TCP
상위 문서: Transport Layer
개요
TCP(Transmission Control Protocol)는 연결 지향형(connection-oriented)이라고 불린다. 왜냐하면, 한 프로세스가 다른 프로세스에게 데이터를 보내기 시작하기 전에, 양쪽 프로세스는 먼저 서로 handshake를 수행해야 하기 때문이다. 즉, 데이터 전송에 앞서 몇 개의 초기 segment를 주고받아, 앞으로의 데이터 전송을 위한 매개변수를 설정해야 한다. 이러한 handshaking은 TCP가 riliable하고, in-order한 byte stream을 제공하도록 한다. 이때, TCP 연결은 항상 point-to-point이며, 이는 단 하나의 송신자와 단 하나의 수신자 사이에 연결이 형성된다는 것을 의미한다.
또한, TCP 연결은 양방향(full-duplex) 서비스를 제공한다. 즉, 한 호스트의 프로세스 A와 다른 호스트의 프로세스 B 사이에 TCP 연결이 있으면, application layer의 데이터는 A → B로 흐름과 동시에 B → A로도 흐를 수 있다. TCP는 그 외에도 flow control, congestion control과 같은 여러 서비스도 부가적으로 제공한다.
TCP segment Structure

TCP가 다루는 데이터의 단위는 세그먼트(segment)이며, 세그먼트는 헤더 필드들과 데이터 필드(payload)로 구성된다. 데이터 필드는 application layer의 데이터의 일부(청크)를 담는다. 세그먼트의 데이터 필드 최대 크기는 MSS(Maximum Segment Size)에 라고 불린다. TCP가 웹페이지의 이미지처럼 큰 파일을 전송할 때, 보통 해당 파일을 MSS 크기의 청크로 나눈다.[1]
Figure1은 TCP 세그먼트의 구조를 보여준다. UDP와 마찬가지로 TCP 헤더에는 송신자/수신자의 port 번호가 포함되어 있으며, 이는 multiplexing/demultiplexing에 사용된다. 또한 UDP와 마찬가지로 checksum field도 있다. 그리고 sequence number 필드와 ACK 필드는 TCP가 rdt 서비스를 구현하는데 사용된다.
Sequence Numbers and Acknowledgment Numbers
TCP 세그먼트 헤더에서 가장 중요한 필드 중 두 가지는 시퀀스 번호(sequence number) 필드와 ACK(acknowledgment number) 필드이다. 이 필드들은 TCP의 신뢰성 있는 데이터 전송 서비스를 구성하는 데 있어 핵심적인 부분이다.
Sequence Number

TCP는 데이터를 구조화되지 않았지만, 순서가 있는 바이트의 스트림(stream of bytes)으로 본다. 즉 어떤 "메시지의 단위"와 같은 개념이 아니라 데이터를 단순히 바이트가 나열된 stream으로 본다. 이때, 바이트 스트림은 세그먼트의 헤더 필드를 제외한 payload로만 구성되어 있다. 예를 들어, 500,000바이트짜리 파일을 보내면 TCP는 이를 연속된 바이트들로 보고, 각 바이트에 0, 1, 2, ..., 499999와 같이 순서 번호(시퀀스 번호) 를 매긴다. 이때, 시퀸스 번호는 세그먼트 안의 데이터가 바이트 스트림에서 어디서 시작하는지를 나타내는 번호이다.
예를 들어, MSS가 1000바이트이고, 파일의 크기가 500,000바이트라면 500개의 세그먼트가 생긴다. 이때 각각의 세그먼트에는 바이트 스트림 내의 시작 바이트가 시퀸스 번호로 들어간다. 첫 번째 세그먼트는 바이트 0~999에 해당하며, 시퀸스 번호가 0이다. 두 번째 세그먼트는 바이트 1000~1999에 해당하며, 시퀸스 번호가 1000이다. 세 번째 세그먼트는 바이트 2000~2999에 해당하며, 시퀸스 번호가 2000이다. 이와 같은 방식으로 각 세그먼트는 자신이 바이트 스트림 내에서 어디서 부터 시작하는 데이터인지를 시퀀스 번호로 알려준다.
이때, 예시에서는 시퀀스 번호를 0부터 시작한다고 했지만, 실제 TCP는 각 연결마다 무작위 시퀀스 번호(ISN)를 선택한다.
Acknowledgment Number
ACK은 반대측에서 받을 것으로 기대하는 바이트의 시퀸스 번호를 말해주는 값이다. 예를 들어, A가 B에게 데이터를 받고 있고, A가 B로부터 0~535번 바이트를 받았다면, A는 B에게 보낼 TCP 세그먼트의 ACK 필드에 536을 넣는다. 즉, ACK는 ‘수신측이 현재까지 이 바이트까지 받았고, 그 다음 바이트부터 달라’는 의미를 갖는 번호이다.
이번에는 호스트 A가 호스트 B로부터 시퀀스 번호 0번부터 535번까지의 바이트를 포함한 세그먼트 하나와, 시퀀스 번호 900번부터 1,000번까지의 바이트를 포함한 또 다른 세그먼트를 받았다고 하자. 이때 어떠한 이유로 A가 536번부터 899번까지의 바이트를 받지 못했다면, 이 경우 A는 누락된 바이트 스트림을 복원하기 위해서 시퀸스 번호 536을 가지는 새그먼트를 받고자 한다. 따라서 A가 B로 보내는 다음 세그먼트의 ACK 필드에는 536이 들어간다. 즉, TCP는 바이트 스트림 내에서 처음으로 누락된 바이트에 대한 ACK을 전송하기 때문에 TCP는 cumulative acknowledgment을 사용한다고 볼 수 있다.
Handing out of order
TCP는 세그먼트가 순서대로 도착하지 않는 상황(out-of-order)을 어떻게 처리할지에 대해서 RFC에서 강제하지 않으므로, 구현자에게 어떻게 처리할지를 맡긴다. 이 경우 선택지는 두개이다. 하나는 순서대로 도착하지 않은 세그먼트는 그냥 폐기하는 방식이다.[2] 다른 하나는 순서대로 도착하지 않은 세그먼트를 버퍼에 저장하고, 누락된 세그먼트를 수신하면 이어붙이는 방식이다.[3]
예를 들어, 두 번째 세그먼트가 도착하기 전에 세 번째 세그먼트가 도착했다면, 첫 번째 방식은 세번째 세그먼트를 그냥 폐기하는 것이고, 두번째 방식은 세번째 세그먼트를 버퍼에 보관한 이후, 두 번째 세그먼트가 도착하면 바이트 스트림을 복원한다. 이때 두 번째 방식이 네트워크 효율성이 더 높으므로, 대부분의 TCP 구현은 두 번째 방식을 택한다.
즉, TCP 구현은 cumulative ACK을 사용한다는 점에서는 Go-Back-N 방식과 유사하지만, 순서에 어긋난 세그먼트를 버퍼에 보관하고 이를 활용한다는 점에서는 Selective Repeat 방식과 유사하다. 따라서 TCP는 Go-Back-N 방식보다는 Selective Repeat에 더 가까운 하이브리드 방식으로 구현된다고 볼 수 있다.
Telent: Example for Sequence and Acknowledgment Numbers

이 문단에서는 RFC 854에서 정의된 Telnet 프로토콜을 이용해 간단한 상황에서 시퀸스 번호와 ACK이 어떻게 사용되는지에 대해 다룬다. 호스트 A와 호스트 B가 Telent 프로토콜 세션을 이용해 통신을 하고, 호스트 A가 세션을 시작하므로 클라이언트이고, 호스트 B는 서버에 해당한다. 이 상황에서는 A가 문자 c를 입력하면, c가 서버로 전송되어 c의 복사본을 클라이언트의 화면에 띄운다.
오른쪽의 그림처럼, 클라이언트와 서버의 초기 시퀸스 번호(ISN)가 42와 79이라면 아래와 같이 세개의 세그먼트가 서로간에 전송된다.
- 첫 번째 세그먼트는 클라이언트에서 서버로 전송된다. 데이터 필드에는 문자 'c'의 1바이트 ASCII 코드 값이 들어있으며, 시퀸스 번호는 42이다. 클라이언트는 서버로 부터 아무 데이터를 받지 않았으므로, ACK는 79이다.(서버가 보낼 다음 바이트)
- 두 번째 세그먼트는 서버에서 클라이언트로 전송된다. 이 세그먼트는 클라이언트로부터 받은 데이터에 대한 ACK을 답신하며[4], 그와 동시에 문자 'c'를 다시 클라이언트로 에코하기 위해 데이터 필드에 'c'의 ASCII 코드 값을 포함한다. 이렇게 세그먼트에 ACK를 데이터 세그먼트에 함께 실어서 보내는 방식은 piggybanking이라고 부른다.
- 세 번째 세그먼트는 클라이언트에서 서버로 전송된다. 해당 세그먼트의 목적은 서버로부터 받은 데이터에 대한 ACK을 답신하는 것이다. 해당 세그먼트는 데이터 필드가 비어있으므로, piggybank 방식이 아니다. 해당 ACK의 값은 80이고, 시퀸스 번호는 43이다.
Round-Trip Time Estimation and Timeout
TCP는 rdt3.0 프로토콜과 마찬가지로 손실된 세그먼트를 복구하기 위해 타임아웃/재전송(timeout/retransmit) 메커니즘을 사용한다. 이때 timeout interval을 설정하는 것은 까다로운 문제이다. 이때, timeout interval은 RTT보다는 길어야 한다.
EstimatedRTT

RTT를 추정히기 위해서는 SampleRTT를 활용한다. SampleRTT는, 세그먼트를 전송한 시점(즉, IP로 전달한 순간)과 그 세그먼트에 대한 ACK을 받은 시점 사이의 시간이다. 이때 재전송된 세그먼트에 대해서는 SampleRTT를 계산하지 않으며, 한번만 전송된 세그먼트에 대해서만 측정된다. 이때 SampleRTT 값은 라우터 내의 혼잡이다 end system의 부하에 따라, 각각의 세그먼트에 따라 달라지며, SampleRTT는 매우 다양하게 나타난다. 따라서 EstimatedRTT라는 개념을 활용하여 SampleRTT 값들의 어떠한 평균을 계산한다. 이때 EstimatedRTT는 새로운 SampleRTT 값을 얻을 때마다 TCP는 EstimatedRTT를 다음 공식으로 업데이트된다:
typically,
EstimatedRTT는 SampleRTT 값들의 EWMA(Exponential Weighted Moving Average)이다. 해당 가중 평균은 최근의 측정값이 더욱 비중있게 반영되며, EstimatedRTT의 업데이트가 반복됨에 따라 과거의 SampleRTT의 가중치는 지수적으로 감소한다. 이를 통해서 현재의 네트워크 혼잡 상태를 더욱 잘 반영할 수 있다.
DevRTT
RTT의 평균값뿐만 아니라, 그 변동성을 측정하는 것도 중요한데, RTT의 변동성은 DevRTT라고 한다. DevRTT는 SampleRTT가 EstimatedRTT로부터 평균적으로 얼마나 벗어나는지를 추정한 값이며, 아래 공식을 통해서 나타낸다.
typically,
이때, DevRTT는 SampleRTT와 EstimatedRTT 간의 차이에 대한 EWMA이다.
Setting and Managing the Retransmission Timeout Interval
EstimatedRTT와 DevRTT 값이 주어졌을 때, TCP의 timeout interval은 당연히 EstimatedRTT보다 크거나 같아야 한다. 그렇지 않으면 불필요한 재전송이 발생할 수 있다. 하지만 timeout interval이 EstimatedRTT보다 너무 크다면, 세그먼트가 손실되었을 때 TCP가 재전송을 너무 늦게 하게 되어 데이터 전송 지연이 커질 수 있다. 따라서 타임아웃 간격은 EstimatedRTT에 어느 정도의 여유(margin)를 더한 값으로 설정하는 것이 바람직하며, 이때 DevRTT가 활용된다. 이러한 상황들을 고려하여 timeout interval은 아래 공식을 통해 구해진다.
TCP reliable data transfer
TCP는 network layer의 best-effort(unrilable) 서비스를 바탕으로 rdt(rilable data transfer) 서비스를 만든다. TCP의 rdt는 "수신 버퍼에서 프로세스가 읽어들이는 바이트 스트림이 손상되지 않고, 누락 없이, 중복 없이, 올바른 순서로 이루어지며, 송신 측 시스템이 보낸 바이트 스트림과 정확히 일치한다"는 것을 보장한다. TCP는 pipelined 세그먼트들을 cumulative ACK과 하나의 타이머를 이용하여 rdt를 구현한다.
우선, 중복 ACK과 flow, congestion control은 무시한 채로 TCP 송신자가 어떻게 rdt를 구현하는지 살펴보자. TCP 송신자에서 데이터 전송 및 재전송과 관련하여 주요한 이벤트는 1) application layer로부터 데이터를 수신하는 것, 2) 타이머가 만료되는 것, 3) ACK를 수신하는 것이다. 각각의 TCP 송신자는 아래와 같이 각 상황에 대처한다.
1) TCP는 application layer로부터 데이터를 수신했을 때 이를 세그먼트에 캡슐화하고 이를 network layer로 전달한다. 이때 각 세그먼트에는 해당 세그먼트의 첫 번째 데이터 바이트에 대한 시퀀스 번호가 포함되며, 다른 세그먼트에 대해 타이머가 작동하고 있지 않다면 TCP는 타이머를 시작한다. 즉, 타이머는 가장 오래 확인되지 않은[5] 세그먼트에 대해 연결되어 있다.[6]
2) 송신자에게 timeout 이벤트가 발생하면, TCP는 해당 세그먼트를 재전송하고 타이머를 재시작한다.
3) 송신자가 수신자로부터 ACK이 도착하면, TCP는 ACK의 값 y를 SendBase[7]와 비교한다. TCP는 cumulative ACK를 사용하므로, ACK 값 y는 바이트 번호 y 이전의 모든 바이트가 수신되었음을 의미한다. 즉, y > SendBase 라면, 이 ACK는 아직 확인되지 않은 하나 이상의 세그먼트를 확인한 것이므로 송신자는 SendBase를 y로 업데이트하며, 아직 확인되지 않은 세그먼트가 남아 있다면 타이머를 재시작한다.
또한 TCP 수신자의 주요한 이벤트는 1) 순서대로 세그먼트가 왔고, 그 앞의 세그먼트는 모두 ACK되어 있음, 2) 순서대로 세그먼트가 왔고, 그 앞의 세그먼트 중에는 ACK되지 않은 것이 존재, 3) 순서대로 세그먼트가 도착하지 않음, 4) 바이트 스트림의 누락된 부분을 채우는 세그먼트가 도착하는 것이다. 각각의 TCP 수신자는 아래와 같이 각 상황에 대처한다.
1) 순서대로 세그먼트가 왔고, 그 앞의 세그먼트는 모두 ACK되어 있는 경우, 최대 500ms까지 기다린 후 ACK을 전송한다. 이는 다음 세그먼트가 도착할 경우 그에 대한 ACK을 또 보내야 하기 때문이며, 이를 통해서 ACK의 전송 빈도를 줄여 네트워크 부하를 감소시킬 수 있다.
2) 순서대로 세그먼트가 왔고, 그 앞의 세그먼트 중에는 ACK되지 않은 것이 있을 경우, 즉시 cumulative ACK[8]을 전송한다. 이를 통해서 duplicate ACK를 방지할 수 있다.
3) 순서대로 세그먼트가 도착하지 않은 경우, 즉시 duplicate ACK[9]를 전송한다. 이를 통해서 송신자에게 누락된 부분의 바이트를 기다리고 있다고 반복적으로 알려줄 수 있다. 만약 duplicate ACK이 일정 횟수에 도달하면, 송신자는 fast retransmit를 실행한다.
4) 바이트 스트림의 누락된 부분을 채우는 세그먼트가 도착하면 즉시 ACK를 전송하여 송신측에게 누락된 부분이 채워지고 있음을 알린다.
TCP: retransmission scenarios
- Three scenario
-
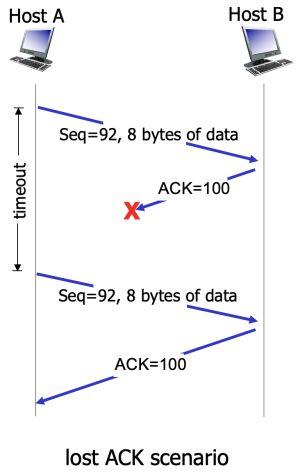 Figure 3. Lost ACK scenario
Figure 3. Lost ACK scenario -
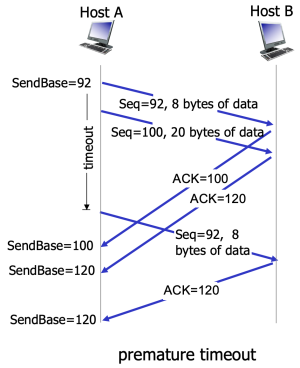 Figure 4. Premature timeout scenario
Figure 4. Premature timeout scenario -
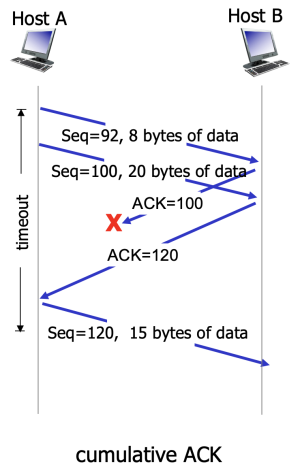 Figure 5. Cumulative ACK
Figure 5. Cumulative ACK



First scenario
호스트 A가 호스트 B에게 세그먼트 하나를 제공하며, 시퀀스 번호는 92, 데이터의 크기가 8바이트이다. A는 이 세그먼트를 보낸 후, ACK 번호 100이 포함된 세그먼트를 B로부터 기다린다. 이때 A의 세그먼트는 B에 제로 도착했지만, B가 보낸 ACK은 네트워크에서 손실되었다. 이 경우, 타임아웃 이벤트가 발생하고, A는 같은 세그먼트를 재전송한다. 하지만 B는 이 재전송된 세그먼트를 수신했을 때, 시퀀스 번호를 통해 이미 수신한 데이터임을 인식하고 재전송된 세그먼트 내 바이트들을 폐기(discard)한다.
Second scenario
호스트 A가 두 개의 세그먼트를 연속적으로 전송하며, 첫 번째 세그먼트는 시퀀스 번호 92, 데이터 8바이트이고 두 번째 세그먼트는 시퀀스 번호 100, 데이터 20바이트이다. 두 세그먼트 모두 B에 정상적으로 도착하고, B는 각 세그먼트에 대해 개별적으로 ACK(100), ACK(120)를 전송하지만, 두 ACK가 모두 timeout이 될 때까지 A에 돡하지 못한다. 이 경우, 타이머는 첫 세그먼트에만 연결되어 있으므로 첫 세그먼트를 재전송하고 타이머를 재시작한다. 이후 두 번째 세그먼트에 대한 ACK가 도착하더라도 A는 두 번째 세그먼트를 재전송하지 않는다. 타이머가 재전송된 첫 세그먼트에 연결되어 있기 때문이다.
Third scenario
A가 두 번째 시나리오와 같은 방식으로 두 개의 세그먼트를 전송하지만, 첫 번째 세그먼트에 대한 ACK는 네트워크에서 손실되고 timeout이 되기전에 ACK(120)이 A에 도착한다. 이 경우 A는 B가 119에 해당하는 바이트까지 정상 수신되었음을 알고, 두 세그먼트를 보두 재전송하지 않는다.
Fast Retransmit

Timeout 기반의 재전송의 문제점 중 하나는, 타임아웃 시간 자체가 상대적으로 길 수 있다는 점이다. 세그먼트가 손실되었을 때, 이 긴 타임아웃 기간 때문에 송신자는 손실된 패킷을 재전송하기까지 기다려야 하고, 그 결과 end-to-end delay가 증가한다는 것이다. 이 때문에 송신자는 duplicate ACK를 활용해 timeout 이벤트가 발생하기 전에 이를 감지할 수 있다.
송신자는 일반적으로 여러 세그먼트들을 속적으로 전송하므로, 그중 하나라도 손실되면 중복 ACK가 여러 번 연속해서 도착할 가능성이 높다. 이 때문에 TCP 송신자가 동일한 데이터에 대해 duplicate ACK를 3번 수신하면, 송신자는 해당 duplicate ACK이 전송할 것을 요청하는 세그먼트가 손실되었다고 판단하고 그 즉시 fast retransmit를 수행한다. 이는 해당 세크먼트의 타이머가 만료되기 전, 손실된 것으로 추정되는 세그먼트를 즉시 재전송하는 것이다.
각주
- ↑ 단, 마지막 청크는 MSS보다 작을 수 있다
- ↑ Go-Back-N 방식에 해당한다.
- ↑ Selective Repeat 방식과 유사하다.
- ↑ ACK 번호를 43으로 설정하여, 서버는 바이트 42까지 성공적으로 받았고 43번 이후를 기다리고 있다고 알린다.
- ↑ ACK을 답신 받지 못한
- ↑ 타이머의 timeout interval은 EstimatedRTT와 DevRTT를 기반으로 계산된다.
- ↑ 송신자측의 가장 오래 확인되지 않은 바이트의 시퀸스 번호이다. 따라서 SendBase - 1은 수신 측에서 올바르게, 순서대로 수신된 마지막 바이트의 번호이다.
- ↑ ACK 번호는 다음에 수신하기를 기대하는 바이트 번호에 해당한다.
- ↑ ACK 번호는 여전히 기다리고 있는 바이트 번호에 해당한다.