서버나 검색 엔진등에 사용된다. | |||
하지만 이렇게 구성된 서버는 코드가 복잡해진다는 치명적인 단점을 가지고 있다. 위의 예시 코드는 process-based 서버보다 3배 더 긴 코드를 가지고 있다. 이는 concurrent의 granularity가 낮아질수록 코드의 복잡성이 증가한다. Granularity란, 단위 시간마다 control flow가 실행하는 명령어의 수이다. 예를 들어, 이 서버에서는 한 줄의 텍스트를 읽는 동안 실행되는 명령어의 수가 concurrent의 granularity이다.<br> | |||
또한 잘 정제된(fine-grained) concurrency를 제공할 수 없다는 단점이 있다. 이는 어떤 control flow가 클라이언트로부터의 입력을 읽고 있는 동안에는, 다른 어떤 명령어도 실행할 수 없다는 문제점과 연결된다.. 이러한 결점 때문에 어떤 악의적인 클라이언트가 텍스트 줄의 일부만 전송하고 정지해버릴 경우, 서버는 다른 클라이언트로부터의 연결 요청이나 echo를 수행할 수 없다.<br> | |||
또 다른 중요한 단점은 하나의 control flow만 활용하기 때문에 이와 같이 작성된 서버는 멀티코어 프로세서의 성능을 완전히 활용할 수 없다는 것이다. | |||
==Concurrent Programming with Threads== | |||
Process-based 접근 방식은 각 flow 마다 별도의 프로세스를 사용하며 커널을 통해 각 프로세스를 자동으로 스케쥴링하는 방식이다. Event-based 접근 방식은 control flow를 직접 구현하고, 하나의 flow 내에서 I/O multiplexing을 이용해 명시적으로 flow를 스케쥴링한다. 이러한 관점에서 볼 때, thread-based 접근 방식은 위 두 문단에서 다룬 접근 방식의 혼합형이라고 볼 수 있다. | |||
쓰레드(thread)란 프로세스의 컨텍스트(context) 안에서 실행되는 control flow이다. 현대 시스템은 하나의 프로세스 내에서 여러 쓰레드가 동시에(concurrently) 실행되는 프로그램을 작성할 수 있으며, 각각의 쓰레드는 커널에 의해서 자동으로 스케쥴링된다. 각 쓰레드는 TID<ref>각 쓰레드를 식별하기 위해서 사용되는 정수 thread ID이다.</ref>, 스택, 스택 포인터, 프로그램 카운터, 범용 레지스터(general purpose register) 등의 쓰레드 컨텍스트(thread context)를 가진다. 그럼에도 하나의 프로세스 안에서 실행되는 모든 쓰레드는 해당 프로세스의 전체 virtual memory 공간을 공유한다. | |||
쓰레드를 기반으로 하는 control flow는 process-based 기반의 flow와 event-based 기반의 flow의 특성을 결합한 형태이다. 프로세스와 같이 쓰레드는 커널에 의해서 자동으로 스케쥴링되며, 커널에 의해 고유한 ID로 식별된다. 그럼에도 Event-based 기반의 flow와 같이 여러 쓰레드는 하나의 프로세스 컨텍스트 안에서 실행되며, 프로세스의 전체 virtual memory를 공유한다. 이에 따라 각 쓰레드들은 code, data, heap, 공유 라이브러리, 파일 디스크립터들을 공유한다.<ref>stack 메모리 공간은 공유하지 않는다. 이 덕분에 쓰레드는 메모리를 효율적으로 공유하면서도 함수 호출/로컬 변수의 충돌을 방지할 수 있다.</ref> | |||
===Processes vs. Threads=== | |||
[[파일:Traditional View of a Process.png|섬네일|Figure 7. Traditional View of a Process]] | |||
프로세스를 해석하는 전통적인 관점에서는, 프로세스는 프로세스 컨텍스트와 Code/Data/Stack 메모리 공간<ref>Code/Data/Stack은 메모리의 Code 영역, Data 영역, Stack 영역, Heap 영역이 모두 포함한다.</ref>으로 이루어진다. 이때, 프로세스 컨텍스트에는 레지스터 값, [[Register#Flag registers|조건 코드]](Condition codes), 스택 포인터, 프로그램 카운터등이 포함된다. 이때 프로세스 컨텍스트와 대비되는 개념으로 커널 컨텍스트가 존재하며, 이에는 가상 메모리 구조, 디스크립터 테이블, brk 포인터 등이 포함된다. 이는 figure 7이 잘 보여주고 있다. | |||
[[파일:Alternate View of a Process.png|섬네일|Figure 8. Alternate View of a Process]] | |||
프로세스를 쓰레드와 결부시켜 해석하는 시각도 존재한다. 이 시각에서는 프로세스를 하나의 메인 쓰레드로 보며, 프로세스를 쓰레드 컨텍스트와 Code/Data 메모리로 구성되어 있다고 본다. 이때, 프로세스 컨텍스트에는 레지스터, 조건 코드, 스택 포인터, 프로그램 카운터등이 포함된다. 또한 각각의 쓰레드들은 Heap, Code, 전역 데이터, 공유 라이브러리 등과 커널 컨텍스트를 공유한다. 이때 각 쓰레드들은 자신만의 스택 메모리 공간을 가지고, 이를 이용해 함수 호출이나, 지역 변수등을 관리할 수 있다. 하지만 이는 별도로 보호되어 있지 않으며, 이로 인해 다른 쓰레드에 의해 접근될 수 있다. 또한 각 쓰레드들은 커널에 의해서 식별되기 위해서 고유한 thread ID(TID)를 가진다. 이는 figure 8이 잘 보여주고 있다. | |||
아래는 쓰레드와 프로세스의 차이점을 정리한 표이다. | |||
{| class="wikitable" | |||
|+ | |||
! | |||
!프로세스 | |||
!쓰레드 | |||
|- | |||
| rowspan="3" |공통점 | |||
| colspan="2" |모두 자신 만의 logical control flow를 가진다. | |||
|- | |||
| colspan="2" |다른 프로세스/쓰레드와 concurrently하게 실행될 수 있다. | |||
|- | |||
| colspan="2" |context switch가 가능하다. | |||
|- | |||
| rowspan="2" |차이점 | |||
|프로세스는 일반적으로 메모리 구조, 데이터 등을 공유하지 않는다. | |||
|쓰레드는 모든 코드와 데이터를 공유한다.<ref>Local stack은 공유하지 않는다.</ref> | |||
|- | |||
|프로세스 컨트롤은 생성, 수거 면에서 더욱 복잡하다. | |||
|쓰레드는 프로레스 보다 관리할 때 비용면에서 저렴하다. | |||
|} | |||
===Thread Execution Model=== | |||
[[파일:Logical View of Threads and Processes.png|섬네일|Figure 9. Logical View of Threads and Processes]] | |||
여러 쓰레드에 대한 실행 모델은 여러 프로세스에 대한 실행 모델과 많은 면에서 유사하다. Figure 을 살펴보면, 각 프로세스는 메인 쓰레드라고 불리는 하나의 쓰레드로 시작한다. 이후 어떤 시점에서 메인 쓰레드는 피어 쓰레드(peer)를 생성하고, 이 시점부터 두 쓰레드는 동시에 실행된다. 이때 피어 쓰레드가 실행되는 경우는 메인 쓰레드가 <code>read(), sleep()</code>로 인해서 잠시 블록되거나, 타이머에 의해 메인 쓰레드가 인터럽트되어 context switch가 발생하는 경우이다. | |||
[[파일:Concurrent Thread Execution.png|섬네일|Figure 10. Concurrent Thread Execution(single/multi)]] | |||
쓰레드들은 프로세스 단위로 피어 집합(pool of peers)을 형성한다. 이때 프로세스는 트리 구조를 이루는 반면, 쓰레드들은 같은 프로세스 내에서 평등한 peer 관계를 가진다. 이때 두 쓰레드가 시간 상 겹쳐서 실행되면 동시적인(concurrent) 실행이라고 한다. 이때 겹치지 않으면 순차적인 실행이라고 한다. 이때 단일 코어(single core) CPU를 통해 실행이 될 경우에는 time slicing을 통해서 병렬성(parallelism)을 흉내내는 정도에 그치지만, 멀티 코어(multi core)를 이용하여 실행할 경우에는 진정한 의미의 병렬성을 구현할 수 있게 된다. | |||
쓰레드 실행은 프로세스와 몇가지 중요한 측면에서 다르다. 쓰레드의 컨텍스트는 프로세스의 컨텍스트보다 더 작기 때문에, 쓰레드의 컨텍스트 변경은 프로세스의 그것 보다 더욱 빠르게 이루어진다. 또한, 쓰레드는 프로세스와 달리 엄격한 부모-자식 계층 구조를 가지지 않는다. 한 프로세스에 속한 쓰레드들은 어떤 쓰레드에 의해서 생성되었는지와 상관없이 모두 동등한 피어의 무리(pool)을 이룬다. 따라서 어떤 쓰레드는 동일한 무리에 속한 다른 쓰레드를 종료시킬 수 있고, 종료되기를 기다릴 수 있다. | |||
===[[Posix Threads]]=== | |||
자세한 내용은 [[Posix Threads]] 문서를 참조하십시오. | |||
===A Concurrent Server Based on Threads=== | |||
아래는 thread-based echo 서버의 코드이다: | |||
<syntaxhighlight lang="c"> | |||
#include "csapp.h" | |||
void echo(int connfd); //사용할 echo 함수 | |||
void *thread(void *vargp); // | |||
int main(int argc, char **argv) | |||
{ | |||
int listenfd, *connfdp; | |||
socklen_t clientlen; | |||
struct sockaddr_storage clientaddr; | |||
pthread_t tid; | |||
if (argc != 2) { | |||
fprintf(stderr, "usage: %s <port>\n", argv[0]); | |||
exit(0); | |||
} | |||
listenfd = Open_listenfd(argv[1]); //argv[1]에 해당하는 포트 번호로 서버용 소켓을 열고 bind, listen | |||
while (1) { | |||
clientlen = sizeof(struct sockaddr_storage); // 클라이언트 주소 구조체 크기 설정 | |||
connfdp = Malloc(sizeof(int)); // connfd 값을 저장할 공간을 connfdp에 동적으로 할당 | |||
*connfdp = Accept(listenfd, (SA *) &clientaddr, &clientlen); //해당 connfd 디스크립터에 대한 연결 수락 | |||
Pthread_create(&tid, NULL, thread, connfdp); //이 포인터를 인자로 쓰레드를 생성하기 위해 thread() 함수 호출 | |||
} | |||
} | |||
/* Thread routine */ | |||
void *thread(void *vargp) { | |||
int connfd = *((int *)vargp); //전달받은 void 포인터를 정수 포인터로 캐스팅해서 실제 connfd값 추출 | |||
Pthread_detach(pthread_self()); //해당 쓰레드를 detach하여, 쓰레드가 종료되면 자동으로 회수되도록 함 | |||
Free(vargp); //main에서 Malloc()한 메모리를 해제 → 이미 connfd를 저장했으므로 | |||
echo(connfd); //echo() 함수 실행 | |||
Close(connfd); //echo() 함수가 종료되면 연결을 종료 | |||
return NULL; | |||
} | |||
</syntaxhighlight> | |||
위는 thread-based echo 서버의 코드이고, 이는 전체적으로 process-based echo 서버의 코드와 비슷하다. 기본적으로 메인 쓰레드는 반복적으로 연결 요청을 기다리고, 그런 다음 그 요청을 처리하기 위해 피어 쓰레드를 생성하여 여러 클라이언트를 동시에 처리한다. 이때 각각의 클라이언트의 요청은 각각의 독립된 쓰레드에 의해서 처리된다. 이때 각 프로세스들은 스택과 TID를 제외한 모든 메모리 공간을 공유되므로, 지역 변수는 개별 스택에 저장되고, 충돌은 일어나지 않는다. | |||
코드 자체는 간단하지만, 몇 가지 미묘한 문제들이 존재한다. 첫 번째 문제는 <code>pthread_create()</code>를 호출할 때, 의도하지 않은 지역 변수 공유가 발생하는 문제이다. 가장 단순한 방법은 디스크립터에 대한 포인터를 전달하는 것으로, 아래와 같은 방식이다: | |||
<syntaxhighlight lang="c"> | |||
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen); | |||
Pthread_create(&tid, NULL, thread, &connfd); | |||
</syntaxhighlight> | |||
그런 다음, 피어 쓰레드는 이를 역참조하여 지역 변수에 할당한다: | |||
<syntaxhighlight lang="c"> | |||
void *thread(void *vargp) { | |||
int connfd = *((int *)vargp); | |||
... | |||
} | |||
</syntaxhighlight> | |||
하지만 이는 잘못된 방식이다. 왜냐하면 이는 피어 쓰레드 내의 할당문과 메인 쓰레드 내의 <code>accept()</code> 함수 호출 사이에 경쟁 조건(race condition)이 유발되기 때문이다. 만약 쓰레드 내의 할당문이 <code>accept()</code> 함수보다 먼저 실행된다면, 쓰레드 내의 지역 변수 connfd는 올바른 디스크립터 값을 얻는다. 그러나 만약 할당문이 새로운 연결 요청을 받은 <code>accept()</code> 함수보다 늦게 실행된다면, 원래의 쓰레드의 connfd 변수는 다음 연결에 해당하는 디스크립터의 번호를 얻게 된다. 그 결과, 두 개의 쓰레드가 동일한 디스크립터를 통해 연결을 수행하게 된다.<br> | |||
이러한 문제 상황을 피하기 위해서는 <code>accept()</code> 함수가 반환한 각 connected 디스크립터를 동적으로 할당한 메모리 블록에 저장해야 하며, 위 코드는 이러한 형태로 구현되어 있다. 또한 메모리 누수를 방지하기 위해서, 더불어 메인 쓰레드에서 할당되었던 메모리 블록도 쓰레드에서 반드시 free해야 한다. | |||
또한 메모리 누수 방지를 위해서 생성된 쓰레드들을 분리된(detached) 상태로 바꾸어야 한다. 이는 쓰레드들을 수거하는 작업이 명시되지 않았으므로, 시스템에 의해서 자동으로 수거되도록 해야 하기 때문이다. 그리고, thread-safe 함수만 사용해야 한다. 이는 여러 쓰레드가 동시에 호출해도 안전한 함수를 의미한다. | |||
===Pros and Cons of Thread-Based Designs=== | |||
Thread-based 설계의 장점은 각 쓰레드 간의 데이터 공유가 쉽다는 것이다. 쓰레드끼리는 힙, 전역 변수 등을 공유하므로, 로그 기록이나 파일 캐시등을 효율적으로 공유할 수 있다. 또한 쓰레드 생성/전환은 프로세스의 그것 보다 더욱 빠르고, 컨텍스트 스위칭 비용이 낮으므로, process-based 설계보다 더욱 효율적이라는 장점이 있다. | |||
하지만 쓰레드 사이에서 의도치 않은 데이터 공유가 발생하여 디버깅하기 힘든 오류가 발생할 수 있다. 쓰레드 간 공유가 쉬운 것이 장점인 동시에, 어떤 데이터가 공유되고 어떤 것이 독립적인지 헷갈릴 수 있으며, 이로 인해 race condition이 발생할 수 있다. | |||
==Threads for Concurrent Programming== | |||
===[[Synchronization]]=== | |||
자세한 내용은 [[Synchronization]] 문서를 참조해 주십시오. | |||
===A Concurrent Server Based on Prethreading=== | |||
[[Semaphore|세마포어]]의 개념은 프리스레딩(prethreading)이라는 기법에 적용될 수 있으며, 이 기법은 아래와 같이 구현된 concurrent 서버 코드를 통해 알아볼 수 있다: | |||
<syntaxhighlight lang="c"> | |||
#include "csapp.h" | |||
#include "sbuf.h" | |||
#define NTHREADS 4 | |||
#define SBUFSIZE 16 | |||
void echo_cnt(int connfd); | |||
void *thread(void *vargp); | |||
sbuf_t sbuf; //connfd를 저장하는 버퍼이며, 내부적으로 세마포어 사용 | |||
int main(int argc, char **argv) | |||
{ | |||
int i, listenfd, connfd; | |||
socklen_t clientlen; | |||
struct sockaddr_storage clientaddr; | |||
pthread_t tid; | |||
if (argc != 2) { | |||
fprintf(stderr, "usage: %s <port>\n", argv[0]); | |||
exit(0); | |||
} | |||
listenfd = Open_listenfd(argv[1]); //Open_listenfd()는 서버 소켓을 열고, listen()까지 진행 | |||
sbuf_init(&sbuf, SBUFSIZE); //sbuf를 초기화하고, listenfd만을 등록 | |||
for (i = 0; i < NTHREADS; i++) //NTHREADS만큼 스레드 생성해서 thread() 함수 실행. | |||
Pthread_create(&tid, NULL, thread, NULL); | |||
while (1) { | |||
clientlen = sizeof(struct sockaddr_storage); | |||
//클라이언트 요청이 오면 Accept()로 연결을 수락. | |||
connfd = Accept(listenfd, (SA*) &clientaddr, &clientlen); | |||
//수락한 결과 얻은 connfd를 sbuf에 등록하기 -> 나중에 스레드에서 처리 | |||
sbuf_insert(&sbuf, connfd); | |||
} | |||
} | |||
void *thread(void *vargp) | |||
{ | |||
Pthread_detach(pthread_self()); //스레드 종료 시 리소스를 자동 회수 | |||
while (1) { | |||
int connfd = sbuf_remove(&sbuf); //sbuf에서 connfd를 소비(provider-consumer) | |||
echo_cnt(connfd); //connfd를 통해 클라이언트의 요청을 처리 | |||
Close(connfd); //연결이 종료되면 connfd를 닫기 | |||
} | |||
} | |||
</syntaxhighlight> | |||
[[파일:Organization of a prethreaded concurrent server.png|섬네일|Figure 11. Organization of a prethreaded concurrent server|400x400픽셀]] | |||
위 코드에서 concurrent 서버는 새로운 클라이언트가 접속할 때마다 새로운 스레드를 생성한다. Concurrent Server 문서에 다룬 [[Concurrent Programming#A Concurrent Server Based on Threads|스레드 기반의 서버]]의 단점은 클라이언트마다 새 스레드를 만드는데 적지 않은 비용이 발생한다는 것이다. 하지만 위에서 제시된 prethreading 방식을 이용한 서버는 이러한 문제를 해결하기 위해서 figure 11에 제시된 생산자-소비자(Producer-Consumer) 모델을 사용하여 이러한 오버헤드를 줄이고자 한다. 이러한 모델에서 서버는 메인 스레드(main thread)와 작업 스레드(worker thread)로 구성된다. 메인 스레드는 반복적으로 클라이언트로부터의 연결 요청을 수락하고, 그로부터 생성된 connfd를 버퍼(sbuf)에 저장한다. 각 작업 스레드는 반복적으로 버퍼에서 디스크립터를 꺼내어서 클라이언트 서비스를 수행한 다음, 다음 connfd를 기다린다. 이는 위 코드에서 제시되었듯이, 아래와 같은 control flow를 가진다: | |||
* 메인 스레드의 경우 | |||
*# 버퍼 sbuf를 초기화 한 후, 작업 스레드 집합을 생성한다. | |||
*# 무한 루프에서 클라이언트로부터의 연결 요청을 수락하고, 생성된 connfd를 sbuf에 등록한다. | |||
* 각 작업 스레드의 경우 | |||
*# 버퍼에서 connfd를 꺼낼 수 있을 때까지 기다린다. | |||
*# <code>echo_cnt()</code> 함수를 호출하여 클라이언트의 입력을 echo한다. | |||
아래는 <code>echo_cnt()</code> 함수를 구현한 코드이다: | |||
<syntaxhighlight lang="c"> | |||
#include "csapp.h" | |||
static int byte_cnt; //서버가 지금까지 읽은 모든 바이트의 누적 합. | |||
static sem_t mutex; //byte_cnt를 여러 스레드가 동시에 접근하지 못하게 하는 세마포어 | |||
static void init_echo_cnt(void) //서버 실행 중 단 한 번만 호출되도록 보장된다. | |||
{ | |||
Sem_init(&mutex, 0, 1); //세마포어 mutex를 1로 초기화하여 사용한다. | |||
byte_cnt = 0; | |||
} | |||
//클라이언트 소켓(connfd)을 통해 라인 단위로 문자열을 echo한다. 동시에 총 수신 바이트 수(byte_cnt)를 세고 출력한다. | |||
void echo_cnt(int connfd) | |||
{ | |||
int n; | |||
char buf[MAXLINE]; | |||
rio_t rio; | |||
//init_echo_cnt()를 스레드 환경에서 한 번만 호출하도록 보장하는 구문 | |||
static pthread_once_t once = PTHREAD_ONCE_INIT | |||
Pthread_once(&once, init_echo_cnt); | |||
Rio_readinitb(&rio, connfd); //connfd를 통한 연결을 위해서 rio 버퍼를 초기화한다. | |||
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) { //클라이언트가 데이터를 보내는 동안 계속 읽음 | |||
P(&mutex); //mutex 세마포어를 통해서 byte_cnt를 보호 | |||
byte_cnt += n; //n은 이번에 읽은 바이트 수, 이를 byte_cnt에 추가 | |||
printf("server received %d (%d total) bytes on fd %d\n", n, byte_cnt, connfd); | |||
V(&mutex); //보호 해제 | |||
Rio_writen(connfd, buf, n); //이번 루프에서 읽어 들인 문자열을 출력 | |||
} | |||
} | |||
</syntaxhighlight> | |||
위에서 다룬 <code>echo_cnt()</code> 함수는 <code>echo()</code> 함수의 변형으로, 모든 클라이언트로부터 수신된 누적 바이트 수를 byte_cnt라는 전역 변수에 저장한다. 이 경우, 해당 함수를 구현하기 위해서는 byte_cnt 카운터(counter) 변수와 mutex 세마포어를 초기화하여야 한다. 하나의 접근 방식은 메인 스레드가 명시적으로 초기화 함수를 호출하는 것이다. 다른 접근 방식은 해당 코드에서의 구현과 같이 <code>pthread_once()</code> 함수를 사용하여, 어떤 스레드가 처음으로 <code>echo_cnt()</code> 함수를 호출할 때 초기화 함수가 호출되도록 하는 것이다. | |||
===Using Threads for Parallelism=== | |||
[[파일:Relationships between the sets of programs.png|섬네일|Figure 12. Relationships between the sets of programs]] | |||
요즘 나오는 컴퓨터들은 figure 6와 같은 멀티코어 프로세서를 가지고 있으며, 이는 concurrent programming을 더욱 빠르게 실행한다. 이는 OS 커널이 스레드들을 단일 코어에서 순차적으로 실행하는 대신, 멀티코어에서 병렬적으로 스케쥴링하여 처리하기 때문이다. 이러한 병렬성(parallelism)을 활용하는 것은 매우 중요하다. Figure 12는 sequential 프로그램, concurrent 프로그램, parallel 프로그램 사이의 집합 관계로 나눌 수 있다. 모든 프로그램은 sequential 프로그램과 concurrent 프로그램이라는 서로소 집합으로 나눌 수 있다. 이때 parallel 프로그램은 concurrent 프로그램의 진부분집합이다. 아래는 parallel 프로그램의 간단한 예시이다. | |||
<syntaxhighlight lang="c"> | |||
#include "csapp.h" | |||
#define MAXTHREADS 32 | |||
void *sum_mutex(void *vargp); //각 스레드가 실행할 함수의 프로토타임 | |||
long gsum = 0; // 모든 스레드가 각자 구한 부분합을 저장할 전역변수 | |||
long nelems_per_thread; // 각 스레드가 처리할 원소의 개수 | |||
sem_t mutex; // gsum에 대한 race condition을 막기 위한 세마포어 | |||
int main(int argc, char **argv) | |||
{ | |||
long i, nelems, log_nelems, nthreads, myid[MAXTHREADS]; | |||
pthread_t tid[MAXTHREADS]; | |||
/* Get input arguments */ | |||
if (argc != 3) { | |||
printf("Usage: %s <nthreads> <log_nelems>\n", argv[0]); | |||
exit(0); | |||
} | |||
nthreads = atoi(argv[1]); // nelems는 스레드의 개수 | |||
log_nelems = atoi(argv[2]); // 실제로 처리할 원소 수의 2의 로그 값 | |||
nelems = (1L << log_nelems); // 2^log_nelems을 통해 실제로 처리할 원소의 수 계산 | |||
nelems_per_thread = nelems / nthreads; | |||
sem_init(&mutex, 0, 1); //세마포어를 1로 초기화 | |||
/* Create peer threads and wait for them to finish */ | |||
for (i = 0; i < nthreads; i++) { | |||
myid[i] = i; // 각 스레드에게 부여되는 고유 인덱스 | |||
Pthread_create(&tid[i], NULL, sum_mutex, &myid[i]); // 스레드를 생성 | |||
} | |||
for (i = 0; i < nthreads; i++) | |||
Pthread_join(tid[i], NULL); //모든 스레드가 작업을 마칠 때까지 기다림 (동기화) | |||
/* Check final answer */ | |||
if (gsum != (nelems * (nelems - 1)) / 2) //오류 발생했는지 확인하기 | |||
printf("Error: result=%ld\n", gsum); | |||
exit(0); | |||
} | |||
/* Thread routine for psum-mutex.c */ | |||
void *sum_mutex(void *vargp) | |||
{ | |||
long myid = *((long *)vargp); //인자로 전달된 id 추출 | |||
//예를 들어, myid = 0: [0, 256), myid = 1: [256, 512) | |||
long start = myid * nelems_per_thread; /* Start element index */ | |||
long end = start + nelems_per_thread; /* End element index */ | |||
long i; | |||
for (i = start; i < end; i++) { | |||
P(&mutex); | |||
gsum += i; //gsum에 mutex를 이용하여 start ~ end까지의 수를 모두 덧셈 | |||
V(&mutex); | |||
} | |||
return NULL; | |||
} | |||
</syntaxhighlight> | |||
예를 들어 정수 0부터 n-1까지의 합을 병렬로 계산하는 상황을 생각하자. 가장 단순한 해결책은 스레드들이 mutex로 보호되는 공유 전역 변수에 합을 더하도록 하는 것이다. 이때 단순화를 위해 t개의 서로 다른 스레드들이 존재한다고 가정할 때, 0 ~ n까지의 각 구간은 n/t개의 원소를 가진다. 따라서 이를 구현하기 위해서는 <code>sum_mutex</code>를 통해서 스레드를 호출할 때 myid를 통해서 스레드에게 주어진 각 구간의 합을 공유 전역 변수에 더하도록 하면 된다. 이렇게 구현된 프로그램은 싱글 스레드로 실행할 때에도 매우 느릴 뿐 아니라, 여러 스레드로 병렬 실행할 경우 오히려 더욱 느려진다는 놀라운 결과를 보여준다. 사실 이는 당연한 결과이기도 하다. 왜냐하면 하나의 프로세스 내의 반복문 내에서 실행될 수 있었던 프로그램을, 더 많은 스레드를 이용하여 구현하는 것이며, 스레드가 많아질 수록 동기화 연산(P, V)<ref>동기화 연산(P, V)은 단일 메모리 업데이트에 비해 매우 비싸다.</ref>이 더욱 많이 사용되기 때문이다. 이는 아래와 같은 결론을 제시한다: | |||
동기화 오버헤드는 크므로 가능한 한 피해야 한다. | |||
피할 수 없다면, 한 번 동기화할 때마다 그 안에서 많은 일을 처리하도록 설계하여야 한다. | |||
이 예제에서 동기화를 피하는 한 가지 방법은 각 동료 스레드가 자신의 합을 각 스레드에 고유하게 할당된 메모리 공간에 저장하는 것이다. 아래는 이를 구현한 코드이다: | |||
<syntaxhighlight lang="c"> | |||
/* Thread routine for psum-array.c */ | |||
void *sum_array(void *vargp) | |||
{ | |||
long myid = *((long *)vargp); // 스레드 ID 추출 | |||
long start = myid * nelems_per_thread; /* Start element index */ | |||
long end = start + nelems_per_thread; /* End element index */ | |||
long i; | |||
for (i = start; i < end; i++) { | |||
psum[myid] += i; //myid를 통해서 각 스레드에 할당된 메모리 공간에 접근 | |||
} | |||
return NULL; | |||
} | |||
</syntaxhighlight> | |||
메인 스레드는 전역 배열 psum을 정의하고, 각 스레드 i는 psum[i]에 자신의 합을 누적시킨다. 이를 통해 각 스레드에게 고유한 메모리 위치를 제공할 수 있으며, 이를 통해 mutex를 통한 동기화로 전역 배열 psum을 보호할 필요가 없다. 단지 메인 스레드는 동기화를 통해 모든 작업 스레드가 종료되기를 기다릴 뿐이다. 이후 메인 스레드는 psum 벡터의 원소들을 합산하여 최종 결과를 얻는다. 이 psum-array 프로그램은 멀티코어 환경에서 실행하면, psum-mutex 프로그램보다 수십 배 빠르게 실행된다. | |||
또한 각 스레드가 자신의 계산 결과를 전역 배열 psum 대신 지역 변수에 누적시키는 변수에 누적시키는 방식을 활용할 수도 있다. 이는 아래와 같이 구현된다: | |||
<syntaxhighlight lang="c"> | |||
/* Thread routine for psum-local.c */ | |||
void *sum_local(void *vargp) | |||
{ | |||
long myid = *((long *)vargp); // 스레드 ID 추출 | |||
long start = myid * nelems_per_thread; /* Start element index */ | |||
long end = start + nelems_per_thread; /* End element index */ | |||
long i, sum = 0; | |||
for (i = start; i < end; i++) { | |||
sum += i; | |||
} | |||
psum[myid] = sum; | |||
return NULL; | |||
} | |||
</syntaxhighlight> | |||
이는 이전에 구현되었던 방식에 있었던 불필요한 메모리 참조를 줄임으로서 더욱 효율성을 높인 것이다. | |||
===Characterizing the Performance of Parallel Programs=== | |||
[[파일:Performance of psum-local-array.png|섬네일|Figure 13. Performance of psum-local/array]] | |||
Figure 13은 psum-array, psum-local 프로그램의 총 실행 시간을 스레드 수에 따라 나타낸 것이다. 각 경우에서 프로그램은 n = 2<sup>31</sup>이며, 4코어 환경에서 작동한다. 해당 figure에서 스레드의 숫자가 증가할 수록 실행시간이 감소하지만, psum-array 프로그램의 경우에는 스레드의 숫자가 증가할 경우에 오히려 실행 시간이 증가하기도 한다. 이상적인 경우, 실행 시간은 스레드 수가 증가함에 따라 선형적으로 감소한다. 즉, 스레드 수가 두 배가 되면 실행 시간은 절반이 되는 것이다. 하지만 실제로는 스레드의 수가 임계치(해당 예시에서는 4개)를 초과하면, 각 코어가 여러 스레드를 컨텍스트 스위칭하며 실행해야 하므로 실행 시간이 오히려 증가하는 것이다. 따라서 parallel 프로그램은 일반적으로 CPU의 각 코어가 하나의 스레드를 실행하도록 작성된다. | |||
절대적인 실행 시간이 어떤 프로그램의 성능을 측정하는 직관적이고 궁극적인 지표이지만, parallel 프로그램이 parallelism을 얼마나 잘 활용하는지를 보여주는 지표도 존재하며, 이를 parallel 프로그램의 속도 향상도(speedup)라고 한다. 이때 속도 향상도를 보는 첫 번째 관점은 strong scailing이다. strong scailing은 작업의 총량을 고정한 채로, pararell 처리에 사용할 프로세서(스레드) 수를 늘려가며 실행 시간을 줄이는 방식을 의미한다. 이러한 관점에서 속도 향상도는 아래와 같이 정의된다. | |||
<math>S_p=\frac{T_1}{T_p}</math> | |||
이때 <math>p</math>는 코어의 수, <math>T_k</math>는 k개가 있을 때의 실행 시간이다. 이때 <math>S_p</math>는 아래와 같이 갈린다: | |||
* <math>S_p</math>가 절대 속도 향상도(absolute speedup): <math>T_1</math>이 sequential 프로그램의 실행 시간일 때 | |||
* <math>S_p</math>가 상대 속도 향상도(absolute speedup): <math>T_1</math>이 parallel 프로그램의 실행 시간일 때 | |||
이때 절대 속도 향상도가 parallelism의 효과를 더욱 정확히 측정할 수 있는 지표이다. 왜냐하면 parallel 프로그램은 1개의 프로세서에서 실행할 때에도 동기화에 의한 오버헤드가 존재하며, 이는 상대 속도 향상도의 분자(<math>T_1</math>)를 인위적으로 키워서 수치를 잘못 해석할 수 있기 때문이다. 하지만 상대 속도 향상도는 굳이 해당 프로그램에 대한 sequential한 버전을 따로 만들 필요가 없으므로 더욱 간편하다는 장점이 있다. 이와 관련된 지표로 효율성(efficiency)가 있으며, 이는 아래와 같이 계산된다: | |||
* <math>E_p = \frac{S_p}{p} = \frac{T_1}{pT_p}</math> | |||
[[파일:Performance of psum-local.png|섬네일|Figure 14. Performance of psum-local]] | |||
이는 보통 0~100% 사이의 백분율로 표현되며, parallelism으로 인한 오버헤드를 측정한다. <math>E_p</math>가 100%에 가까울 수록 오버헤드가 적다는 것을 의미한다. Figure 14는 psum-local 프로그램에 대한 퍼포먼스를 나타낸 표이다. 해당 표를 분석하면 효율성이 그럭저럭 괜찮은 것을 볼 수 있다. 하지만 실제 코드를 구현할 경우에는 동기화가 더욱 복잡해지기 때문에 효율성을 높이는 것이 더욱 어려워진다. | |||
속도 향상도를 보는 다른 관점은 weak scailing이다. 이는 프로세서의 수를 늘릴 때 문제의 크기도 함께 늘려서, 각 프로세서가 처리하는 작업량이 일정하도록 하는 방식이다. 이 경우 속도 향상도와 효율성은 단위 시간당 수행된 총 작업량을 기준으로 측정된다. 예를 들어, 프로세서 수를 2배로 늘리고 처리하는 작업량도 2배로 늘렸을 때, 한 시간당 처리량이 두 배가 되면 선형적인 속도 향상도와 100% 효율을 얻는 것이다. | |||
===Memory Consistency=== | |||
메모리 일관성(Memory Consistency)에 대해서 설명하기 위해, 아래와 같은 간단한 예제 코드를 살펴보자: | |||
<syntaxhighlight lang="c"> | |||
//a, b는 전역 변수 | |||
int a = 1; | |||
int b = 100; | |||
Thread1: | |||
a = 2; // Wa: 변수 a에 대한 쓰기 | |||
print(b); // Rb: 변수 b에 대한 읽기 | |||
Thread2: | |||
b = 200; // Wb: 변수 b에 대한 쓰기 | |||
print(a); // Ra: 변수 a에 대한 읽기 | |||
</syntaxhighlight> | |||
[[파일:Sequential Consistency Example.png|섬네일|Figure 15. Sequential Consistency Example]] | |||
이때 위 프로그램을 실행시킨다면, 그 결과는 메모리 일관성을 구현하는 모델에 따라 달라진다. 즉, 하드웨어가 스레드 간 접근을 어떻게 처리하느냐에 따라 달라진다. 이때 병렬적으로 실행된 여러 스레드들의 명령 실행 결과가 마치 어떤 하나의 순차적으로 실행한 프로그램에서 나올 수 있다면, 해당 시스템은 순차적인 일관성(sequential consistency)를 가진다. 이때 모든 parallel 프로그램은 스레드 간 실행 순서가 임의로 섞일 수 있음에도, 순차적인 일관성을 보장해야 한다. 이때 스레드 일관성 제약 조건(Thread consistency constraints)이라는 개념이 대두되며 이는 각 스레드 내에서 명령이 실행되는 순서를 의미한다. 즉, <code>a = 2</code> 이후에 <code>print(b)</code>가 실행된다는 것이 보장된다. Figure 15는 위 코드에 대해 가능한 실행 순서와 출력 조합을 나열한 것이다. 헤딩 figure는 스레드 일관성 제약 조건에 따라 <code>Wa-Rb, Wb-Ra</code> 순서를 보존하며 실행된 결과들을 보여주고, 따라서 <code>(100, 1), (1, 100)</code>과 같은 결과들은 두 쓰레드가 모두 쓰기 작업을 하기도 전에 읽기 작업을 시작했다는 것을 의미하므로, 쓰레드 일관성 제약 조건을 어긴다. | |||
[[파일:Non-Coherent Cache Scenario.png|섬네일|Figure 16. Non-Coherent Cache Scenario]] | |||
하지만 <code>(100, 1), (1, 100)</code>과 같은 결과들은 캐시 일관성이 없는 시스템에서는 충분히 발생할 수 있다. Figure 16과 같이 각 스레드가 자기만의 write-back 캐시<ref>수정된 데이터를 메모리에 바로 쓰지 않고, 나중에 해당 데이터가 캐시에서 제거될 때만 메모리에 반영하는 캐시를 의미한다.</ref>를 가지고 있고, 캐시들끼리 연동(coherence)하지 않는 상황을 가정하자. 이때 Thread 1은 <code>a = 2, print(b)</code>명령어를 수행하고, Thread 2는 <code>b = 200, print(a)</code>를 실행한다. 하지만 이들은 자신만의 캐시 공간을 가지고 있으므로 Thread 1에게 b는 항상 100이고, Thread 2에게 a는 항상 1이다. 즉, Thread1과 Thread2가 서로를 인식하지 못한다. | |||
[[파일:Snoopy Caches(1).png|섬네일|Figure 17. Snoopy Caches(1)]] | |||
이러한 문제를 해결하기 위한 캐시 일관성 유지 기법 중 하나가 snoopy caches라고 하는 개념이다. 이는 아래와 같이 각 캐시 블록에 상태 태그를 부여한다: | |||
* Invalid (I): 사용 불가능 | |||
* Shared (S): 읽기만 가능, 여러 캐시에 공유 | |||
* Exclusive (E): 쓰기 가능, 오직 하나의 캐시에 의해서만 접근됨 | |||
[[파일:Snoopy Caches(2).png|섬네일|Figure 18. Snoopy Caches(2)]] | |||
이를 통해, 위의 코드의 Wa, Wb는 figure 17과 같이 메모리/캐시에 수행된다. 해당 figure와 같이 실행된 결과, 두 스레드 캐시가 <code>a = 2, b = 200</code>을 각각 보유하며, 캐시의 각 태크 블럭은 E 상태가 된다. 이때 Thread2가 a를 읽기 위해 bus를 통해 a의 값을 요청하면, Thread 1이 자기가 가지고 있는 a:2를 bus를 통해 전달하며, 해당 캐시 블록의 태그를 S로 바꾼다. 이와 마찬가지로 <code>b = 200</code>도 공유된다. 이는 figure 18에 나타나 있다. bus에는 메인 메모리도 연결되어 있지만, Thread 1의 캐시가 더욱 최신 메모리를 가지고 있기 때문에 Thread 1의 캐시가 Thread 2에게 전달되는 것이다. 이를 통해서 일관된 메모리 모델 유지가 가능케 할 수 있다. | |||
==Other Concurrency Issues== | |||
동기화는 매우 복잡한 문제이며, 상호 배제(mutual exclusion)과 생산자-소비자 동기화 기법은 동기화에 관련된 이슈들의 빙산의 일각일 뿐이다. 해당 문단에서는 동기화를 구현하기 위해서 기본적으로 점검해야할 기본적인 상황이다. 이때 설명은 기본적으로 스레드를 중심으로 이루어지지만, 대부분의 내용은 공유 자원에 접근하는 모든 concurrent flow에 대해서 해당된다. | |||
===Thread Safety=== | |||
스레드를 사용할 때는 스레드-안전(thread safe) 특성을 가진 함수를 작성해야 한다. 어떤 함수가 여러 개의 concurrently하게 실행 중인 스레드에서 반복적으로 호출되어도 항상 올바른 결과를 낸다면, 해당 함수는 스레드-안전 특성을 가진 것이다. 만약 그렇지 않다면, 즉 여러 스레드가 동시에 호출할 때 올바른 결과를 보장하지 않는 다면, 그 함수는 스레드-위험(thread-unsafe)하다고 한다. 스레드-위험한 함수는 네 가지 부류로 구분된다<ref>서로 겹칠 수 있는 부류들이다.</ref> | |||
먼저''' 공유 변수를 보호하지 않는 함수'''가 있다. 이는 공유 변수에 대한 적절한 동기화가 수행되지 않아 race condition을 가지고 있는 함수이다.<ref>스레드-안전하게 바꾸기 쉬우며, 단지 공유 변수를 P, V 등의 동기화 연산으로 보호하면 된다.</ref> 하지만 이 경우, 동기화 연산이 해당 함수의 실행 속도를 느리게 할 수 있다. | |||
또한 '''여러 번 호출될 때 내부적으로 상태(state)를 유지하고 이에 따라 실행되는 함수'''도 스레드-위험하다. 아래는 간단한 예시인 의사 난수 생성기(pseudorandom number generator)에 대한 코드이다: | |||
<syntaxhighlight lang="c"> | |||
unsigned next_seed = 1; | |||
/* rand - return pseudorandom integer in the range 0..32767 */ | |||
unsigned rand(void) | |||
{ | |||
next_seed = next_seed * 1103515245 + 12543; | |||
return (unsigned)(next_seed >> 16) % 32768; | |||
} | |||
/* srand - set the initial seed for rand() */ | |||
void srand(unsigned new_seed) | |||
{ | |||
next_seed = new_seed; | |||
} | |||
</syntaxhighlight> | |||
먼저, <code>rand()</code> 함수는 스레드-위험하다. 왜냐하면 현재 호출의 결과가 이전 호출의 중간 결과에 의존하기 때문이다. 단일 스레드에서는 <code>rand()</code>를 반복 호출하여 예측 가능한 난수열을 얻을 수 있지만, 여러 스레드에서 <code>rand()</code> 함수를 concurrently하게 호출하면 동일한 결과를 얻을 수 없다. 그 이유는 <code>rand()</code>는 내부적으로 seed 값과 같은 static 변수를 가지고 있으며, <code>rand()</code>를 여러 번 호출하면 이전 호출 결과를 기반으로 다음 값을 생성하기 때문이다. 즉 단일 스레드에서는 한 번에 하나씩 <code>rand()</code> 함수를 호출하므로, 내부의 static 변수가 안정적으로 업데이트될 수 있지만, 여러 스레드가 동시에 호출하면 해당 static 변수에 대해 race condition이 발생할 수 있기 때문이다. 이러한 함수를 스레드-안전하게 만들기 위한 유일한 방법은 static 변수를 사용하지 않도록 함수 자체를 다시 작성하는 것이다.<ref>이 경우, 해당 함수를 호출한 함수가 상태 정보를 인자로 넘겨야 한다.</ref><ref>이러한 방식은 해당 함수 뿐 아니라 호출자의 코드도 변경해야 하기 때문에, 대형 프로그램에서는 수정이 어렵다는 단점이 있다.</ref> | |||
세 번째로는 '''static 변수에 대한 포인터를 반환하는 함수'''가 있다. 예를 들어, <code>ctime(), gethostbyname()</code>과 같은 함수는 계산 결과를 static 변수에 저장하고 그 변수에 대한 포인터를 반환한다. 이러한 함수를 여러 스레드에서 concurrently하게 실행하면 호출한 스레드들이 하나의 동일한 메모리 공간을 공유하게 되므로, 언제든지 문제를 야기할 수 있다. 이를 해결할 수 있는 방식은 아래와 같은 두가지이다: | |||
* 함수를 다시 작성하여, 호출자가 결과를 저장할 변수의 주소를 전달하게 한다. | |||
* 함수가 복잡하거나 소스 코드가 없어서 수정이 어려운 경우, lock-and-copy 기법을 사용할 수 있다: | |||
** 해당 함수에 mutex를 연결하고, 호출 지점에서 mutex를 잠근 후 함수 호출 → 반환값을 개인 메모리에 복사 → mutex 해제 | |||
** 이 과정을 수행하는 래퍼 함수를 정의하여 기존의 함수 호출을 모두 교체하면 된다. 예를 들어, 아래는 ctime() 함수에 대해 lock-and-copy를 사용한 래퍼 함수이다: | |||
<syntaxhighlight lang="c"> | |||
/* lock-and-copy version */ | |||
char *ctime_ts(const time_t *timep, char *privatep) | |||
{ | |||
char *sharedp; | |||
P(&mutex); | |||
sharedp = ctime(timep); | |||
strcpy(privatep, sharedp); | |||
V(&mutex); | |||
return privatep; | |||
} | |||
</syntaxhighlight> | |||
마지막으로는 '''스레드-위험한 함수를 호출하는 함수'''가 있다. 이는 직관적으로 당연하며, 이는 호출한 스레드-위험한 함수 대신 스레드-안전한 함수를 대신 호출하여 해결할 수 있다. | |||
===Reentrancy=== | |||
[[파일:Relationships between the sets of functions.png|섬네일|Figure 19. Relationships between the sets of functions]] | |||
스레드-안전한 함수 중에서 재진입 가능한 함수(reentrant functions)라고 불리는 중요한 부류가 있다. 이는 여러 스레드에 의해서 호출될 때 공유 데이터를 전혀 참조하지 않는 특성을 가진다. 이때 '스레드-안전한'(thread-safe)이라는 말과, '재진입 가능한'(reentrant)이라는 용어가 동의어처럼 오용되기도 하지만, 둘은 명확한 기술적인 차이가 존재한다. Figure 19는 스레드-안전한 함수, 스레드-위험한 함수, 재진입 가능한 함수들 사이의 집합 관계를 보여준다. 모든 함수의 집합은 스레드-안전 함수와 스레드-안전하지 않은 함수라는 서로소(disjoint) 집합으로 나뉜다. 또한 재진입 가능한 함수의 집합은, 스레드-안전 함수 집합의 진부분집합(proper subset)이다. | |||
<syntaxhighlight lang="c"> | |||
//Not thread-safe, not re-entrant | |||
int tmp; | |||
int add(int a) { | |||
tmp = a; | |||
return tmp + 10; | |||
} | |||
</syntaxhighlight> | |||
<syntaxhighlight lang="c"> | |||
//Thread-safe but not re-entrant | |||
thread_local int tmp; | |||
int add(int a) { | |||
tmp = a; | |||
return tmp + 10; | |||
} | |||
</syntaxhighlight> | |||
<syntaxhighlight lang="c"> | |||
//Not thread-safe but re-entrant | |||
int tmp; | |||
int add(int a) { | |||
tmp = a; | |||
return a + 10; | |||
} | |||
</syntaxhighlight> | |||
<syntaxhighlight lang="c"> | |||
//Thread thread-safe and re-entrant | |||
int add(int a) { | |||
return a + 10; | |||
} | |||
</syntaxhighlight> | |||
재진입 가능한 함수는 일반적으로 재진입이 불가능한 스레드-안전 함수보다 효율적이다. 왜냐하면 동기화 연산을 전혀 필요로 하지 않기 때문이다. 또한 2번 부류에 속하는 스레드-위험한 함수를 스레드-안전하게 만드는 유일한 방법은 해당 함수를 재진입 가능하도록 다시 작성하는 것이다. | |||
<syntaxhighlight lang="c"> | |||
</syntaxhighlight> | |||
===Using Library Functions in Threaded Programs=== | |||
[[파일:Common thread-unsafe library functions.png|섬네일|400x400픽셀|Figure 20. Common thread-unsafe library functions]] | |||
대부분의 Linux 함수들, 그리고 <code>malloc(), free(), realloc(), printf(), scanf()</code>와 같은 표준 C 라이브러리에서 정의된 함수들은 대체로 스레드-안전하다. 단 몇가지 예외가 존재하며, figure 20은 위험한 함수들을 나용한 것이다. 아래는 이들 몇가지 함수들에 대한 설명이다: | |||
* <code>strtok()</code> 함수는 문자열을 파싱하기 위한 사용이 권장되지 않는 함수(deprecated)이다. | |||
* <code>asctime(), ctime(), localtime()</code> 함수는 시간과 날짜 형식 간 변환에 널리 사용되는 함수들이다. | |||
* <code>gethostbyaddr(), gethostbyname(), inet_ntoa()</code> 함수는 오래된 네트워크 프로그래밍 함수들로, 각각 재진입 가능한(reentrant) <code>getaddrinfo(), getnameinfo(), inet_ntop()</code> 함수들로 대체되었다. | |||
이 함수들 중 <code>rand(), strtok()</code> 함수를 제외하면, 대부분은 static 변수의 포인터를 반환하는 3번 부류에 속한다. 스레드 프로그램 내에서 이들 중 하나를 호출해야 하는 경우, 가장 권장되는 방식은 lock-and-copy 기법을 사용하는 것이다. 그러나 lock-and-copy 기법은 여러 가지 단점을 가진다: | |||
* 추가적인 동기화 연산이 프로그램 실행을 느리게 만든다. | |||
* 반환되는 포인터가 구조체 안에 또 구조체를 가진 복잡한 구조체인 경우, 전체 계층을 복사하려면 깊은 복사(deep copy)가 필요하다. | |||
* rand() 함수와 같이 호출 간 상태를 유지하는 2번 부류의 스레드-안전하지 않은 함수에는 lock-and-copy 방식이 적용되지 않는다. | |||
이러한 이유로, Linux 시스템은 대부분의 스레드-안전하지 않은 함수들에 대해 재진입 가능한(reentrant) 버전을 제공하며, 이러한 함수들의 이름은 항상 '_r' 접미사로 끝난다. 예를 들어, <code>asctime()</code> 함수의 재진입 가능한 버전은 <code>asctime_r()</code> 함수이다. | |||
===Races=== | |||
Race는 프로그램의 정확한 작동(correctness)이 어떤 스레드가 control flow 상의 지점 x에 도달하기 전에 다른 스레드가 다른 지점 y에 도달하는지에 따라 결정될 때 발생한다. Race는 보통 프로그래머가 스레드들이 실행 상태 공간을 어떤 특정한 경로로 따라갈 것이라고 가정하고, "스레드 기반 프로그램은 가능한 모든 실행 경로에 대해 올바르게 동작해야 한다"는 원칙을 잊을 때 발생한다. 이를 이해하기 위해서 아래와 같은 예제를 살펴보자: | |||
<syntaxhighlight lang="c"> | |||
/* WARNING: This code is buggy! */ | |||
#include "csapp.h" | |||
#define N 4 | |||
void *thread(void *vargp); | |||
int main() | |||
{ | |||
pthread_t tid[N]; | |||
int i; | |||
for (i = 0; i < N; i++) | |||
Pthread_create(&tid[i], NULL, thread, &i); //&i를 각 스레드에 인자로 넘기며, 이를 역참조하여 값을 읽음 | |||
for (i = 0; i < N; i++) | |||
Pthread_join(tid[i], NULL); //모든 스레드의 종료를 기다림 | |||
exit(0); | |||
} | |||
/* Thread routine */ | |||
void *thread(void *vargp) | |||
{ | |||
int myid = *((int *)vargp); | |||
printf("Hello from thread %d\n", myid); | |||
return NULL; | |||
} | |||
</syntaxhighlight> | |||
위에서 메인 스레드는 4개의 피어 스레드를 생성하고, 각각에 고유한 정수 ID에 대한 포인터를 전달한다. 각 동료 스레드는 자신에게 전달된 인자에서 ID를 지역 변수에 복사한 후 그 ID를 포함하는 메시지를 출력한다. 이는 매우 단순하지만, 이를 실제 시스템에서 실행하면 다음과 같은 결과가 출력될 수 있다: | |||
<syntaxhighlight lang="bash"> | |||
linux> ./race | |||
Hello from thread 1 | |||
Hello from thread 3 | |||
Hello from thread 2 | |||
Hello from thread 3 | |||
</syntaxhighlight> | |||
이 문제는 각 피어 스레드와 메인 스레드 사이의 race condition에 의해서 발생한다. 위의 결과가 나타날 떄에는 아래와 같이 주어진 코드가 작동한다: | |||
# 메인 스레드가 13번째 줄에서 동료 스레드를 생성할 때, 지역 스택 변수 i의 포인터를 인자로 전달한다. | |||
# 이 시점에서 루프 내에서의 i 증가와 인자를 역참조하여 할당하는 작업 사이에서 race가 시작된다. | |||
# 만약 피어 스레드가 메인 스레드가 i를 증가시키기 전에 역참조를 실행하면, myid는 올바른 ID를 얻게 된다. | |||
#* 하지만 그렇지 않으면, myid는 다른 스레드의 ID를 얻는다. | |||
Race condition의 가장 큰 문제는 해당 버그가 발생 여부가 커널이 스레드들을 어떻게 스케줄링하느냐에 달려 있다는 것이다. 따라서 이는 간헐적으로 발생할 수 있으며, 프로그래머는 해당 문제의 존재 사실 조차 모를 수 있다. 이러한 문제를 없애기 위해서는, 각 ID 정수에 대해 별도의 메모리 블록을 동적으로 할당하고, 그 블록에 대한 포인터를 스레드 루틴에 전달하면 된다. 또한, 메모리 누수를 피하기 위해, 스레드 루틴은 그 블록을 반드시 해제(free)해야 한다. 이는 아래와 같이 코드를 수정함으로서 달성될 수 있다: | |||
<syntaxhighlight lang="c"> | |||
#include "csapp.h" | |||
#define N 4 | |||
void *thread(void *vargp); | |||
int main() | |||
{ | |||
pthread_t tid[N]; | |||
int i, *ptr; | |||
for (i = 0; i < N; i++) { | |||
ptr = Malloc(sizeof(int)); | |||
*ptr = i; | |||
Pthread_create(&tid[i], NULL, thread, ptr); | |||
} | |||
for (i = 0; i < N; i++) | |||
Pthread_join(tid[i], NULL); | |||
exit(0); | |||
} | |||
/* Thread routine */ | |||
void *thread(void *vargp) | |||
{ | |||
int myid = *((int *)vargp); | |||
Free(vargp); | |||
printf("Hello from thread %d\n", myid); | |||
return NULL; | |||
} | |||
</syntaxhighlight> | |||
<syntaxhighlight lang="bash"> | |||
linux> ./norace | |||
Hello from thread 0 | |||
Hello from thread 1 | |||
Hello from thread 2 | |||
Hello from thread 3 | |||
</syntaxhighlight> | |||
===Deadlocks=== | |||
[[파일:Progress graph for a program that can deadlock.png|섬네일|Figure 21. Progress graph for a program that can deadlock]] | |||
세마포어는 deadlock을 발생시킬 수 있는 잠재성을 지니다. Deadlock이란, 여러 스레드가 어떤 조건을 기다리며 모두 블락(block)되어 있고, 해당 조건은 절대 참이 되지 않는 문제이다. Figure 21은 두 개의 세마포어를 상호 배제(mutual exclusion)을 위해서 사용하는 두 스레드에 대한 진행 그래프이다. 해당 figure가 암시하는 코드를 작성하는 프로그래머는 P와 V 연산을 잘못된 순서로 작성하여, 두 세마포어에 대한 금지 영역(forbidden regions)이 겹치게(overlap) 만들었다. 이때 어떤 실행 경로가 교착 상태 지점 d에 도달하게 되면, 더 이상의 진행이 불가능해진다. 왜냐하면 겹쳐진 금지 영역들이 모든 합법적인 방향으로의 진행을 차단하기 때문이다. 해당 프로그램은 deadlock에 봉착한 것이며, 각 스레드는 다른 스레드가 수행할 V 연산을 기다리고 있지만, 그 연산은 절대로 일어나지 않는다. 이 겹쳐진 금지 영역들은 deadlock 영역이라는 상태 집합을 형성하며, 이는 어떤 실행 경로가 해당 deadlock 영역에 진입하며, deadlock을 겪는 다는 것을 의미한다. 이에 따라 프로그램은 deadlock 영역에는 진입할 수 있지만, 그로부터 탈출할 수는 없다. | |||
Deadlock의 큰 문제 중 하나는 예측 불가능하기 때문이다. 운이 좋으면 프로그램이 deadlock을 비껴나가서 실행될 수도 있겠지만, 어떤 경우에는 그렇지 않다. Figure 21은 이를 잘 보여준다. 또한 재현이 어렵기 때문에, 디버깅하기에도 어렵다. | |||
[[파일:Progress graph for a deadlock-free program.png|섬네일|Figure 22. Progress graph for a deadlock-free program]] | |||
프로그램이 deadlock에 빠지는 원인은 다양하지만, figure 22와 같이 이진(binary) 세마포어를 상호 배제를 위해 사용할 경우에는 다음과 같은 간단한 규칙을 적용하여 이를 회피할 수 있다: | |||
모든 뮤텍스들에 대해 total ordering이 주어졌을 때, | |||
프로그램은 각 스레드가 뮤텍스를 그 순서대로 획득하고, 역순으로 해제해야 한다. | |||
예를 들어 figure 21에서의 deadlock은 각 스레드가 먼저 s를 잠그고, 그 다음 t를 잠그도록 수정하여 해결할 수 있다. 이렇게 변경된 프로그램에 대한 진행 그래프는 figure 22과 같다: | |||
==각주== | ==각주== | ||
[[분류:컴퓨터 시스템]] | [[분류:컴퓨터 시스템]] | ||
2025년 6월 19일 (목) 09:16 기준 최신판
상위 문서: 컴퓨터 시스템
개요
컴퓨터 공학에서, 동시성(concurrent)이란 control flow들이 시간상으로 겹치는 것을 의미한다. 이는 컴퓨터 시스텀의 여러 계층에서 나타나며, OS 커널이 여러 애플리케이션을 실행하기 위해 사용하는 메커니즘 중 하나이다. 하지만 concurrent라는 개념은 애플리케이션 수준에서도 적용되어 아래와 같이 사용될 수 있다:
- 느린 I/O 장치에 접근: I/O 장치는 상대적으로 느리게 실행되며, 이에 따라 CPU는 커널이 해당 작업을 수행하는 동안 다른 프로세스를 실행한다.
- 사람과의 상호 작용: 컴퓨터를 사용하는 사람들은 동시에 여러 작업을 수행하기를 원하며, 이를 지원하기 위해 concurrent 개념이 사용된다.
- 여러 네트워크 클라이언트 처리: Iterative server는 사실상 현실적이지 않은 서버이다. 이에 따라 concurrent 개념을 사용하여 각 클라이언트에 대해 별도의 control flow를 통해 처리할 수 있어야 한다.
- 멀티코어 머신에서의 병렬 계산: 요즘 최신 시스템은 여러 CPU로 구성된 멀티코어 프로세서를 사용한다. 여러 control flow를 활용하는 애플리케이션은 멀티코어 프로세서를 통해 더욱 빠르게 실행될 수 있는데, 이는 각각의 flow들이 교대로 실행되는 것이 아니라 병렬적으로 실행되기 때문이다.
애플리케이션 수준의 동시성을 사용하는 애플리케이션을 concurrent program이라고 하며, 현대의 OS는 이를 만들기 위해 세 가지 접근 방식을 기본적으로 제공한다:
- Process-based: 각각의 control flow를 커널이 스케쥴링하고 관리하는 하나의 프로세스로 다룬다.
- 이때 프로세스는 서로 다른 가상의 주소 공간을 가지므로, 서로 통신하기 위해서는 명시적인 프로세스 간 통신(IPC) 메커니즘을 사용해야 한다.
- Event-based: 애플리케이션이 하나의 프로세스 내에서 control flow들을 명시적으로 스케쥴링하는 방식이다.
- 이때 control flow는 FSM으로 모델링되며, 파일 디스크립터에서 데이터가 도착함에 따라 메인프로그램이 상태를 전이시키며, 이를 위해서 I/O multiplexing이라는 기술을 사용한다.
- 이 방식은 하나의 프로세스로 구성되어 있기 때문에 모든 flow들이 하나의 주소 공간을 공유한다.
- Thread-based: 해당 방식에서는 커널이 단일 프로세스 내에서 실행되는 thread들을 자동으로 관리한다.
- 이 방식은 process-based 방식과 같이 커널에 의해서 스케쥴링되면서, 동시에 event-based 방식과 같이 하나의 프로세스 내에서 같은 주소 공간을 공유한다는 점에서 하이브리드 방식이라고 볼 수 있다.
Iterative Servers

Iterative 서버(server)는 여러 클라이언트의 요청을 하나씩 순차적으로 처리하는 서버이다. 이러한 서버의 control flow는 figure 1에 잘 나타나있다. Figure 1은 다음과 같은 control flow를 설명하고 있다:
- Client 1이 서버에
connect()함수를 호출하여 연결을 요청하고, 서버가 이를accept()한다. - Client 1이
write()함수를 호출하여 데이터를 서버로 전송한다. - 서버가
read()함수를 통해 전송된 데이터를 읽고, 이를 처리하여write()함수를 통해서 client 1에게 데이터를 전송한다. - Client 1은 연결을
close()하고, 서버는 비로소 client 2의 연결 요청을accept()한다.
이를 client 2 입장에서 control flow를 다시 살펴보면, 다음과 같다:
connect(): 서버는 클라이언트의 연결 요청을 listen backlog 큐에 저장하고, 이에 따라connect()함수는 즉시 반환된다.- 클라이언트가
connect()함수를 호출했을 때, 클라이언트는 SYN 패킷을 서버로 보내고, 서버는 이에 대한 응답으로 ACK 패킷을 보낸다. - 클라이언트는 서버로부터 ACK 패킷을 받고, 최종 ACK 패킷을 다시 서버로 보내고 handshake를 완료한다.
- 이 상태에서 서버의 커널은 연결을 listen backlog 큐에 저장해두며, 서버가 나중에
accept()함수를 호출했을 때 해당 큐에서 연결을 하나 꺼내와서 처리한다. - 즉, 서버는 연결을 즉시 수락하지 않으며, 보류된 연결로서 큐에 저장한다. 다른 의미로 보면,
accept()함수는 이 큐에서 연결 하나를 꺼내는 함수이다.
- 클라이언트가
rio_writen(): 데이터를 클라이언트 TCP 소켓 버퍼에 작성하고, 커널이 이를 서버로 전송힌다.- 클라이언트의 I/O 동작은 서버의 상태와는 무관하게 동작하므로,[1] 해당 함수를 호출한 즉시 반환된다.
rio_readlineb(): 해당 함수는 서버가 연결을 실제로 accept() 하기 전까지 블로킹(blocking)된다.- 이는 서버가 아직 client 1과 통신 중이기 때문에 client 2의 요청을 아직 처리하지 않았기[2] 때문이다.
이러한 관점에서 볼 때, client 2는 매우 큰 불편함을 겪는다고 볼 수 있다. 또한 client 1이 서버와의 상호작용 도중 잠시 자리를 비운다면, 해당 서버는 그 동안 어떤 작업도 수행하지 않으므로 매우 큰 비효율성이 초래된다. 즉, 이에 대한 해결책이 필요하며, 그것이 바로 concurrent server이다.
Concurrent Programming with Processes
Concurrent 프로그래밍의 가장 단순한 방법은 fork(), exec(), waitpid()와 같은 함수들을 사용해 프로세스를 통해 구현하는 것이다. 예를 들어 concurrent 서버를 구축하는 방식 중 하나는 부모 프로세스에서 클라이언트의 연결 요청을 수락하고, 그 후에 각각의 클라이언트마다 새로운 자식 프로세스를 생성하여 서비스를 제공하는 것이다.
- Figure 2
-
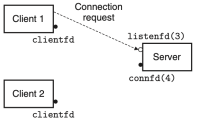 Figure 2.1. Server accepts connection
Figure 2.1. Server accepts connection -
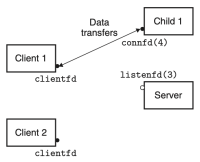 Figure 2.2. Server forks a child
Figure 2.2. Server forks a child -
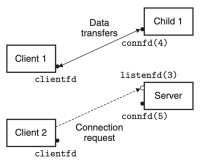 Figure 2.3. Server accepts another connection
Figure 2.3. Server accepts another connection -
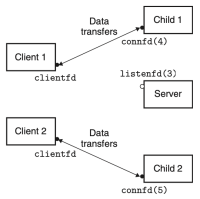 Figure 2.4. Server forks another child
Figure 2.4. Server forks another child




이 방식이 어떻게 작동하는지 살펴보기 위해, 두 개의 클라이언트와 하나의 서버가 있고, 서버가 listening 디스크립터(예: listenfd(3))을 통해 연결 요청을 기다린다고 가정하자. 클라이언트 1이 먼저 서버에게 연결 요청을 보낸다면, 서버는 해당 요청을 수락하고 connected 디스크립터(예: connfd(4))를 반환한다. 해당 요청을 수락한 후, 서버는 자식 프로세스를 fork()하고, 해당 자식 프로세스는 서버의 디스크립터 테이블의 전체 복사본을 가진다. 따라서 자식은 listenfd(3)를 닫고, 부모는 connfd(4)를 닫는다. 이때, 부모 자식의 connfd는 동일한 파일 테이블 항목을 가리키므로, 부모가 자신의 connfd를 반드시 닫아야 한다. 만약 그렇지 않다면, 해당 connfd의 파일 테이블 항목은 삭제되지 않고, 결과적으로 메모리 누수(memory leak)가 발생하여, 가용 메모리를 모두 소비하고 시스템이 다운될 수 있다.
부모가 클라이언트 1을 위해 자식을 생성한 이후, 클라이언트 2가 새로운 연결 요청을 보낸다고 하자. 그러면 서버는 연결 요청을 수락하고, connfd(5)를 반환한다. 이후 부모는 또 다른 자식 프로세스를 fork()하고, 이 자식 프로세스는 connfd(5)를 이용해 클라이언트 2에게 서비스를 제공한다. 이 시점에서, 부모는 다음 연결 요청을 기다리고 있으며, 두 자식은 각자의 클라이언트를 동시(concurrently)에 서비스하고 있다. 이 모든 과정들은 figure 2에 잘 나타나 있다.
이렇게 구현된 서버는 아래와 같은 특징들을 가진다:
- 각 클라이언트는 자기 전용 자식 프로세스에 의해 처리된다.
- 자식 프로세스들끼리는 메모리 등을 공유하지 않는다.
즉, 안전하고 구조가 명확하지만 프로세스 자원이 많이 소모된다는 단점이 있다.
Process-Based Concurrent Echo Server
아래는 process-based concurrent 서버의 간단한 예시를 보여준다. 이때 아래 코드에서 나온 echo() 함수는 Network Programming 문서에서 설명된 코드를 그대로 사용하였다:
#include "csapp.h"
void echo(int connfd);
void sigchld_handler(int sig)
{
while (waitpid(-1, 0, WNOHANG) > 0); //모든 좀비 프로세스를 수거한다.
return;
}
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
Signal(SIGCHLD, sigchld_handler); //SIGCHLD에 대한 시그널 핸들러 등록
listenfd = Open_listenfd(argv[1]); //argv[1]에 해당하는 포트 번호로 서버용 소켓을 열고 bind, listen
while (1) {
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen); ////클라이언트가 연결 요청을 보내면 수락, connfd 생성
if (Fork() == 0) {
Close(listenfd); //자식 프로세스는 listeing 디스크립터가 필요없으므로 닫는다.
echo(connfd); //echo() 함수를 통해 서버와 통신한다.
Close(connfd); //해당 connfd를 다 썼으므로 닫는다.
exit(0);
}
Close(connfd); //서버는 해당 connfd가 필요없으므로 닫는다.
}
}
위 코드를 기반으로하는 서버는 몇가지 주의 사항을 가진다. 먼저 서버는 일반적으로 장기간 실행되므로, 좀비 프로세스를 수거하는 SIGCHLD 핸들러를 반드시 포함하여야 한다. 이때 리눅스의 시그널을 큐잉되지 않으므로, SIGCHLD 핸들러는 여러 좀비 프로세스들을 한번에 수거할 수 있어야 한다. 그리고, 부모와 자식은 각자의 connfd 복사본을 반드시 닫아야 한다. 특히 부모가 자신의 connfd 복사본을 닫지 않으면 메모리 누수가 생길 수 있다. 마지막으로, 소켓의 파일 테이블 내의 reference count 때문에, 부모 자식 모두의 connfd 복사본이 닫힐 때까지 클라이언트와의 연결은 종료되지 않는다.
Pros and Cons of Process-based Servers
Process-based 방식은 부모 프로레스와 자식 프로세스 사이에서 명확하게 정의되는 공유 모델을 가지고 있다. 파일 테이블은 공유하지만, 파일 디스크립터와 전역 변수들은 서로 공유하지 않는다. 이는 간단하고 직관적이므로 장점이라고 볼 수 있다. 또한 프로세스 마다 주소 공간이 분리되어 있다는 특징을 가지고 있는데, 이는 장점이자 단점이다. 이는 하나의 프로세스가 실수로 다른 프로세스의 가상 메모리를 덮어쓰는 것이 불가능하게 만들며, 이는 여러 오류들을 없애 준다. 하지만 주소 공간이 분리되어 있으므로, 프로세스 사이에서의 정보 공유가 더욱 어려워지며 서로 정보를 공유하기 위해서는 명시적인 IPC(interprocess communications) 메커니즘을 사용해야 한다. 또 다른 단점은, 프로세스 제어와 IPC에 추가적인 오버헤드가 발생하여 속도가 느려지는 경향이 있다는 것이다.
Concurrent Programming with I/O Multiplexing
사용자가 Standard I/O에 입력한 대화형 명령에도 응답할 수 있도록 해야 한다면, 서버는 동시에 아래 두가지 I/O 이벤트를 처리해야 한다:
- Standard I/O을 통해 터미널에서 사용자의 입력을 받는 작업
- 네트워크 클라이언트로부터의 전송된 연결 요청을 처리하는 작업
위 둘중에서 어떤 이벤트를 우선적으로 처리해야 하는지는 확실하지 않다. 서버가 accept() 함수를 통해 클라이언트로부터의 연결 요청을 기다린다면, standard I/O로부터의 입력 명령어에는 응답할 수 없다. 마찬가지로 서버가 read() 함수를 통해서 입력 명령어를 기다리고 있다면, 네트워크 클라이언트로부터의 연결 요청을 처리할 수 없다.
이러한 딜레마에 대한 하나의 해결책은 I/O multiplexing이라 불리는 기법이다. 서버는 기본적으로 여러 디스크립터를 가지고 있다. 이때 핵심적인 아이디어는 어떤 서버에 대해 프로세스를 여러 개 만드는 대신, 하나의 프로세스가 여러 소켓을 감시하며 이벤트가 발생한 것만 처리하는 방식이다. 이는 대략적으로 아래와 같은 반복 루프를 이용한다:
- connfd와 listenfd 중 어떤 파일 디스크립터에 읽을 수 있는 데이터가 준비되었는지를 확인한다.
- listenfd에 데이터가 있다면, 새로운 클라이언트 연결 요청이 들어왔다는 뜻이다.
- 이 경우
accept()함수를 호출하여 새 연결을 수락하고, connfd[] 배열에 새로운 connfd[]를 등록한다.
- 이 경우
- 프로세스는 connfd[] 배열을 검사하여 입력이 존재하는 것만 찾아서 처리한다.
이때 여러 파일 디스크립터에 대해서 I/O 이벤트를 감시하는 것은 select(), epoll() 함수들을 사용한다. 해당 함수들은 커널이 프로세스를 잠시 중단(block)시키고, 여러 파일 디스크립터에 대해 I/O 이벤트를 감시하도록 한다. 이때 하나 이상의 이벤트가 생기면 깨어나서 처리하도록 한다. 즉, I/O multiplexing을 간단하게 설명하면, select(), epoll() 함수를 사용하여 커널로 하여금 프로세스를 중지(suspend)시키고, 하나 이상의 I/O 이벤트가 발생했을 때, control을 애플리케이션으로 이전하는 것이다.
- 디스크립터 집합 {0, 4} 중 하나가 읽을 수 있는 상태가 되면 반환된다.
- 디스크립터 집합 {1, 2, 7}에 대해 하나가 쓸 수 있는 상태가 되면 반환된다.
- select()는 최대 152.13초 동안 I/O 이벤트를 기다리며, 그 시간 안에 아무 이벤트도 발생하지 않으며, 타임아웃 상태가 되며, 0을 반환한다.
#include <sys/select.h>
int select(int n, fd_set *fdset, NULL, NULL, NULL);
FD_ZERO(fd_set *fdset); // fdset의 모든 비트를 0으로 초기화
FD_CLR(int fd, fd_set *fdset); // fdset에서 해당 fd 비트를 지움
FD_SET(int fd, fd_set *fdset); // fdset에서 해당 fd 비트를 켬
FD_ISSET(int fd, fd_set *fdset); // 해당 fd가 fdset에 포함되어 있는지 검사
논리적으로, 디스크립터 집합은 아래와 같은 n개의 비트 벡터로 생각할 수 있다.
bn−1, ..., b1, b0
각 비트 bk는 디스크립터 k에 해당하며, 디스크립터 k가 집합의 멤버인 경우에만 bk = 1이다. select() 함수가 받는 두 개의 인자는 read set이라고 불리는 디스크립터 집합과, 해당 집합의 크기[3]를 의미한다. select() 함수는 읽을 준비가 된 디스크립터가 하나 이상 생길 때까지 프로세스를 블록(block)하며, 어떤 I/O 이벤트가 발생하였을 때 I/O 작업에 대해 준비된 디스크립터의 개수를 반환한다.[4] 디스크립터 k가 읽을 준비가 되었다는 뜻은, 해당 디스크립터에서 1바이트를 읽으려는 요청이 블록되지 않는 경우를 의미한다.[5]
부가적인 효과로 select() 함수는 인자로 전달된 fd_set을 수정하여, read set의 부분 집합인 ready set을 표시한다. 이 ready set은 실제로 읽을 준비가 된 디스크립터들로 이루어지며, 함수의 반환값은 이 ready set의 크기를 의미한다. 주의할 점은, fd_set이 변경되기 때문에 select() 함수를 호출할 때마다 읽기 집합을 갱신해야 한다는 것이다.
Iterative server using I/O multiplexing
아래는 select() 함수를 사용하여 standard I/O로부터 사용자의 명령어를 받을 뿐 아니라, 클라이언트로부터의 연결도 받는 iterative echo 서버를 구현한 예시 코드이다:
#include "csapp.h"
void echo(int connfd);
void command(void);
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
fd_set read_set, ready_set;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]); //listening 소켓을 열고 bind, listen
//read_set은 감시할 디스크립터 집합이며, 이는 고정되어 있다.
FD_ZERO(&read_set); //빈 파일 디스크립터 집합 생성
FD_SET(STDIN_FILENO, &read_set); //표준 입력(stdin) 디스크립터 0 추가
FD_SET(listenfd, &read_set); //listening 디스크립터 3 추가
while (1) {
ready_set = read_set; //원래의 read_set으로 복구한다.
//accept() 함수를 호출해 연결 요청을 기다리는 대신 select() 함수를 호출하여 I/O 이벤트를 감시
Select(listenfd+1, &ready_set, NULL, NULL, NULL);
if (FD_ISSET(STDIN_FILENO, &ready_set)) //Standard I/O에 명령어가 입력되었을 때
command(); //stdin으로부터 명령어를 읽는다.
if (FD_ISSET(listenfd, &ready_set)) { //클라이언트로부터의 연결 요청이 들어왔을 때
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
echo(connfd); //connfd 디스크립터를 이용해 클라이언트와 상호 작용
Close(connfd);
}
}
}
void command(void) { //터미널에 입력된 사용자 명령어를 읽어들이는 함수이다.
char buf[MAXLINE];
if (!Fgets(buf, MAXLINE, stdin)) exit(0); //EOF를 만난 경우 exit
printf("%s", buf); //사용자 명령어 출력
}


_returns_fd_set_when_user_types_%22Enter%22.png)
위 코드에서는 open_listenfd() 함수를 사용하여 listening 디스크립터를 열고, FD_ZERO() 매크로 함수를 이용하여 빈 디스크립터 집합을 만든다. 그 다음의 두 줄에서는 read set에 stdin 디스크립터 0과 listening 디스크립터 3을 추가한다. 이때의 read set은 figure 3, 4와 같이 나타난다.
그 이후의 반복 루프 내에서는 accept()를 호출해 연결 요청을 기다리는 대신, select() 함수를 호출하여 listening 디스크립터 또는 stdin 중 어느 하나라도 읽을 준비가 될 때까지 블록한다. 예를 들어, 사용자가 Enter 키를 눌렀다면 stdin 디스크립터가 읽을 준비가 되므로, 이때 select() 함수는 figure 4와 같은 준비 집합을 반환한다. select() 함수가 반환되며, FD_ISSET() 매크로 함수를 사용하여 어떤 디스크립터가 읽을 준비가 되었는지를 확인한다. stdin이 준비되었으면, command() 함수를 호출하여 입력을 읽고, 파싱하고, 명령에 응답한 후 다시 반복문을 진행한다. Listening 디스크립터가 준비되었다면, accept() 함수를 호출하여 connected 디스크립터를 얻고, 이를 바탕으로 echo() 함수를 통해서 클라이언트가 자신의 연결을 닫을 때까지 전송된 각 줄을 읽고 다시 돌려보낸다.
해당 프로그램은 select() 함수를 사용하는 좋은 예이지만, 여전히 아쉬운 점이 있다. 문제는 클라이언트와 연결되면, 클라이언트가 자신의 연결을 닫을 때까지 서버는 해당 연결에 구속된다는 것이다. 따라서 이 상태에서 stdin을 통해서 명령어를 입력하면, 클라이언트와의 연결이 종료될 때까지 해당 명령어를 실행할 수 없다.
I/O Multiplexed Event Processing

I/O multiplexing은 특정한 이벤트의 결과를 통해서 흐름이 진행되는 concurrent event-driven 프로그램에 대한 기본적인 기법으로 사용될 수 있다. Figure 6는 concurrent event-driven echo 서버의 논리적인 흐름(logical flow)를 나타내는 FSM이다. 서버는 새로운 클라이언트 k에 대해, 새로운 FSM을 생성하고 이를 connected 디스크립터 dk와 연관시킨다. Figure 6에서 알 수 있듯이, FSM sk는 하나의 상태(state)[6], 하나의 입력 이벤트(event)[7], 하나의 전이(transition)[8]만을 가진다. 서버는 select() 함수를 사용한 I/O multiplexing을 통해서 입력 이벤트의 발생을 감지한다. 각각의 connected 디스크립터가 읽기를 준비할 때마다, 서버는 해당 상태 기계의 전이를 실행한다. 아래는 이와 같은 메커니즘을 이용한 concurrent event-based echo 서버의 예시 코드이다:
#include "csapp.h"
typedef struct {
int maxfd; //read set 배열 내에서 최대 인덱스
int maxi; //clientfd 배열 내에서 최대 인덱스
fd_set read_set; //현재 서버가 감시할 모든 디스크립터 집합
fd_set ready_set; //select()에 의해 읽기 준비된 디스크립터 집합
int nready; //select() 함수를 통해 준비가 되어 있는 디스크립터들의 수
int clientfd[FD_SETSIZE]; //연결된 클라이언트의 소켓 디스크립터들
rio_t clientrio[FD_SETSIZE]; //Rio_readlineb()을 위한 읽기 버퍼들
} pool; //활성화된 클라이언트들의 집합을 관리하는 구조체
int byte_cnt = 0; //서버가 읽어들인 총 바이트 수
int main(int argc, char **argv) {
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
static pool pool;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]); //listening 소켓을 열고 bind, listen
init_pool(listenfd, &pool); //pool 구조체 초기화
while (1) {
//select() 호출 → 리슨 소켓 또는 클라이언트 소켓에서 읽기 가능한 상태가 올 때까지 대기
pool.ready_set = pool.read_set;
pool.nready = Select(pool.maxfd+1, &pool.ready_set, NULL, NULL, NULL);
//listenfd가 준비되었다면 클라이언트가 연결 요청을 한 것
if (FD_ISSET(listenfd, &pool.ready_set)) {
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
add_client(connfd, &pool);
}
//연결된 클라이언트 중에서 select() 함수를 통해 준비가 감지된 소켓에서 echo() 수행
check_clients(&pool);
}
}
위 코드에서 read set 집합은 poop이라는 구조체로 관리된다. 서버는 main 함수 내에서 init_pool() 함수를 호출해 pool을 초기화한 후, 무한 루프에 진입한다. 해당 무한 루프 내에서 서버는 select() 함수를 호출하여 두 가지의 입력 이벤트를 감지한다. 하나는 새로운 클라이언트로부터 연결 요청을 받는 것이고, 다른 하나는 기존 클라이언트에 연결된 connfd가 읽기 준비가 된 경우이다. 새 클라이언트로부터 연결 요청을 감지하면 서버는 Accept() 함수를 호출하여 연결을 열고, add_client() 함수를 호출하여 클라이언트를 pool 구조체를 통해 등록한다. 마지막으로 서버는 check_clients() 함수를 호출해 준비된 각 connected 디스크립터로부터 한 줄의 텍스트를 echo한다.
void init_pool(int listenfd, pool *p) {
int i;
p->maxi = -1;
for (i = 0; i < FD_SETSIZE; i++) //clientfd 배열의 원소 비활성화
p->clientfd[i] = -1;
p->maxfd = listenfd;
FD_ZERO(&p->read_set);
FD_SET(listenfd, &p->read_set); //초기 read_set의 유일한 원소는 listenfd
}
init_pool() 함수는 pool 구조체를 초기화한다. clientfd 배열은 연결된 디스크립터의 집합을 나타내며, 정수 -1은 사용 가능한 슬롯을 뜻한다. 초기에는 clientfd 배열은 비어 있고, read_set 배열은 listenfd 디스크립터 하나를 저장한다.
void add_client(int connfd, pool *p)
{
int i;
p->nready--;
for (i = 0; i < FD_SETSIZE; i++) {
if (p->clientfd[i] < 0) { //비어있는 clientfd 배열 항목 찾기
p->clientfd[i] = connfd; //비어있는 clientfd 배열 항목에 connfd 등록
Rio_readinitb(&p->clientrio[i], connfd);
FD_SET(connfd, &p->read_set); //pool 구조체에 connfd 등록
if (connfd > p->maxfd)
p->maxfd = connfd; //maxfd의 값 갱신
if (i > p->maxi)
p->maxi = i; //maxi의 값 갱신
break;
}
}
if (i == FD_SETSIZE) app_error("add_client error: Too many clients"); //더 이상 클라이언트 등록 불가
}
add_client() 함수는 새로운 클라이언트와 연결된 connfd를 clientfd 배열에 추가한다. clientfd 배열에서 빈 슬롯을 찾은 후, 서버는 connfd를 배열에 추가하고, 해당 디스크립터에 대해 rio_readlineb() 함수 호출이 가능하도록 Rio 읽기 버퍼를 초기화한다. 그리고, select() 함수가 감시할 read set에 해당 디스크립터를 추가한다.
void check_clients(pool *p) {
int i, connfd, n;
char buf[MAXLINE];
rio_t rio;
for (i = 0; (i <= p->maxi) && (p->nready > 0); i++) { //ready set에 속하는 원소 탐색
connfd = p->clientfd[i]; //알맞은 디스크립터 사용
rio = p->clientrio[i]; //알맞은 rio 버퍼 사용
if ((connfd > 0) && (FD_ISSET(connfd, &p->ready_set))) { //해당 디스크립터가 준비되었다면, echo함
p->nready--;
if ((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) { //클라이언트로부터 읽어 들이기
byte_cnt += n;
printf("Server received %d (%d total) bytes on fd %d\n", n, byte_cnt, connfd);
Rio_writen(connfd, buf, n); //클라이언트에 echo하기
} else { //EOF가 감지되었다면, 해당 connfd를 clientfd 배열에서 제거
Close(connfd);
FD_CLR(connfd, &p->read_set);
p->clientfd[i] = -1;
}
}
}
}
check_clients() 함수는 준비된 각 connfd로부터 텍스트 한 줄을 echo하는 함수이다. 풀어서 설명하면, 텍스트 줄 읽기에 성공하면 해당 줄을 클라이언트에게 다시 echo하며, echo한 문장열의 길이와 지금까지 모든 클라이언트로부터 echo한 문자열들의 총 바이트 수를 출력한다. 만약 클라이언트가 연결을 닫아 EOF가 감지되면, 서버는 자신의 연결도 닫고 해당 디스크립터를 clientfd 배열에서 제거한다.
Figure 6의 FSM의 관점에서 보면, select() 함수는 입력 이벤트를 감지하고, add_client() 함수는 새로운 FSM을 생성한다. check_clients() 함수는 상태 전이를 수행하여 입력 라인을 echo하고, 클라이언트가 연결을 닫으면 FSM을 삭제한다.
Pros and Cons of Event-based Servers
위에서 작성한 서버는 I/O multiplexing 기반의 event-driven 프로그래밍의 장점과 단점을 잘 보여주는 사례이다. 첫 번째 장점은 event-based 설계가 process-based 설계보다 프로그램의 동작에 대해 더 많은 control을 프로그래머에게 부여한다는 것이다. 위 서버 코드를 응용하면 어떤 클라이언트에게 우선 서비스를 제공하는 event-based concurrent 서버를 작성할 수 있는데, 이는 process-based 서버에서는 구현하기 어렵다.
또 다른 장점은 해당 서버가 하나의 control flow 내에서 실행되기 때문에 코드의 모든 부분이 그 프로세스의 전체 주소 공간에 접근할 수 있다는 것이다. 이는 각각의 flow 간에 데이터를 공유하기 쉽도록 만들어 준다. 또한 이와 같이 구현하면 gdb와 같은 디버깅 도구를 통해서 순차적인 control flow를 거치며 디버깅할 수 있다는 장접이 있다.
마지막으로, 프로세스나 쓰레드를 제어하는데 소요되는 오버헤드가 존재하지 않아 효율적으로 구현할 수 있다는 장점이 있다. 이러한 장점 덕분에 높은 퍼포먼스를 요구하는 웹 서버나 검색 엔진등에 사용된다.
하지만 이렇게 구성된 서버는 코드가 복잡해진다는 치명적인 단점을 가지고 있다. 위의 예시 코드는 process-based 서버보다 3배 더 긴 코드를 가지고 있다. 이는 concurrent의 granularity가 낮아질수록 코드의 복잡성이 증가한다. Granularity란, 단위 시간마다 control flow가 실행하는 명령어의 수이다. 예를 들어, 이 서버에서는 한 줄의 텍스트를 읽는 동안 실행되는 명령어의 수가 concurrent의 granularity이다.
또한 잘 정제된(fine-grained) concurrency를 제공할 수 없다는 단점이 있다. 이는 어떤 control flow가 클라이언트로부터의 입력을 읽고 있는 동안에는, 다른 어떤 명령어도 실행할 수 없다는 문제점과 연결된다.. 이러한 결점 때문에 어떤 악의적인 클라이언트가 텍스트 줄의 일부만 전송하고 정지해버릴 경우, 서버는 다른 클라이언트로부터의 연결 요청이나 echo를 수행할 수 없다.
또 다른 중요한 단점은 하나의 control flow만 활용하기 때문에 이와 같이 작성된 서버는 멀티코어 프로세서의 성능을 완전히 활용할 수 없다는 것이다.
Concurrent Programming with Threads
Process-based 접근 방식은 각 flow 마다 별도의 프로세스를 사용하며 커널을 통해 각 프로세스를 자동으로 스케쥴링하는 방식이다. Event-based 접근 방식은 control flow를 직접 구현하고, 하나의 flow 내에서 I/O multiplexing을 이용해 명시적으로 flow를 스케쥴링한다. 이러한 관점에서 볼 때, thread-based 접근 방식은 위 두 문단에서 다룬 접근 방식의 혼합형이라고 볼 수 있다.
쓰레드(thread)란 프로세스의 컨텍스트(context) 안에서 실행되는 control flow이다. 현대 시스템은 하나의 프로세스 내에서 여러 쓰레드가 동시에(concurrently) 실행되는 프로그램을 작성할 수 있으며, 각각의 쓰레드는 커널에 의해서 자동으로 스케쥴링된다. 각 쓰레드는 TID[9], 스택, 스택 포인터, 프로그램 카운터, 범용 레지스터(general purpose register) 등의 쓰레드 컨텍스트(thread context)를 가진다. 그럼에도 하나의 프로세스 안에서 실행되는 모든 쓰레드는 해당 프로세스의 전체 virtual memory 공간을 공유한다.
쓰레드를 기반으로 하는 control flow는 process-based 기반의 flow와 event-based 기반의 flow의 특성을 결합한 형태이다. 프로세스와 같이 쓰레드는 커널에 의해서 자동으로 스케쥴링되며, 커널에 의해 고유한 ID로 식별된다. 그럼에도 Event-based 기반의 flow와 같이 여러 쓰레드는 하나의 프로세스 컨텍스트 안에서 실행되며, 프로세스의 전체 virtual memory를 공유한다. 이에 따라 각 쓰레드들은 code, data, heap, 공유 라이브러리, 파일 디스크립터들을 공유한다.[10]
Processes vs. Threads

프로세스를 해석하는 전통적인 관점에서는, 프로세스는 프로세스 컨텍스트와 Code/Data/Stack 메모리 공간[11]으로 이루어진다. 이때, 프로세스 컨텍스트에는 레지스터 값, 조건 코드(Condition codes), 스택 포인터, 프로그램 카운터등이 포함된다. 이때 프로세스 컨텍스트와 대비되는 개념으로 커널 컨텍스트가 존재하며, 이에는 가상 메모리 구조, 디스크립터 테이블, brk 포인터 등이 포함된다. 이는 figure 7이 잘 보여주고 있다.

프로세스를 쓰레드와 결부시켜 해석하는 시각도 존재한다. 이 시각에서는 프로세스를 하나의 메인 쓰레드로 보며, 프로세스를 쓰레드 컨텍스트와 Code/Data 메모리로 구성되어 있다고 본다. 이때, 프로세스 컨텍스트에는 레지스터, 조건 코드, 스택 포인터, 프로그램 카운터등이 포함된다. 또한 각각의 쓰레드들은 Heap, Code, 전역 데이터, 공유 라이브러리 등과 커널 컨텍스트를 공유한다. 이때 각 쓰레드들은 자신만의 스택 메모리 공간을 가지고, 이를 이용해 함수 호출이나, 지역 변수등을 관리할 수 있다. 하지만 이는 별도로 보호되어 있지 않으며, 이로 인해 다른 쓰레드에 의해 접근될 수 있다. 또한 각 쓰레드들은 커널에 의해서 식별되기 위해서 고유한 thread ID(TID)를 가진다. 이는 figure 8이 잘 보여주고 있다.
아래는 쓰레드와 프로세스의 차이점을 정리한 표이다.
| 프로세스 | 쓰레드 | |
|---|---|---|
| 공통점 | 모두 자신 만의 logical control flow를 가진다. | |
| 다른 프로세스/쓰레드와 concurrently하게 실행될 수 있다. | ||
| context switch가 가능하다. | ||
| 차이점 | 프로세스는 일반적으로 메모리 구조, 데이터 등을 공유하지 않는다. | 쓰레드는 모든 코드와 데이터를 공유한다.[12] |
| 프로세스 컨트롤은 생성, 수거 면에서 더욱 복잡하다. | 쓰레드는 프로레스 보다 관리할 때 비용면에서 저렴하다. | |
Thread Execution Model

여러 쓰레드에 대한 실행 모델은 여러 프로세스에 대한 실행 모델과 많은 면에서 유사하다. Figure 을 살펴보면, 각 프로세스는 메인 쓰레드라고 불리는 하나의 쓰레드로 시작한다. 이후 어떤 시점에서 메인 쓰레드는 피어 쓰레드(peer)를 생성하고, 이 시점부터 두 쓰레드는 동시에 실행된다. 이때 피어 쓰레드가 실행되는 경우는 메인 쓰레드가 read(), sleep()로 인해서 잠시 블록되거나, 타이머에 의해 메인 쓰레드가 인터럽트되어 context switch가 발생하는 경우이다.

쓰레드들은 프로세스 단위로 피어 집합(pool of peers)을 형성한다. 이때 프로세스는 트리 구조를 이루는 반면, 쓰레드들은 같은 프로세스 내에서 평등한 peer 관계를 가진다. 이때 두 쓰레드가 시간 상 겹쳐서 실행되면 동시적인(concurrent) 실행이라고 한다. 이때 겹치지 않으면 순차적인 실행이라고 한다. 이때 단일 코어(single core) CPU를 통해 실행이 될 경우에는 time slicing을 통해서 병렬성(parallelism)을 흉내내는 정도에 그치지만, 멀티 코어(multi core)를 이용하여 실행할 경우에는 진정한 의미의 병렬성을 구현할 수 있게 된다.
쓰레드 실행은 프로세스와 몇가지 중요한 측면에서 다르다. 쓰레드의 컨텍스트는 프로세스의 컨텍스트보다 더 작기 때문에, 쓰레드의 컨텍스트 변경은 프로세스의 그것 보다 더욱 빠르게 이루어진다. 또한, 쓰레드는 프로세스와 달리 엄격한 부모-자식 계층 구조를 가지지 않는다. 한 프로세스에 속한 쓰레드들은 어떤 쓰레드에 의해서 생성되었는지와 상관없이 모두 동등한 피어의 무리(pool)을 이룬다. 따라서 어떤 쓰레드는 동일한 무리에 속한 다른 쓰레드를 종료시킬 수 있고, 종료되기를 기다릴 수 있다.
Posix Threads
자세한 내용은 Posix Threads 문서를 참조하십시오.
A Concurrent Server Based on Threads
아래는 thread-based echo 서버의 코드이다:
#include "csapp.h"
void echo(int connfd); //사용할 echo 함수
void *thread(void *vargp); //
int main(int argc, char **argv)
{
int listenfd, *connfdp;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
pthread_t tid;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]); //argv[1]에 해당하는 포트 번호로 서버용 소켓을 열고 bind, listen
while (1) {
clientlen = sizeof(struct sockaddr_storage); // 클라이언트 주소 구조체 크기 설정
connfdp = Malloc(sizeof(int)); // connfd 값을 저장할 공간을 connfdp에 동적으로 할당
*connfdp = Accept(listenfd, (SA *) &clientaddr, &clientlen); //해당 connfd 디스크립터에 대한 연결 수락
Pthread_create(&tid, NULL, thread, connfdp); //이 포인터를 인자로 쓰레드를 생성하기 위해 thread() 함수 호출
}
}
/* Thread routine */
void *thread(void *vargp) {
int connfd = *((int *)vargp); //전달받은 void 포인터를 정수 포인터로 캐스팅해서 실제 connfd값 추출
Pthread_detach(pthread_self()); //해당 쓰레드를 detach하여, 쓰레드가 종료되면 자동으로 회수되도록 함
Free(vargp); //main에서 Malloc()한 메모리를 해제 → 이미 connfd를 저장했으므로
echo(connfd); //echo() 함수 실행
Close(connfd); //echo() 함수가 종료되면 연결을 종료
return NULL;
}
위는 thread-based echo 서버의 코드이고, 이는 전체적으로 process-based echo 서버의 코드와 비슷하다. 기본적으로 메인 쓰레드는 반복적으로 연결 요청을 기다리고, 그런 다음 그 요청을 처리하기 위해 피어 쓰레드를 생성하여 여러 클라이언트를 동시에 처리한다. 이때 각각의 클라이언트의 요청은 각각의 독립된 쓰레드에 의해서 처리된다. 이때 각 프로세스들은 스택과 TID를 제외한 모든 메모리 공간을 공유되므로, 지역 변수는 개별 스택에 저장되고, 충돌은 일어나지 않는다.
코드 자체는 간단하지만, 몇 가지 미묘한 문제들이 존재한다. 첫 번째 문제는 pthread_create()를 호출할 때, 의도하지 않은 지역 변수 공유가 발생하는 문제이다. 가장 단순한 방법은 디스크립터에 대한 포인터를 전달하는 것으로, 아래와 같은 방식이다:
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen);
Pthread_create(&tid, NULL, thread, &connfd);
그런 다음, 피어 쓰레드는 이를 역참조하여 지역 변수에 할당한다:
void *thread(void *vargp) {
int connfd = *((int *)vargp);
...
}
하지만 이는 잘못된 방식이다. 왜냐하면 이는 피어 쓰레드 내의 할당문과 메인 쓰레드 내의 accept() 함수 호출 사이에 경쟁 조건(race condition)이 유발되기 때문이다. 만약 쓰레드 내의 할당문이 accept() 함수보다 먼저 실행된다면, 쓰레드 내의 지역 변수 connfd는 올바른 디스크립터 값을 얻는다. 그러나 만약 할당문이 새로운 연결 요청을 받은 accept() 함수보다 늦게 실행된다면, 원래의 쓰레드의 connfd 변수는 다음 연결에 해당하는 디스크립터의 번호를 얻게 된다. 그 결과, 두 개의 쓰레드가 동일한 디스크립터를 통해 연결을 수행하게 된다.
이러한 문제 상황을 피하기 위해서는 accept() 함수가 반환한 각 connected 디스크립터를 동적으로 할당한 메모리 블록에 저장해야 하며, 위 코드는 이러한 형태로 구현되어 있다. 또한 메모리 누수를 방지하기 위해서, 더불어 메인 쓰레드에서 할당되었던 메모리 블록도 쓰레드에서 반드시 free해야 한다.
또한 메모리 누수 방지를 위해서 생성된 쓰레드들을 분리된(detached) 상태로 바꾸어야 한다. 이는 쓰레드들을 수거하는 작업이 명시되지 않았으므로, 시스템에 의해서 자동으로 수거되도록 해야 하기 때문이다. 그리고, thread-safe 함수만 사용해야 한다. 이는 여러 쓰레드가 동시에 호출해도 안전한 함수를 의미한다.
Pros and Cons of Thread-Based Designs
Thread-based 설계의 장점은 각 쓰레드 간의 데이터 공유가 쉽다는 것이다. 쓰레드끼리는 힙, 전역 변수 등을 공유하므로, 로그 기록이나 파일 캐시등을 효율적으로 공유할 수 있다. 또한 쓰레드 생성/전환은 프로세스의 그것 보다 더욱 빠르고, 컨텍스트 스위칭 비용이 낮으므로, process-based 설계보다 더욱 효율적이라는 장점이 있다.
하지만 쓰레드 사이에서 의도치 않은 데이터 공유가 발생하여 디버깅하기 힘든 오류가 발생할 수 있다. 쓰레드 간 공유가 쉬운 것이 장점인 동시에, 어떤 데이터가 공유되고 어떤 것이 독립적인지 헷갈릴 수 있으며, 이로 인해 race condition이 발생할 수 있다.
Threads for Concurrent Programming
Synchronization
자세한 내용은 Synchronization 문서를 참조해 주십시오.
A Concurrent Server Based on Prethreading
세마포어의 개념은 프리스레딩(prethreading)이라는 기법에 적용될 수 있으며, 이 기법은 아래와 같이 구현된 concurrent 서버 코드를 통해 알아볼 수 있다:
#include "csapp.h"
#include "sbuf.h"
#define NTHREADS 4
#define SBUFSIZE 16
void echo_cnt(int connfd);
void *thread(void *vargp);
sbuf_t sbuf; //connfd를 저장하는 버퍼이며, 내부적으로 세마포어 사용
int main(int argc, char **argv)
{
int i, listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
pthread_t tid;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(0);
}
listenfd = Open_listenfd(argv[1]); //Open_listenfd()는 서버 소켓을 열고, listen()까지 진행
sbuf_init(&sbuf, SBUFSIZE); //sbuf를 초기화하고, listenfd만을 등록
for (i = 0; i < NTHREADS; i++) //NTHREADS만큼 스레드 생성해서 thread() 함수 실행.
Pthread_create(&tid, NULL, thread, NULL);
while (1) {
clientlen = sizeof(struct sockaddr_storage);
//클라이언트 요청이 오면 Accept()로 연결을 수락.
connfd = Accept(listenfd, (SA*) &clientaddr, &clientlen);
//수락한 결과 얻은 connfd를 sbuf에 등록하기 -> 나중에 스레드에서 처리
sbuf_insert(&sbuf, connfd);
}
}
void *thread(void *vargp)
{
Pthread_detach(pthread_self()); //스레드 종료 시 리소스를 자동 회수
while (1) {
int connfd = sbuf_remove(&sbuf); //sbuf에서 connfd를 소비(provider-consumer)
echo_cnt(connfd); //connfd를 통해 클라이언트의 요청을 처리
Close(connfd); //연결이 종료되면 connfd를 닫기
}
}

위 코드에서 concurrent 서버는 새로운 클라이언트가 접속할 때마다 새로운 스레드를 생성한다. Concurrent Server 문서에 다룬 스레드 기반의 서버의 단점은 클라이언트마다 새 스레드를 만드는데 적지 않은 비용이 발생한다는 것이다. 하지만 위에서 제시된 prethreading 방식을 이용한 서버는 이러한 문제를 해결하기 위해서 figure 11에 제시된 생산자-소비자(Producer-Consumer) 모델을 사용하여 이러한 오버헤드를 줄이고자 한다. 이러한 모델에서 서버는 메인 스레드(main thread)와 작업 스레드(worker thread)로 구성된다. 메인 스레드는 반복적으로 클라이언트로부터의 연결 요청을 수락하고, 그로부터 생성된 connfd를 버퍼(sbuf)에 저장한다. 각 작업 스레드는 반복적으로 버퍼에서 디스크립터를 꺼내어서 클라이언트 서비스를 수행한 다음, 다음 connfd를 기다린다. 이는 위 코드에서 제시되었듯이, 아래와 같은 control flow를 가진다:
- 메인 스레드의 경우
- 버퍼 sbuf를 초기화 한 후, 작업 스레드 집합을 생성한다.
- 무한 루프에서 클라이언트로부터의 연결 요청을 수락하고, 생성된 connfd를 sbuf에 등록한다.
- 각 작업 스레드의 경우
- 버퍼에서 connfd를 꺼낼 수 있을 때까지 기다린다.
echo_cnt()함수를 호출하여 클라이언트의 입력을 echo한다.
아래는 echo_cnt() 함수를 구현한 코드이다:
#include "csapp.h"
static int byte_cnt; //서버가 지금까지 읽은 모든 바이트의 누적 합.
static sem_t mutex; //byte_cnt를 여러 스레드가 동시에 접근하지 못하게 하는 세마포어
static void init_echo_cnt(void) //서버 실행 중 단 한 번만 호출되도록 보장된다.
{
Sem_init(&mutex, 0, 1); //세마포어 mutex를 1로 초기화하여 사용한다.
byte_cnt = 0;
}
//클라이언트 소켓(connfd)을 통해 라인 단위로 문자열을 echo한다. 동시에 총 수신 바이트 수(byte_cnt)를 세고 출력한다.
void echo_cnt(int connfd)
{
int n;
char buf[MAXLINE];
rio_t rio;
//init_echo_cnt()를 스레드 환경에서 한 번만 호출하도록 보장하는 구문
static pthread_once_t once = PTHREAD_ONCE_INIT
Pthread_once(&once, init_echo_cnt);
Rio_readinitb(&rio, connfd); //connfd를 통한 연결을 위해서 rio 버퍼를 초기화한다.
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0) { //클라이언트가 데이터를 보내는 동안 계속 읽음
P(&mutex); //mutex 세마포어를 통해서 byte_cnt를 보호
byte_cnt += n; //n은 이번에 읽은 바이트 수, 이를 byte_cnt에 추가
printf("server received %d (%d total) bytes on fd %d\n", n, byte_cnt, connfd);
V(&mutex); //보호 해제
Rio_writen(connfd, buf, n); //이번 루프에서 읽어 들인 문자열을 출력
}
}
위에서 다룬 echo_cnt() 함수는 echo() 함수의 변형으로, 모든 클라이언트로부터 수신된 누적 바이트 수를 byte_cnt라는 전역 변수에 저장한다. 이 경우, 해당 함수를 구현하기 위해서는 byte_cnt 카운터(counter) 변수와 mutex 세마포어를 초기화하여야 한다. 하나의 접근 방식은 메인 스레드가 명시적으로 초기화 함수를 호출하는 것이다. 다른 접근 방식은 해당 코드에서의 구현과 같이 pthread_once() 함수를 사용하여, 어떤 스레드가 처음으로 echo_cnt() 함수를 호출할 때 초기화 함수가 호출되도록 하는 것이다.
Using Threads for Parallelism

요즘 나오는 컴퓨터들은 figure 6와 같은 멀티코어 프로세서를 가지고 있으며, 이는 concurrent programming을 더욱 빠르게 실행한다. 이는 OS 커널이 스레드들을 단일 코어에서 순차적으로 실행하는 대신, 멀티코어에서 병렬적으로 스케쥴링하여 처리하기 때문이다. 이러한 병렬성(parallelism)을 활용하는 것은 매우 중요하다. Figure 12는 sequential 프로그램, concurrent 프로그램, parallel 프로그램 사이의 집합 관계로 나눌 수 있다. 모든 프로그램은 sequential 프로그램과 concurrent 프로그램이라는 서로소 집합으로 나눌 수 있다. 이때 parallel 프로그램은 concurrent 프로그램의 진부분집합이다. 아래는 parallel 프로그램의 간단한 예시이다.
#include "csapp.h"
#define MAXTHREADS 32
void *sum_mutex(void *vargp); //각 스레드가 실행할 함수의 프로토타임
long gsum = 0; // 모든 스레드가 각자 구한 부분합을 저장할 전역변수
long nelems_per_thread; // 각 스레드가 처리할 원소의 개수
sem_t mutex; // gsum에 대한 race condition을 막기 위한 세마포어
int main(int argc, char **argv)
{
long i, nelems, log_nelems, nthreads, myid[MAXTHREADS];
pthread_t tid[MAXTHREADS];
/* Get input arguments */
if (argc != 3) {
printf("Usage: %s <nthreads> <log_nelems>\n", argv[0]);
exit(0);
}
nthreads = atoi(argv[1]); // nelems는 스레드의 개수
log_nelems = atoi(argv[2]); // 실제로 처리할 원소 수의 2의 로그 값
nelems = (1L << log_nelems); // 2^log_nelems을 통해 실제로 처리할 원소의 수 계산
nelems_per_thread = nelems / nthreads;
sem_init(&mutex, 0, 1); //세마포어를 1로 초기화
/* Create peer threads and wait for them to finish */
for (i = 0; i < nthreads; i++) {
myid[i] = i; // 각 스레드에게 부여되는 고유 인덱스
Pthread_create(&tid[i], NULL, sum_mutex, &myid[i]); // 스레드를 생성
}
for (i = 0; i < nthreads; i++)
Pthread_join(tid[i], NULL); //모든 스레드가 작업을 마칠 때까지 기다림 (동기화)
/* Check final answer */
if (gsum != (nelems * (nelems - 1)) / 2) //오류 발생했는지 확인하기
printf("Error: result=%ld\n", gsum);
exit(0);
}
/* Thread routine for psum-mutex.c */
void *sum_mutex(void *vargp)
{
long myid = *((long *)vargp); //인자로 전달된 id 추출
//예를 들어, myid = 0: [0, 256), myid = 1: [256, 512)
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i;
for (i = start; i < end; i++) {
P(&mutex);
gsum += i; //gsum에 mutex를 이용하여 start ~ end까지의 수를 모두 덧셈
V(&mutex);
}
return NULL;
}
예를 들어 정수 0부터 n-1까지의 합을 병렬로 계산하는 상황을 생각하자. 가장 단순한 해결책은 스레드들이 mutex로 보호되는 공유 전역 변수에 합을 더하도록 하는 것이다. 이때 단순화를 위해 t개의 서로 다른 스레드들이 존재한다고 가정할 때, 0 ~ n까지의 각 구간은 n/t개의 원소를 가진다. 따라서 이를 구현하기 위해서는 sum_mutex를 통해서 스레드를 호출할 때 myid를 통해서 스레드에게 주어진 각 구간의 합을 공유 전역 변수에 더하도록 하면 된다. 이렇게 구현된 프로그램은 싱글 스레드로 실행할 때에도 매우 느릴 뿐 아니라, 여러 스레드로 병렬 실행할 경우 오히려 더욱 느려진다는 놀라운 결과를 보여준다. 사실 이는 당연한 결과이기도 하다. 왜냐하면 하나의 프로세스 내의 반복문 내에서 실행될 수 있었던 프로그램을, 더 많은 스레드를 이용하여 구현하는 것이며, 스레드가 많아질 수록 동기화 연산(P, V)[13]이 더욱 많이 사용되기 때문이다. 이는 아래와 같은 결론을 제시한다:
동기화 오버헤드는 크므로 가능한 한 피해야 한다. 피할 수 없다면, 한 번 동기화할 때마다 그 안에서 많은 일을 처리하도록 설계하여야 한다.
이 예제에서 동기화를 피하는 한 가지 방법은 각 동료 스레드가 자신의 합을 각 스레드에 고유하게 할당된 메모리 공간에 저장하는 것이다. 아래는 이를 구현한 코드이다:
/* Thread routine for psum-array.c */
void *sum_array(void *vargp)
{
long myid = *((long *)vargp); // 스레드 ID 추출
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i;
for (i = start; i < end; i++) {
psum[myid] += i; //myid를 통해서 각 스레드에 할당된 메모리 공간에 접근
}
return NULL;
}
메인 스레드는 전역 배열 psum을 정의하고, 각 스레드 i는 psum[i]에 자신의 합을 누적시킨다. 이를 통해 각 스레드에게 고유한 메모리 위치를 제공할 수 있으며, 이를 통해 mutex를 통한 동기화로 전역 배열 psum을 보호할 필요가 없다. 단지 메인 스레드는 동기화를 통해 모든 작업 스레드가 종료되기를 기다릴 뿐이다. 이후 메인 스레드는 psum 벡터의 원소들을 합산하여 최종 결과를 얻는다. 이 psum-array 프로그램은 멀티코어 환경에서 실행하면, psum-mutex 프로그램보다 수십 배 빠르게 실행된다.
또한 각 스레드가 자신의 계산 결과를 전역 배열 psum 대신 지역 변수에 누적시키는 변수에 누적시키는 방식을 활용할 수도 있다. 이는 아래와 같이 구현된다:
/* Thread routine for psum-local.c */
void *sum_local(void *vargp)
{
long myid = *((long *)vargp); // 스레드 ID 추출
long start = myid * nelems_per_thread; /* Start element index */
long end = start + nelems_per_thread; /* End element index */
long i, sum = 0;
for (i = start; i < end; i++) {
sum += i;
}
psum[myid] = sum;
return NULL;
}
이는 이전에 구현되었던 방식에 있었던 불필요한 메모리 참조를 줄임으로서 더욱 효율성을 높인 것이다.
Characterizing the Performance of Parallel Programs

Figure 13은 psum-array, psum-local 프로그램의 총 실행 시간을 스레드 수에 따라 나타낸 것이다. 각 경우에서 프로그램은 n = 231이며, 4코어 환경에서 작동한다. 해당 figure에서 스레드의 숫자가 증가할 수록 실행시간이 감소하지만, psum-array 프로그램의 경우에는 스레드의 숫자가 증가할 경우에 오히려 실행 시간이 증가하기도 한다. 이상적인 경우, 실행 시간은 스레드 수가 증가함에 따라 선형적으로 감소한다. 즉, 스레드 수가 두 배가 되면 실행 시간은 절반이 되는 것이다. 하지만 실제로는 스레드의 수가 임계치(해당 예시에서는 4개)를 초과하면, 각 코어가 여러 스레드를 컨텍스트 스위칭하며 실행해야 하므로 실행 시간이 오히려 증가하는 것이다. 따라서 parallel 프로그램은 일반적으로 CPU의 각 코어가 하나의 스레드를 실행하도록 작성된다.
절대적인 실행 시간이 어떤 프로그램의 성능을 측정하는 직관적이고 궁극적인 지표이지만, parallel 프로그램이 parallelism을 얼마나 잘 활용하는지를 보여주는 지표도 존재하며, 이를 parallel 프로그램의 속도 향상도(speedup)라고 한다. 이때 속도 향상도를 보는 첫 번째 관점은 strong scailing이다. strong scailing은 작업의 총량을 고정한 채로, pararell 처리에 사용할 프로세서(스레드) 수를 늘려가며 실행 시간을 줄이는 방식을 의미한다. 이러한 관점에서 속도 향상도는 아래와 같이 정의된다.
[math]\displaystyle{ S_p=\frac{T_1}{T_p} }[/math]
이때 [math]\displaystyle{ p }[/math]는 코어의 수, [math]\displaystyle{ T_k }[/math]는 k개가 있을 때의 실행 시간이다. 이때 [math]\displaystyle{ S_p }[/math]는 아래와 같이 갈린다:
- [math]\displaystyle{ S_p }[/math]가 절대 속도 향상도(absolute speedup): [math]\displaystyle{ T_1 }[/math]이 sequential 프로그램의 실행 시간일 때
- [math]\displaystyle{ S_p }[/math]가 상대 속도 향상도(absolute speedup): [math]\displaystyle{ T_1 }[/math]이 parallel 프로그램의 실행 시간일 때
이때 절대 속도 향상도가 parallelism의 효과를 더욱 정확히 측정할 수 있는 지표이다. 왜냐하면 parallel 프로그램은 1개의 프로세서에서 실행할 때에도 동기화에 의한 오버헤드가 존재하며, 이는 상대 속도 향상도의 분자([math]\displaystyle{ T_1 }[/math])를 인위적으로 키워서 수치를 잘못 해석할 수 있기 때문이다. 하지만 상대 속도 향상도는 굳이 해당 프로그램에 대한 sequential한 버전을 따로 만들 필요가 없으므로 더욱 간편하다는 장점이 있다. 이와 관련된 지표로 효율성(efficiency)가 있으며, 이는 아래와 같이 계산된다:
* [math]\displaystyle{ E_p = \frac{S_p}{p} = \frac{T_1}{pT_p} }[/math]

이는 보통 0~100% 사이의 백분율로 표현되며, parallelism으로 인한 오버헤드를 측정한다. [math]\displaystyle{ E_p }[/math]가 100%에 가까울 수록 오버헤드가 적다는 것을 의미한다. Figure 14는 psum-local 프로그램에 대한 퍼포먼스를 나타낸 표이다. 해당 표를 분석하면 효율성이 그럭저럭 괜찮은 것을 볼 수 있다. 하지만 실제 코드를 구현할 경우에는 동기화가 더욱 복잡해지기 때문에 효율성을 높이는 것이 더욱 어려워진다.
속도 향상도를 보는 다른 관점은 weak scailing이다. 이는 프로세서의 수를 늘릴 때 문제의 크기도 함께 늘려서, 각 프로세서가 처리하는 작업량이 일정하도록 하는 방식이다. 이 경우 속도 향상도와 효율성은 단위 시간당 수행된 총 작업량을 기준으로 측정된다. 예를 들어, 프로세서 수를 2배로 늘리고 처리하는 작업량도 2배로 늘렸을 때, 한 시간당 처리량이 두 배가 되면 선형적인 속도 향상도와 100% 효율을 얻는 것이다.
Memory Consistency
메모리 일관성(Memory Consistency)에 대해서 설명하기 위해, 아래와 같은 간단한 예제 코드를 살펴보자:
//a, b는 전역 변수
int a = 1;
int b = 100;
Thread1:
a = 2; // Wa: 변수 a에 대한 쓰기
print(b); // Rb: 변수 b에 대한 읽기
Thread2:
b = 200; // Wb: 변수 b에 대한 쓰기
print(a); // Ra: 변수 a에 대한 읽기

이때 위 프로그램을 실행시킨다면, 그 결과는 메모리 일관성을 구현하는 모델에 따라 달라진다. 즉, 하드웨어가 스레드 간 접근을 어떻게 처리하느냐에 따라 달라진다. 이때 병렬적으로 실행된 여러 스레드들의 명령 실행 결과가 마치 어떤 하나의 순차적으로 실행한 프로그램에서 나올 수 있다면, 해당 시스템은 순차적인 일관성(sequential consistency)를 가진다. 이때 모든 parallel 프로그램은 스레드 간 실행 순서가 임의로 섞일 수 있음에도, 순차적인 일관성을 보장해야 한다. 이때 스레드 일관성 제약 조건(Thread consistency constraints)이라는 개념이 대두되며 이는 각 스레드 내에서 명령이 실행되는 순서를 의미한다. 즉, a = 2 이후에 print(b)가 실행된다는 것이 보장된다. Figure 15는 위 코드에 대해 가능한 실행 순서와 출력 조합을 나열한 것이다. 헤딩 figure는 스레드 일관성 제약 조건에 따라 Wa-Rb, Wb-Ra 순서를 보존하며 실행된 결과들을 보여주고, 따라서 (100, 1), (1, 100)과 같은 결과들은 두 쓰레드가 모두 쓰기 작업을 하기도 전에 읽기 작업을 시작했다는 것을 의미하므로, 쓰레드 일관성 제약 조건을 어긴다.

하지만 (100, 1), (1, 100)과 같은 결과들은 캐시 일관성이 없는 시스템에서는 충분히 발생할 수 있다. Figure 16과 같이 각 스레드가 자기만의 write-back 캐시[14]를 가지고 있고, 캐시들끼리 연동(coherence)하지 않는 상황을 가정하자. 이때 Thread 1은 a = 2, print(b)명령어를 수행하고, Thread 2는 b = 200, print(a)를 실행한다. 하지만 이들은 자신만의 캐시 공간을 가지고 있으므로 Thread 1에게 b는 항상 100이고, Thread 2에게 a는 항상 1이다. 즉, Thread1과 Thread2가 서로를 인식하지 못한다.
.png)
이러한 문제를 해결하기 위한 캐시 일관성 유지 기법 중 하나가 snoopy caches라고 하는 개념이다. 이는 아래와 같이 각 캐시 블록에 상태 태그를 부여한다:
- Invalid (I): 사용 불가능
- Shared (S): 읽기만 가능, 여러 캐시에 공유
- Exclusive (E): 쓰기 가능, 오직 하나의 캐시에 의해서만 접근됨
.png)
이를 통해, 위의 코드의 Wa, Wb는 figure 17과 같이 메모리/캐시에 수행된다. 해당 figure와 같이 실행된 결과, 두 스레드 캐시가 a = 2, b = 200을 각각 보유하며, 캐시의 각 태크 블럭은 E 상태가 된다. 이때 Thread2가 a를 읽기 위해 bus를 통해 a의 값을 요청하면, Thread 1이 자기가 가지고 있는 a:2를 bus를 통해 전달하며, 해당 캐시 블록의 태그를 S로 바꾼다. 이와 마찬가지로 b = 200도 공유된다. 이는 figure 18에 나타나 있다. bus에는 메인 메모리도 연결되어 있지만, Thread 1의 캐시가 더욱 최신 메모리를 가지고 있기 때문에 Thread 1의 캐시가 Thread 2에게 전달되는 것이다. 이를 통해서 일관된 메모리 모델 유지가 가능케 할 수 있다.
Other Concurrency Issues
동기화는 매우 복잡한 문제이며, 상호 배제(mutual exclusion)과 생산자-소비자 동기화 기법은 동기화에 관련된 이슈들의 빙산의 일각일 뿐이다. 해당 문단에서는 동기화를 구현하기 위해서 기본적으로 점검해야할 기본적인 상황이다. 이때 설명은 기본적으로 스레드를 중심으로 이루어지지만, 대부분의 내용은 공유 자원에 접근하는 모든 concurrent flow에 대해서 해당된다.
Thread Safety
스레드를 사용할 때는 스레드-안전(thread safe) 특성을 가진 함수를 작성해야 한다. 어떤 함수가 여러 개의 concurrently하게 실행 중인 스레드에서 반복적으로 호출되어도 항상 올바른 결과를 낸다면, 해당 함수는 스레드-안전 특성을 가진 것이다. 만약 그렇지 않다면, 즉 여러 스레드가 동시에 호출할 때 올바른 결과를 보장하지 않는 다면, 그 함수는 스레드-위험(thread-unsafe)하다고 한다. 스레드-위험한 함수는 네 가지 부류로 구분된다[15]
먼저 공유 변수를 보호하지 않는 함수가 있다. 이는 공유 변수에 대한 적절한 동기화가 수행되지 않아 race condition을 가지고 있는 함수이다.[16] 하지만 이 경우, 동기화 연산이 해당 함수의 실행 속도를 느리게 할 수 있다.
또한 여러 번 호출될 때 내부적으로 상태(state)를 유지하고 이에 따라 실행되는 함수도 스레드-위험하다. 아래는 간단한 예시인 의사 난수 생성기(pseudorandom number generator)에 대한 코드이다:
unsigned next_seed = 1;
/* rand - return pseudorandom integer in the range 0..32767 */
unsigned rand(void)
{
next_seed = next_seed * 1103515245 + 12543;
return (unsigned)(next_seed >> 16) % 32768;
}
/* srand - set the initial seed for rand() */
void srand(unsigned new_seed)
{
next_seed = new_seed;
}
먼저, rand() 함수는 스레드-위험하다. 왜냐하면 현재 호출의 결과가 이전 호출의 중간 결과에 의존하기 때문이다. 단일 스레드에서는 rand()를 반복 호출하여 예측 가능한 난수열을 얻을 수 있지만, 여러 스레드에서 rand() 함수를 concurrently하게 호출하면 동일한 결과를 얻을 수 없다. 그 이유는 rand()는 내부적으로 seed 값과 같은 static 변수를 가지고 있으며, rand()를 여러 번 호출하면 이전 호출 결과를 기반으로 다음 값을 생성하기 때문이다. 즉 단일 스레드에서는 한 번에 하나씩 rand() 함수를 호출하므로, 내부의 static 변수가 안정적으로 업데이트될 수 있지만, 여러 스레드가 동시에 호출하면 해당 static 변수에 대해 race condition이 발생할 수 있기 때문이다. 이러한 함수를 스레드-안전하게 만들기 위한 유일한 방법은 static 변수를 사용하지 않도록 함수 자체를 다시 작성하는 것이다.[17][18]
세 번째로는 static 변수에 대한 포인터를 반환하는 함수가 있다. 예를 들어, ctime(), gethostbyname()과 같은 함수는 계산 결과를 static 변수에 저장하고 그 변수에 대한 포인터를 반환한다. 이러한 함수를 여러 스레드에서 concurrently하게 실행하면 호출한 스레드들이 하나의 동일한 메모리 공간을 공유하게 되므로, 언제든지 문제를 야기할 수 있다. 이를 해결할 수 있는 방식은 아래와 같은 두가지이다:
- 함수를 다시 작성하여, 호출자가 결과를 저장할 변수의 주소를 전달하게 한다.
- 함수가 복잡하거나 소스 코드가 없어서 수정이 어려운 경우, lock-and-copy 기법을 사용할 수 있다:
- 해당 함수에 mutex를 연결하고, 호출 지점에서 mutex를 잠근 후 함수 호출 → 반환값을 개인 메모리에 복사 → mutex 해제
- 이 과정을 수행하는 래퍼 함수를 정의하여 기존의 함수 호출을 모두 교체하면 된다. 예를 들어, 아래는 ctime() 함수에 대해 lock-and-copy를 사용한 래퍼 함수이다:
/* lock-and-copy version */
char *ctime_ts(const time_t *timep, char *privatep)
{
char *sharedp;
P(&mutex);
sharedp = ctime(timep);
strcpy(privatep, sharedp);
V(&mutex);
return privatep;
}
마지막으로는 스레드-위험한 함수를 호출하는 함수가 있다. 이는 직관적으로 당연하며, 이는 호출한 스레드-위험한 함수 대신 스레드-안전한 함수를 대신 호출하여 해결할 수 있다.
Reentrancy

스레드-안전한 함수 중에서 재진입 가능한 함수(reentrant functions)라고 불리는 중요한 부류가 있다. 이는 여러 스레드에 의해서 호출될 때 공유 데이터를 전혀 참조하지 않는 특성을 가진다. 이때 '스레드-안전한'(thread-safe)이라는 말과, '재진입 가능한'(reentrant)이라는 용어가 동의어처럼 오용되기도 하지만, 둘은 명확한 기술적인 차이가 존재한다. Figure 19는 스레드-안전한 함수, 스레드-위험한 함수, 재진입 가능한 함수들 사이의 집합 관계를 보여준다. 모든 함수의 집합은 스레드-안전 함수와 스레드-안전하지 않은 함수라는 서로소(disjoint) 집합으로 나뉜다. 또한 재진입 가능한 함수의 집합은, 스레드-안전 함수 집합의 진부분집합(proper subset)이다.
//Not thread-safe, not re-entrant
int tmp;
int add(int a) {
tmp = a;
return tmp + 10;
}
//Thread-safe but not re-entrant
thread_local int tmp;
int add(int a) {
tmp = a;
return tmp + 10;
}
//Not thread-safe but re-entrant
int tmp;
int add(int a) {
tmp = a;
return a + 10;
}
//Thread thread-safe and re-entrant
int add(int a) {
return a + 10;
}
재진입 가능한 함수는 일반적으로 재진입이 불가능한 스레드-안전 함수보다 효율적이다. 왜냐하면 동기화 연산을 전혀 필요로 하지 않기 때문이다. 또한 2번 부류에 속하는 스레드-위험한 함수를 스레드-안전하게 만드는 유일한 방법은 해당 함수를 재진입 가능하도록 다시 작성하는 것이다.
Using Library Functions in Threaded Programs

대부분의 Linux 함수들, 그리고 malloc(), free(), realloc(), printf(), scanf()와 같은 표준 C 라이브러리에서 정의된 함수들은 대체로 스레드-안전하다. 단 몇가지 예외가 존재하며, figure 20은 위험한 함수들을 나용한 것이다. 아래는 이들 몇가지 함수들에 대한 설명이다:
strtok()함수는 문자열을 파싱하기 위한 사용이 권장되지 않는 함수(deprecated)이다.asctime(), ctime(), localtime()함수는 시간과 날짜 형식 간 변환에 널리 사용되는 함수들이다.gethostbyaddr(), gethostbyname(), inet_ntoa()함수는 오래된 네트워크 프로그래밍 함수들로, 각각 재진입 가능한(reentrant)getaddrinfo(), getnameinfo(), inet_ntop()함수들로 대체되었다.
이 함수들 중 rand(), strtok() 함수를 제외하면, 대부분은 static 변수의 포인터를 반환하는 3번 부류에 속한다. 스레드 프로그램 내에서 이들 중 하나를 호출해야 하는 경우, 가장 권장되는 방식은 lock-and-copy 기법을 사용하는 것이다. 그러나 lock-and-copy 기법은 여러 가지 단점을 가진다:
- 추가적인 동기화 연산이 프로그램 실행을 느리게 만든다.
- 반환되는 포인터가 구조체 안에 또 구조체를 가진 복잡한 구조체인 경우, 전체 계층을 복사하려면 깊은 복사(deep copy)가 필요하다.
- rand() 함수와 같이 호출 간 상태를 유지하는 2번 부류의 스레드-안전하지 않은 함수에는 lock-and-copy 방식이 적용되지 않는다.
이러한 이유로, Linux 시스템은 대부분의 스레드-안전하지 않은 함수들에 대해 재진입 가능한(reentrant) 버전을 제공하며, 이러한 함수들의 이름은 항상 '_r' 접미사로 끝난다. 예를 들어, asctime() 함수의 재진입 가능한 버전은 asctime_r() 함수이다.
Races
Race는 프로그램의 정확한 작동(correctness)이 어떤 스레드가 control flow 상의 지점 x에 도달하기 전에 다른 스레드가 다른 지점 y에 도달하는지에 따라 결정될 때 발생한다. Race는 보통 프로그래머가 스레드들이 실행 상태 공간을 어떤 특정한 경로로 따라갈 것이라고 가정하고, "스레드 기반 프로그램은 가능한 모든 실행 경로에 대해 올바르게 동작해야 한다"는 원칙을 잊을 때 발생한다. 이를 이해하기 위해서 아래와 같은 예제를 살펴보자:
/* WARNING: This code is buggy! */
#include "csapp.h"
#define N 4
void *thread(void *vargp);
int main()
{
pthread_t tid[N];
int i;
for (i = 0; i < N; i++)
Pthread_create(&tid[i], NULL, thread, &i); //&i를 각 스레드에 인자로 넘기며, 이를 역참조하여 값을 읽음
for (i = 0; i < N; i++)
Pthread_join(tid[i], NULL); //모든 스레드의 종료를 기다림
exit(0);
}
/* Thread routine */
void *thread(void *vargp)
{
int myid = *((int *)vargp);
printf("Hello from thread %d\n", myid);
return NULL;
}
위에서 메인 스레드는 4개의 피어 스레드를 생성하고, 각각에 고유한 정수 ID에 대한 포인터를 전달한다. 각 동료 스레드는 자신에게 전달된 인자에서 ID를 지역 변수에 복사한 후 그 ID를 포함하는 메시지를 출력한다. 이는 매우 단순하지만, 이를 실제 시스템에서 실행하면 다음과 같은 결과가 출력될 수 있다:
linux> ./race
Hello from thread 1
Hello from thread 3
Hello from thread 2
Hello from thread 3
이 문제는 각 피어 스레드와 메인 스레드 사이의 race condition에 의해서 발생한다. 위의 결과가 나타날 떄에는 아래와 같이 주어진 코드가 작동한다:
- 메인 스레드가 13번째 줄에서 동료 스레드를 생성할 때, 지역 스택 변수 i의 포인터를 인자로 전달한다.
- 이 시점에서 루프 내에서의 i 증가와 인자를 역참조하여 할당하는 작업 사이에서 race가 시작된다.
- 만약 피어 스레드가 메인 스레드가 i를 증가시키기 전에 역참조를 실행하면, myid는 올바른 ID를 얻게 된다.
- 하지만 그렇지 않으면, myid는 다른 스레드의 ID를 얻는다.
Race condition의 가장 큰 문제는 해당 버그가 발생 여부가 커널이 스레드들을 어떻게 스케줄링하느냐에 달려 있다는 것이다. 따라서 이는 간헐적으로 발생할 수 있으며, 프로그래머는 해당 문제의 존재 사실 조차 모를 수 있다. 이러한 문제를 없애기 위해서는, 각 ID 정수에 대해 별도의 메모리 블록을 동적으로 할당하고, 그 블록에 대한 포인터를 스레드 루틴에 전달하면 된다. 또한, 메모리 누수를 피하기 위해, 스레드 루틴은 그 블록을 반드시 해제(free)해야 한다. 이는 아래와 같이 코드를 수정함으로서 달성될 수 있다:
#include "csapp.h"
#define N 4
void *thread(void *vargp);
int main()
{
pthread_t tid[N];
int i, *ptr;
for (i = 0; i < N; i++) {
ptr = Malloc(sizeof(int));
*ptr = i;
Pthread_create(&tid[i], NULL, thread, ptr);
}
for (i = 0; i < N; i++)
Pthread_join(tid[i], NULL);
exit(0);
}
/* Thread routine */
void *thread(void *vargp)
{
int myid = *((int *)vargp);
Free(vargp);
printf("Hello from thread %d\n", myid);
return NULL;
}
linux> ./norace
Hello from thread 0
Hello from thread 1
Hello from thread 2
Hello from thread 3
Deadlocks

세마포어는 deadlock을 발생시킬 수 있는 잠재성을 지니다. Deadlock이란, 여러 스레드가 어떤 조건을 기다리며 모두 블락(block)되어 있고, 해당 조건은 절대 참이 되지 않는 문제이다. Figure 21은 두 개의 세마포어를 상호 배제(mutual exclusion)을 위해서 사용하는 두 스레드에 대한 진행 그래프이다. 해당 figure가 암시하는 코드를 작성하는 프로그래머는 P와 V 연산을 잘못된 순서로 작성하여, 두 세마포어에 대한 금지 영역(forbidden regions)이 겹치게(overlap) 만들었다. 이때 어떤 실행 경로가 교착 상태 지점 d에 도달하게 되면, 더 이상의 진행이 불가능해진다. 왜냐하면 겹쳐진 금지 영역들이 모든 합법적인 방향으로의 진행을 차단하기 때문이다. 해당 프로그램은 deadlock에 봉착한 것이며, 각 스레드는 다른 스레드가 수행할 V 연산을 기다리고 있지만, 그 연산은 절대로 일어나지 않는다. 이 겹쳐진 금지 영역들은 deadlock 영역이라는 상태 집합을 형성하며, 이는 어떤 실행 경로가 해당 deadlock 영역에 진입하며, deadlock을 겪는 다는 것을 의미한다. 이에 따라 프로그램은 deadlock 영역에는 진입할 수 있지만, 그로부터 탈출할 수는 없다.
Deadlock의 큰 문제 중 하나는 예측 불가능하기 때문이다. 운이 좋으면 프로그램이 deadlock을 비껴나가서 실행될 수도 있겠지만, 어떤 경우에는 그렇지 않다. Figure 21은 이를 잘 보여준다. 또한 재현이 어렵기 때문에, 디버깅하기에도 어렵다.

프로그램이 deadlock에 빠지는 원인은 다양하지만, figure 22와 같이 이진(binary) 세마포어를 상호 배제를 위해 사용할 경우에는 다음과 같은 간단한 규칙을 적용하여 이를 회피할 수 있다:
모든 뮤텍스들에 대해 total ordering이 주어졌을 때, 프로그램은 각 스레드가 뮤텍스를 그 순서대로 획득하고, 역순으로 해제해야 한다.
예를 들어 figure 21에서의 deadlock은 각 스레드가 먼저 s를 잠그고, 그 다음 t를 잠그도록 수정하여 해결할 수 있다. 이렇게 변경된 프로그램에 대한 진행 그래프는 figure 22과 같다:
각주
- ↑ 즉, 서버가 데이터를 실제로 read() 했는지 여부는 확인하지 않는다.
- ↑ 서버는 아직 Client 1만 처리 중이므로, Client 2에 대해 accept()도 하지 않았고, 데이터를 읽지도 않은 상태이다.
- ↑ 해당 디스크립터 집합이 수용가능한 최대 디스크립터의 수를 의미한다.
- ↑ 타임아웃이 발생하면 0을 반환하고, 오류 시에는 -1을 반환한다.
- ↑ 즉,
read()와 같은 함수가 실행되었을 때 즉각적으로 데이터를 가져올 수 있는 상태를 의미한다. - ↑ "디스크립터 dk가 읽기 준비가 되기를 기다리는 중”
- ↑ “디스크립터 dk가 읽기 준비가 됨”
- ↑ “디스크립터 dk로부터 한 줄의 텍스트를 읽고 echo() 하기”
- ↑ 각 쓰레드를 식별하기 위해서 사용되는 정수 thread ID이다.
- ↑ stack 메모리 공간은 공유하지 않는다. 이 덕분에 쓰레드는 메모리를 효율적으로 공유하면서도 함수 호출/로컬 변수의 충돌을 방지할 수 있다.
- ↑ Code/Data/Stack은 메모리의 Code 영역, Data 영역, Stack 영역, Heap 영역이 모두 포함한다.
- ↑ Local stack은 공유하지 않는다.
- ↑ 동기화 연산(P, V)은 단일 메모리 업데이트에 비해 매우 비싸다.
- ↑ 수정된 데이터를 메모리에 바로 쓰지 않고, 나중에 해당 데이터가 캐시에서 제거될 때만 메모리에 반영하는 캐시를 의미한다.
- ↑ 서로 겹칠 수 있는 부류들이다.
- ↑ 스레드-안전하게 바꾸기 쉬우며, 단지 공유 변수를 P, V 등의 동기화 연산으로 보호하면 된다.
- ↑ 이 경우, 해당 함수를 호출한 함수가 상태 정보를 인자로 넘겨야 한다.
- ↑ 이러한 방식은 해당 함수 뿐 아니라 호출자의 코드도 변경해야 하기 때문에, 대형 프로그램에서는 수정이 어렵다는 단점이 있다.