쓰레드의 장점 중 하나는 여러 쓰레드가 동일한 프로그램 변수를 쉽게 공유할 수 있다는 것이다. 이때 보통 단순히 “전역 변수는 공유되고, 스택 변수는 독립적이다”라고 말하지만, 현실은 그렇게 단순하지 않다. 먼저, 어떤 변수 x가 공유(shared)된다는 것은, 둘 이상의 쓰레드가 해당 변수의 인스턴스[1]를 참조한다는 뜻이다. 이때 어떤 C 프로그램 변수의 공유 여부를 이해하기 위해 다음과 같은 기본적인 질문들을 검토해야 한다:
쓰레드의 메모리 모델은 무엇인가?
해당 모델에 대해, 변수 인스터스는 메모리에 어떻게 매핑되는가?
이러한 인스턴스를 참조하는 쓰레드는 몇 개인가?
그리고 이에 대해 구체적으로 논의하기 위해서 아래와 같은 코드를 예제로서 사용한다:
#include"csapp.h"#define N 2void*thread(void*vargp);char**ptr;//전역 변수, 메인 쓰레드 내의 msg 배열에 접근할 수 있도록 설정됨intmain(){inti;pthread_ttid;char*msgs[N]={"Hello from foo","Hello from bar"};//문자열 배열 선언ptr=msgs;for(i=0;i<N;i++)//N(2) 개의 쓰레드를 만든다.Pthread_create(&tid,NULL,thread,(void*)i);//i를 포인터로 캐스팅하여 인자로 전달Pthread_exit(NULL);}void*thread(void*vargp){intmyid=(int)vargp;//쓰레드에 전달된 인자를 받음staticintcnt=0;//여러번 실행되도 한 번만 초기화됨printf("[%d]: %s (cnt=%d)\n",myid,ptr[myid],++cnt);//id에 따라 문자열 배열 출력, 총 쓰레드 실행 횟수 출력returnNULL;}
위 예제 프로그램은 하나의 메인 쓰레드가 두 개의 피어 쓰레드를 생성하는 구조이다. 메인 쓰레드는 각각의 동료 쓰레드에게 고유한 ID를 전달하며, 동료 쓰레드는 이 ID를 사용해 그에 대응되는 메시지와 함께 쓰레드 루틴이 호출된 총 횟수를 출력한다.
Threads Memory Model
동시에 실행되는 쓰레드 모음(pool)은 하나의 프로세스 컨텍스트(context)에서 실행된다. 각 쓰레드는 고유한 쓰레드 컨텍스트를 가지며, 이에는 TID, 스택, 스택 포인터, 프로그램 카운터, 조건 코드(Condition codes), 범용 레지스터(general-purpose register) 값들이 포함된다. 그리고 각 쓰레드는 다른 쓰레드들과 나머지 프로세스 컨텍스트를 공유한다. 공유되는 컨텍스트에는 Code/Data/Heap 메모리 공간, 공유 라이브러리, 열린 파일 디스크립터 등을 포함하는 전체 가상 주소 공간(virtual address space)이 포함된다.
이러한 관점에서 볼 때, 쓰레드는 다른 쓰레드의 레지스터 값을 읽거나 쓸 수는 없다. 하지만 어떤 쓰레드든 공유되어 있는 가상 메모리(virtual memory)의 위치에는 접근할 수 있으며, 만약 한 쓰레드가 해당 메모리 주소를 수정하면, 다른 모든 쓰레드는 해당 주소를 읽을 경우 변경 사항을 읽게 된다. 따라서 레지스터는 절대 공유되지 않지만, 가상 메모리는 항상 공유된다.
개별 쓰레드 스택에 대한 메모리 모델은 명확하지 않다. 이러한 스택은 가상 주소 공간의 스택 영역에 존재하며, "일반적으로" 각 쓰레드가 자신의 스택에만 접근한다. "일반적으로"라고 표현한 이유는 각각의 쓰레드 스택들이 다른 쓰레드들로부터 보호되지 않기 때문이다. 따라서 어떤 쓰레드가 다른 쓰레드의 스택에 대한 포인터를 얻는다면, 그 스택의 어느 부분이든 읽거나 쓸 수 있다. 예제 코드에서도 전역 변수 ptr을 통해 피어 쓰레드가 메인 쓰레드의 스택에 저장된 msg 문자열 배열을 참조하는 것이 나와 있다.
Mapping Variables to Memory
쓰레드 기반의 C 프로그램에서, 변수는 어떻게 저장되는지에 따라 아래와 같이 가상 메모리에 매핑된다:
1. 전역 변수(Global variables)
전역 변수는 함수 외부에서 선언된 모든 변수를 의미한다. 실행 시점에 가상 메모리의 읽기/쓰기(read/write) 영역은 각각의 전역 변수에 대해 정확히 하나의 인스턴스를 가진다. 이 인스턴스는 어떤 쓰레드에서든 참조 가능하다. 예제 코드에서 선언된 전역 변수 ptr은 가상 메모리의 읽기/쓰기 영역에 하나의 인스턴스를 가진다.
2. 자동 지역 변수(Local automatic variables)
자동 지역 변수는 static 속성 없이 함수 내부에 선언된 변수이다. 실행 시점에 각 쓰레드의 스택에는 해당 지역 변수의 인스턴스가 하나씩 존재한다. 이는 여러 쓰레드가 동일한 루틴을 실행하는 경우에도 마찬가지이다. 예를 들어, 지역 변수 tid는 메인 쓰레드의 스택에 하나의 인스턴스를 가지고 있으며, 이를 tid.m이라 표기한다. 다른 예시로는, 역 변수 myid는 두 개의 인스턴스를 가지며, 하나는 피어 쓰레드 0의 스택에, 다른 하나는 피어 쓰레드 1의 스택에 존재한다. 이를 각각 myid.p0, myid.p1이라 표기한다.
3. 정적 지역 변수(Local static variables)
static 속성으로 선언된 함수 내부 변수는 정적 지역 변수이다. 전역 변수와 마찬가지로, 가상 메모리의 읽기/쓰기 영역에 정확히 하나의 인스턴스를 가진다. 예제 프로그램에서 선언된 정적 변수 cnt는 여러 피어 쓰레드에 의해서 선언하더라도, 실제로는 한 번만 선언되며, 이는 가상 메모리의 읽기/쓰기 영역에 존재한다. 모든 피어 쓰레드는 이에 접근하여 cnt의 인스턴스를 읽고 쓴다.
Shared Variables
변수 v가 공유된(shared)다는 것은 변수 v의 인스턴스 중 하나 이상을 둘 이상의 쓰레드가 참조한다는 뜻이다. 예제 프로그램에서 변수 cnt는 런타임 인스턴스가 하나 뿐인데, 이를 두 개의 피어 쓰레드가 모두 참조하므로 공유된 변수이다. 반면, myid는 인스턴스가 두 개 있으며, 각각의 인스턴스는 한 쓰레드에 의해서만 참조되므로 공유되지 않는다. 이때, msgs와 같은 자동 지역 변수도 공유될 수 있다는 점을 주의해야 한다. 이를 바탕으로 ptr, cnt, i.m, msg.m, myid.p0, myid.p1의 공유 여부를 표로 나타내면 다음과 같다.
변수 인스턴스
메인 쓰레드에 의해 참조되는가?
쓰레드 p0에 의해 참조되는가?
쓰레드 p1에 의해 참조되는가?
공유되는가?
ptr
yes
yes
yes
yes
cnt
no
yes
yes
yes
i.m
yes
no
no
no
myid.p0
no
yes
no
no
myid.p1
no
no
yes
no
Synchronizing Threads
쓰레드의 큰 장점 중 하나는 쓰레드 간에 편리하게 변수를 공유할 수 있다는 것이다. 하지만 이는 때때로 심각한 동기화 오류를 초래하기도 한다. 이에 대해 설명하기 위해, 아래의 badcnt.c 프로그램을 참고하자:
/* WARNING: This code is buggy! */#include"csapp.h"void*thread(void*vargp);/* Thread routine prototype */volatilelongcnt=0;//counter로 사용되는 전역 변수intmain(intargc,char**argv){longniters;pthread_ttid1,tid2;/* Check input argument */if(argc!=2){printf("usage: %s <niters>\n",argv[0]);exit(0);}niters=atoi(argv[1]);//thread에 있는 루프의 반복 횟수//쓰레드 생성, niters의 주소를 넘겨서 각 쓰레드가 niters번 루프 돌도록 함Pthread_create(&tid1,NULL,thread,&niters);Pthread_create(&tid2,NULL,thread,&niters);//두 쓰레드가 모두 종료될 때까지 대기Pthread_join(tid1,NULL);Pthread_join(tid2,NULL);/* Check result */if(cnt!=(2*niters))printf("BOOM! cnt=%ld\n",cnt);//예측된 결과(cnt = 2 * niters)가 아님elseprintf("OK cnt=%ld\n",cnt);//예측된 결과(cnt = 2 * niters)가 맞음exit(0);}/* Thread routine */void*thread(void*vargp){longniters=*((long*)vargp);for(longi=0;i<niters;i++)cnt++;//인자로 받은 niters 만큼 cnt를 증가returnNULL;}
위 프로그램은 두 개의 쓰레드를 생성하며, 각 쓰레드는 이름의 전역 공유 카운터 변수인 cnt를 반복문의 반복 횟수 만큼 증가시킨다. 이때 각 쓰레드가 cnt를 niters 횟수만큼 증가시키기 때문에, 최종 값이 2 * niters인 것은 언뜻 명확해 보인다. 하지만 이를 리눅스 시스템에서 실행시키면, 아래와 같은 결과를 얻는다:
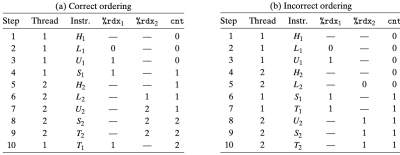
Figure 2. Instruction orderings for the first loop iteration in badcnt.c.Ti: 루프의 뒷부분에 해당하는 명령어 블록
루프의 앞부분과 뒷부분은 오직 각 쓰레드의 스택에 저장된 변수만을 다루는 반면, Li, Ui, Si는 공유 카운터 변수(cnt)를 다룬다. badcnt.c의 두 피어 쓰레드가 단일 프로세서(uniprocessor)에서 동시에(concurrently) 실행될 때, 쓰레드의 어셈블리 명령어들은 어떤 순서로든 하나씩 완료된다. 따라서, 각각의 동시 실행(concurrent execution)은 두 쓰레드의 명령어들에 대한 임의의 실행 순서 를 정의하게 된다. 이렇게 실행되고 정의된 명령어들의 순서들 중 일부는 올바른 결과를 도출하지만, 다른 순서들은 그렇지 않다. 이때 핵심은 OS가 여러 피어 쓰레드의 명령어의 실행 순서를 예측하는 방법은 없다는 것이다.
예를 들어, figure 2(a)는 올바른 명령어 순서를 단계별로 보여준다. 각 쓰레드가 공유 변수 cnt를 업데이트한 후 메모리에 있는 cnt의 값은 2이며, 이는 기대한 결과이다. 반면, figure 2(b)에 나타난 명령어 실행 순서는 cnt에 대해 의도되지 않은 결과를 만든다. 이는 2번 쓰레드가 step5에서 cnt를 불러오는데, 이는 1번 쓰레드가 step2에서 cnt를 불러오고, 이를 step6에서 수정한 값을 저장한 사이에 있기 때문이다. 그 결과, cnt에는 두번의 갱신 작업이 수행되었지만, 여전히 값은 1이다.
Progress Graphs
Figure 3. Progress graph example
진행 그래프(Process graph)는 n개의 동시 실행되는 쓰레드의 실행을 n차원의 데카르트 공간(Cartesian space) 상의 trajectory으로 모델링한 것이다. 이때 각 축 k는 쓰레드 k의 진행 상황을 나타낸다. 또한 각 좌표 (I1, I2, ..., In)은 쓰레드 k(k = 1, ..., n)가 명령어 Ik을 완료한 상태를 나타낸다. 따라서 그래프의 원점은 어떠한 명령어도 완료되지 않았다는 것을 의미한다. Figure 3는 badcnt.c 프로그램의 루프 첫 번째 반복에 대한 2차원 진행 그래프를 보여준다. 이때 수평 축은 쓰레드 1에 해당하고, 수직 축은 쓰레드 2에 해당한다. Figure 3의 좌표 (L1, S2)는 쓰레드 1이 L1을 완료하고 쓰레드 2가 S2를 완료한 상태를 나타낸다.
Figure 4. An example trajectory
진행 그래프는 명령어 실행을 완료한 상태에서 다음 상태로의 전이로 모델링한다. 전이는 한 점에서 인접한 점으로 향하는 방향이 있는 간선(directed edge)으로 표현된다. 유효한 전이는 오른쪽(쓰레드 1의 명령어가 완료됨) 또는 위쪽(쓰레드 2의 명령어가 완료됨) 으로 이동하는 것이다. 이때 두 명령어가 동시에 완료될 수는 없으므로, 대각선 방향 전이(diagonal transition)는 허용되지 않는다. 또한 프로그램은 거꾸로 동작하지 않으므로, 왼쪽이나 아래로 이동하는 전이도 허용되지 않는다. 프로그램의 실행 이력은 상태 공간을 통과하는 trajectory(궤적)로 모델링된다. 예를 들어, figure 4는 아래와 같이 실행된 명렬어 순서에 대한 trajectory를 보여준다:
H1, L1, U1, H2, L2, S1, T1, U2, S2, T2
Figure 5. Safe and unsafe trajectories
이때 쓰레드 i에 대해, 공유 변수 cnt의 내용을 조작하는 명령들인 (Li, Ui, Si)는 (공유 변수 cnt에 관해서) 임계 구역을 구성하며, 이는 다른 스레드의 임계 구역과 교차되어 실행(interleaved)되어서는 안 된다. 즉, Li, Ui, Si 명령어들이 수행되고 있다는 것은 쓰레드 i 내에서 어떤 공유 변수를 로드하고 수정하여, 그 결과를 저장하는 작업이 진행되고 있으므로 race condition을 막기 위해서 다른 쓰레드가 Li, Ui, Si을 통해 해당 공유 변수에 접근하면 안된다는 것이다. figure 5는 변수 cnt에 대한 비안전 영역(unsafe area)를 보여준다. 이때, 비안전 영역은 그 둘레가 모서리에 인접하지만, 이를 포함하지는 않는다. 예를 들어, 상태 (H1, H2)와 (S1, U2)는 비안전 영역에 인접하지만, 그 일부는 아니다. 비안전 영역을 피해가는 경로는 안전 경로(safe trajectory) 라고 한다. 반대로, 비안전 영역의 어느 부분이라도 통과하는 경로는 비안전 경로(unsafe trajectory)라고 한다. 이 역시 figure 5에 표시되어 있다.
모든 안전 경로는 공유 변수를 올바르게 갱신한다. 따라서 전역 데이터 구조를 공유하는 어떤 동시성 프로그램(concurrent program)의 실행이 올바르도록 보장하려면, 해당 프로그램의 실행에 사용되는 스레드들이 항상 안전 경로를 따라 작동하도록 보장해야 하며, 이는 동기화(synchronization)을 통해 구현된다. 이에 대한 고전적인 접근 방식은 세마포어(semaphore) 라는 개념을 기반한다.
세마포어의 개념은 프리스레딩(prethreading)이라는 기법에 적용될 수 있으며, 이 기법은 아래와 같이 구현된 concurrent 서버 코드를 통해 알아볼 수 있다:
#include"csapp.h"#include"sbuf.h"#define NTHREADS 4#define SBUFSIZE 16voidecho_cnt(intconnfd);void*thread(void*vargp);sbuf_tsbuf;//connfd를 저장하는 버퍼이며, 내부적으로 세마포어 사용intmain(intargc,char**argv){inti,listenfd,connfd;socklen_tclientlen;structsockaddr_storageclientaddr;pthread_ttid;if(argc!=2){fprintf(stderr,"usage: %s <port>\n",argv[0]);exit(0);}listenfd=Open_listenfd(argv[1]);//Open_listenfd()는 서버 소켓을 열고, listen()까지 진행sbuf_init(&sbuf,SBUFSIZE);//sbuf를 초기화하고, listenfd만을 등록for(i=0;i<NTHREADS;i++)//NTHREADS만큼 스레드 생성해서 thread() 함수 실행.Pthread_create(&tid,NULL,thread,NULL);while(1){clientlen=sizeof(structsockaddr_storage);//클라이언트 요청이 오면 Accept()로 연결을 수락.connfd=Accept(listenfd,(SA*)&clientaddr,&clientlen);//수락한 결과 얻은 connfd를 sbuf에 등록하기 -> 나중에 스레드에서 처리sbuf_insert(&sbuf,connfd);}}void*thread(void*vargp){Pthread_detach(pthread_self());//스레드 종료 시 리소스를 자동 회수while(1){intconnfd=sbuf_remove(&sbuf);//sbuf에서 connfd를 소비(provider-consumer)echo_cnt(connfd);//connfd를 통해 클라이언트의 요청을 처리Close(connfd);//연결이 종료되면 connfd를 닫기}}
위 코드에서 concurrent 서버는 새로운 클라이언트가 접속할 때마다 새로운 스레드를 생성한다. Concurrent Server 문서에 다룬 스레드 기반의 서버의 단점은 클라이언트마다 새 스레드를 만드는데 적지 않은 비용이 발생한다는 것이다. 하지만 위에서 제시된 prethreading 방식을 이용한 서버는 이러한 문제를 해결하기 위해서 figure 6에 제시된 생산자-소비자(Producer-Consumer) 모델을 사용하여 이러한 오버헤드를 줄이고자 한다. 이를 위해 이러한 서버는 메인 스레드(main thread)와 작업 스레드(worker thread)로 구성된다. 메인 스레드는 반복적으로 클라이언트로부터의 연결 요청을 수락하고, 그로부터 생성된 connfd를 버퍼(sbuf)에 저장한다. 각 작업 스레드는 반복적으로 버퍼에서 디스크립터를 꺼내어서 클라이언트 서비스를 수행한 다음, 다음 connfd를 기다린다. 이는 위 코드에서 제시되었듯이, 아래와 같은 control flow를 가진다:
메인 스레드의 경우
버퍼 sbuf를 초기화 한 후, 작업 스레드 집합을 생성한다.
무한 루프에서 클라이언트로부터의 연결 요청을 수락하고, 생성된 connfd를 sbuf에 등록한다.
각 작업 스레드의 경우
버퍼에서 connfd를 꺼낼 수 있을 때까지 기다린다.
echo_cnt() 함수를 호출하여 클라이언트의 입력을 echo한다.
아래는 echo_cnt() 함수를 구현한 코드이다:
#include"csapp.h"staticintbyte_cnt;//서버가 지금까지 읽은 모든 바이트의 누적 합.staticsem_tmutex;//byte_cnt를 여러 스레드가 동시에 접근하지 못하게 하는 세마포어staticvoidinit_echo_cnt(void)//서버 실행 중 단 한 번만 호출되도록 보장된다.{Sem_init(&mutex,0,1);//세마포어 mutex를 1로 초기화하여 사용한다.byte_cnt=0;}//클라이언트 소켓(connfd)을 통해 라인 단위로 문자열을 echo한다. 동시에 총 수신 바이트 수(byte_cnt)를 세고 출력한다.voidecho_cnt(intconnfd){intn;charbuf[MAXLINE];rio_trio;//init_echo_cnt()를 스레드 환경에서 한 번만 호출하도록 보장하는 구문staticpthread_once_tonce=PTHREAD_ONCE_INITPthread_once(&once,init_echo_cnt);Rio_readinitb(&rio,connfd);//connfd를 통한 연결을 위해서 rio 버퍼를 초기화한다.while((n=Rio_readlineb(&rio,buf,MAXLINE))!=0){//클라이언트가 데이터를 보내는 동안 계속 읽음P(&mutex);//mutex 세마포어를 통해서 byte_cnt를 보호byte_cnt+=n;//n은 이번에 읽은 바이트 수, 이를 byte_cnt에 추가printf("server received %d (%d total) bytes on fd %d\n",n,byte_cnt,connfd);V(&mutex);//보호 해제Rio_writen(connfd,buf,n);//이번 루프에서 읽어 들인 문자열을 출력}}
위에서 다룬 echo_cnt() 함수는 echo() 함수의 변형으로, 모든 클라이언트로부터 수신된 누적 바이트 수를 byte_cnt라는 전역 변수에 저장한다. 이 경우, 해당 함수를 구현하기 위해서는 byte_cnt 카운터(counter) 변수와 mutex 세마포어를 초기화하여야 한다. 하나의 접근 방식은 메인 스레드가 명시적으로 초기화 함수를 호출하는 것이다. 다른 접근 방식은 해당 코드에서의 구현과 같이 pthread_once() 함수를 사용하여, 어떤 스레드가 처음으로 echo_cnt() 함수를 호출할 때 초기화 함수가 호출되도록 하는 것이다.
Using Threads for Parallelism
요즘 나오는 컴퓨터들은 figure 6와 같은 멀티코어 프로세서를 가지고 있으며, 이는 concurrent programming을 더욱 빠르게 실행한다. 이는 OS 커널이 스레드들을 단일 코어에서 순차적으로 실행하는 대신, 멀티코어에서 병렬적으로 스케쥴링하여 처리하기 때문이다. 이러한 병렬성(parallelism)을 활용하는 것은 매우 중요하다. Figure 7는 sequential 프로그램, concurrent 프로그램, parallel 프로그램 사이의 집합 관계로 나눌 수 있다. 모든 프로그램은 sequential 프로그램과 concurrent 프로그램이라는 서로소 집합으로 나눌 수 있다. 이때 parallel 프로그램은 concurrent 프로그램의 진부분집합이다. 아래는 parallel 프로그램의 간단한 예시이다.
#include"csapp.h"#define MAXTHREADS 32void*sum_mutex(void*vargp);//각 스레드가 실행할 함수의 프로토타임longgsum=0;// 모든 스레드가 각자 구한 부분합을 저장할 전역변수longnelems_per_thread;// 각 스레드가 처리할 원소의 개수sem_tmutex;// gsum에 대한 race condition을 막기 위한 세마포어intmain(intargc,char**argv){longi,nelems,log_nelems,nthreads,myid[MAXTHREADS];pthread_ttid[MAXTHREADS];/* Get input arguments */if(argc!=3){printf("Usage: %s <nthreads> <log_nelems>\n",argv[0]);exit(0);}nthreads=atoi(argv[1]);// nelems는 스레드의 개수log_nelems=atoi(argv[2]);// 실제로 처리할 원소 수의 2의 로그 값nelems=(1L<<log_nelems);// 2^log_nelems을 통해 실제로 처리할 원소의 수 계산nelems_per_thread=nelems/nthreads;sem_init(&mutex,0,1);//세마포어를 1로 초기화/* Create peer threads and wait for them to finish */for(i=0;i<nthreads;i++){myid[i]=i;// 각 스레드에게 부여되는 고유 인덱스Pthread_create(&tid[i],NULL,sum_mutex,&myid[i]);// 스레드를 생성}for(i=0;i<nthreads;i++)Pthread_join(tid[i],NULL);//모든 스레드가 작업을 마칠 때까지 기다림 (동기화)/* Check final answer */if(gsum!=(nelems*(nelems-1))/2)//오류 발생했는지 확인하기printf("Error: result=%ld\n",gsum);exit(0);}/* Thread routine for psum-mutex.c */void*sum_mutex(void*vargp){longmyid=*((long*)vargp);//인자로 전달된 id 추출//예를 들어, myid = 0: [0, 256), myid = 1: [256, 512)longstart=myid*nelems_per_thread;/* Start element index */longend=start+nelems_per_thread;/* End element index */longi;for(i=start;i<end;i++){P(&mutex);gsum+=i;//gsum에 mutex를 이용하여 start ~ end까지의 수를 모두 덧셈V(&mutex);}returnNULL;}
예를 들어 정수 0부터 n-1까지의 합을 병렬로 계산하는 상황을 생각하자. 가장 단순한 해결책은 스레드들이 mutex로 보호되는 공유 전역 변수에 합을 더하도록 하는 것이다. 이때 단순화를 위해 t개의 서로 다른 스레드들이 존재한다고 가정할 때, 0 ~ n까지의 각 구간은 n/t개의 원소를 가진다. 따라서 이를 구현하기 위해서는 sum_mutex를 통해서 스레드를 호출할 때 myid를 통해서 스레드에게 주어진 각 구간의 합을 공유 전역 변수에 더하도록 하면 된다. 이렇게 구현된 프로그램은 싱글 스레드로 실행할 때에도 매우 느릴 뿐 아니라, 여러 스레드로 병렬 실행할 경우 오히려 더욱 느려진다는 놀라운 결과를 보여준다. 사실 이는 당연한 결과이기도 하다. 왜냐하면 하나의 프로세스 내의 반복문 내에서 실행될 수 있었던 프로그램을, 더 많은 스레드를
각주
↑인스턴스는 메모리 상의 복사본을 의미하며, 인스턴스를 참조한다는 것은 해당 메모리 주소를 참조한다는 것을 의미한다.