Web page(웹 페이지)는 object들로 구성되어 있다. 이때 object file은 HTML file, JPEG file, Java applet, audio file등이 될 수 있다. 따라서 웹 페이지는 몇몇 referenced object들과 base HTML file로 이루어져있다. 예를 들어, 웹 페이지에 HTML 텍스트와 다섯 개의 JPEG 이미지가 포함되어 있다면, 해당 웹 페이지는 base HTML file과 다섯 개의 JPEG 이미지라는 여섯 개의 객체를 가지고 있다. 이때 base HTML file은 페이지의 다른 객체들을 해당 객체들의 URL을 통해 참조한다.
이때 URL은 위와 같이 객체가 있는 host server의 이름과 객체의 경로가 저장된 path name으로 구성된다.
HyperText Transfer Protocol(HTTP)는 이러한 웹페이지를 구현하는 Web의 application protocol이다. HTTP는 client-server model을 사용한다. 이때 client와 server는 대략적으로 다음과 같이 정의되고 사용된다.
client: HTTP protocol을 이용해 Web object들을 요청하고 수신하고 화면에 나타내는 browser를 의미한다.[1]
server: HTTP protocol을 사용하여 요청에 응답해 object들을 전송한다.
HTTP는 TCP를 기본적인 transport protocol을 사용한다. HTTP client는 TCP connection을 setup한 후[2], 서로의 프로세스에 존재하는 socket을 통해 TCP에 접근한다. 그리고 HTTP message들이 browser와 Web server사이에서 교환된다. 이때 서로서로 HTTP messages를 socket에 전송하면, 상대 프로세스의 socket 까지는 전적으로 TCP protocol에 의해서 처리된다. 모든 message가 교환된 후, TCP connection은 종료된다.
이때 HTTP는 stateless하다. 이때 state 특성을 가지고 있다면 특정 시간에 특정 변수가 어떤 값을 가지고 있는지를 기억하고 있다는 것을 의미한다. 따라서 HTTP를 사용하는 server는 과거에 client가 요청했던 정보에 대해 저장하지 않는다. 즉, 이 때문에 어떤 browser가 몇 초내에 동일한 object를 여러번 요청하더라도, 이미 전송했다고 응답하는 대신 요청이 들어온 만큼 object를 다시 송신한다.
Back-of-the-envelope calculation for the time needed to request and receive an HTML fileHTTP client는 TCP connection을 URL과 port 80을 바탕으로 HTTP server에 initiate한다.
해당 URL host에 있는 HTTP server는 port 80에 대한 연결을 기다린다.
따라서 server는 connection을 initiate한 client를 식별하며 handshaking을 완료한다.
해당 message는 someDepartment/home.index에 해당하는 object를 client가 원한다는 것을 가리킨다.
HTTP server는 request message를 받고, response message를 만들고 socket을 통해서 전송한다.
response message는 요청받은 object를 포함한다.
HTTP server는TCP 연결을 종료한다.
이때 client가 response message를 온전히 받았음을 확인하기 전까지는 실제로 연결을 종료하지 않는다.
HTTP client는 base HTML file을 포함하는 response message를 받고, 이를 diplay한다.
이후 html을 parsing하여 10개의 JPEG file에 대한 참조를 찾는다.
1~5까지의 단계를 각각의 JPEG file에 대해 반복한다.
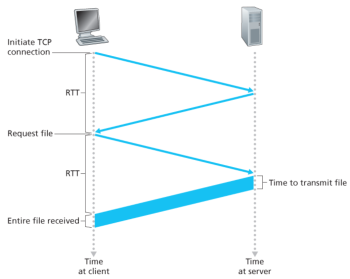
즉 11개의 object들을 처리하기 위해서는 11개의 TCP connection이 생성된다. 이때 각각의 TCP connection을 생성하는 데에는 RTT가 소요된다. RTT란 small packet이 client에서 server까지 왕복하는 시간을 의미한다. 이때 HTTP response time은 다음과 같이 구해진다. 먼저, TCP 연결을 개시하기 위해서 RTT가 한번 소요된다. 또한 request message가 server로 전송되고 반환된 response message의 몇 byte가 client에 전송되는데 RTT가 또 한번 소요된다. 이후로는 file transmission 시간 만큼 소요된다. 따라서, 다음의 식이 성립한다.
non-persistant HTTP response time = 2 RTT + file transmission time
Persistent HTTP
non-persistant HTTP는 object 하나를 요청하고 이를 display하는데 2번의 RTT가 소요된다. 이는 각각의 object에 대한 각각의 TCP 연결에 대해 overhead[4]가 동반된다는 것을 의미한다.
이러한 문제들을 해결하기 위해 최근에는 persistant HTTP가 주로 사용된다. 해당 HTTP에서 server는 response message를 전송한 후에도 connection을 열어둔다. 이를 통해서 후속의 HTTP message들이 client와 server 사이에서 송수신될 수 있다. 또한 client는 웹페이지를 로드하는 동안 referenced object를 만나면 이에 대한 request message를 즉각적으로 보낸다. 이를 통해서 non-persistent HTTP에서 client가 request message를 전송한 이후 이에 대한 response message를 받을 때까지 걸리는 시간을 줄인다. 또한 모든 referenced object를 가져오는 데 RTT 자체는 오직 한번만 소요된다. 첫 RTT를 통해서 TCP 연결이 열린 이후로 여러 객체가 추가적인 RTT 없이 빠르게 처리되기 때문이다.