Indexing
상위 문서: 데이터베이스 시스템
개요
많은 쿼리는 파일 내에 있는 레코드(records)들의 일부분만을 참조한다. 예를 들어, “Physics 학과의 모든 강사를 찾아라”와 같은 쿼리는 instructor 또는 student 레코드의 일부만을 참조한다. 따라서 시스템이 instructor 릴레이션의 모든 튜플을 읽으면서 dept_name 값이 “Physics”인지 확인하는 것은 비효율적이다. 이상적으로는, 시스템이 이러한 레코드들을 직접 찾아낼 수 있어야 하며, 이를 구현하기 위해 인덱싱(Indexing)이라는 개념이 사용된다.
데이터베이스 시스템에서 파일에 대한 인덱싱은 어떤 youngwiki의 분류 문서와 거의 비슷한 방식으로 작동한다. 예를 들어 youngwiki에서 특정 주제에 대해 알고 싶다면,[1] 분류 문서에 접근하여 해당 주제가 나타나는 문서를 찾고, 해당 문서를 읽어서 원하는 정보를 얻을 수 있다. 분류 문서에 나열된 단어들은 정렬된 순서로 되어 있어서 원하는 단어를 쉽게 찾을 수 있으며, 그 문서 크기가 작아 수고를 줄인다. 인덱싱도 이러한 원리를 사용한다. 예를 들어, 어떤 student 릴레이션 내에 존재하는 튜플에 대한 레코드를 특정 ID로 검색하려면, 인덱싱을 참조하여 해당 레코드가 있는 디스크 블록을 찾고, 그 디스크 블록을 가져와서 원하는 레코드를 얻을 수 있다.

Figure 1은 인덱스를 저장하는 파일인 인덱스 파일(index file) 내에 존재하는 인덱스 항목(index entry)이 어떻게 구성되는지 보여준다. 검색값(search key) 어떤 파일에서 레코드를 검색하는 데 사용되는 속성 또는 속성들의 집합이다. 쉽게 말해서, 검색하는 값이 속하는 속성 또는 그 집합이다. 포인터(pointer)는 해당 값을 가지는 레코드가 원본 테이블에서 어디 있는지를 가리키는 포인터이다.
인덱싱의 기본적인 유형에는 아래의 두 가지가 있다:
- 정렬 색인(Ordered indices): 검색키들을 정렬된 순서로 저장한다.
- 해시 색인(Hash indices): 검색키들을 해시 함수(hash function)를 사용하여 bucket에 균등하게 분배한다.
Index Evaluation Standards
해당 문서에서는 여러 가지 인덱싱 기법들을 다루며, 각기 다른 장단점을 가진다. 이때 아래는 각 인덱싱 기법들을 평가하기 위해서 사용되는 평가 기준들이다:
- 접근 유형(Access types): 어떤 유형의 접근을 효율적으로 지원하는가?
- 예를 들어, 특정 속성 값에 해당하는 레코드를 찾는 경우
- 예를 들어, 속성 값이 특정 범위에 해당하는 레코드를 찾는 경우
- 접근 시간(Access time): 특정 데이터 항목이나 항목 집합을 찾는 데 걸리는 시간
- 삽입 시간(Insertion time): 새로운 데이터를 삽입하는 데 걸리는 시간
- (삽입할 위치를 찾는 데 걸리는 시간) + (인덱싱을 갱신하는 데 걸리는 시간)
- 삭제 시간(Deletion time): 새로운 데이터를 삭제하는 데 걸리는 시간
- (삭제할 항목을 찾는 데 걸리는 시간) + (인덱싱을 갱신하는 데 걸리는 시간)
- 공간 오버헤드(Space overhead): 색인 구조가 차지하는 추가적인 공간
인덱싱은 데이터베이스에서 질의를 효율적으로 처리하기 위해 매우 중요하다. 인덱싱이 없다면, 모든 쿼리는 쿼리에서 사용하는 모든 릴레이션의 전체 내용을 읽게 되며, 단 몇 개의 레코드만을 가져오는 쿼리에 대해서도 필요한 것보다 많은 비용이 소모된다.
Ordered Indices
파일 내 레코드에 빠르게 임의 접근(random access)하기 위해, 우리는 인덱스 구조(index structure)를 사용할 수 있다. 각 인덱싱 구조는 특정한 검색키에 연관되어 있다. 정렬 인덱스(ordered indices)들은 검색키들의 값을 정렬된 순서로 저장하며, 각 검색키와 그것을 포함하는 레코드들을 연결시킨다. 이때 인덱싱이 적용된 파일 내의 레코드들 자체도 어떤 정렬 순서로 저장될 수 있으며, 하나의 파일은 서로 다른 검색키들에 대해 여러 개의 인덱스를 가질 수 있다.

파일이 검색키에 따라 순차적으로 정렬되어 있다고 가정하자. 클러스터링 인덱스(clustering index)는 해당 검색키를 기준으로 실제 레코드들이 디스크에 정렬되어 저장된 경우, 해당 검색키에 대해 만들어진 인덱스를 의미한다. 즉, 인덱스가 참조하는 검색 키의 순서와 파일 내 레코드의 저장 순서가 일치하는 경우이다. 이는 기본 인덱스(primary index)라고도 불리며, 보통 기본키(primary key)에 대한 인덱스로 사용된다. 이와 다르게, 파일의 순차적인 정렬 순서와 다른 순서를 지정하는 인덱스를 세컨더리 인덱스(secondary index) 또는 비클러스터링 인덱스(nonclustering index)라고 한다. Figure 2는 instructor 레코드의 순차 파일(sequential file)을 보여준다. 해당 예제에서 레코드들은 ID를 기준으로 정렬된 순서로 저장되어 있으며, ID 속성이 검색 키로 사용된다.
Dense and Sparse Indices
하나의 인덱스 항목(index entry) 또는 인덱스 레코드(index record)는 figure 1과 같이 검색키 값과, 그 값을 검색키 값으로 가지는 하나 이상의 레코드에 대한 포인터들로 구성된다. 레코드에 대한 포인터는 디스크 블록에 대한 식별자(identifier)와 해당 블록 내에서 레코드를 식별할 수 있는 오프셋(offset)으로 구성된다. 이때 정렬 인덱스의 유형은 크게 두가지로 구분된다:
- 조밀 인덱스(Dense index): 파일 내의 모든 검색 키 값에 대해 인덱스 항목이 존재한다.
- 조밀 클러스터링 인덱스에서는 인덱스 레코드가 검색키 값을 포함하고 있으며, 해당 검색키 값을 가지는 첫 번째 데이터 레코드에 대한 포인터를 포함한다. 같은 검색 키 값을 가지는 나머지 레코드들은 같은 검색 키에 따라 정렬되어 있기 때문에[2] 첫 번째 레코드 이후로 순차적으로 저장되어 있다.
- 조밀 비클러스터링 인덱스는 같은 검색 키 값을 가지는 모든 레코드에 대한 포인터 목록을 저장한다.
- 희소 인덱스(Sparse index): 인덱스 항목이 검색키의 일부 값에 대해서만 존재한다.
- 희소 인덱스는 릴레이션이 검색키 값 기준으로 정렬되어 있을 때만, 즉 해당 인덱스가 클러스터링 인덱스일 때만 사용할 수 있다.
- 레코드를 찾기 위해서는, 찾고자 하는 검색 키 값보다 작거나 같은 값 중에서 가장 큰 검색 키 값을 가진 인덱스 항목을 찾는다. 그런 다음, 그 인덱스 항목이 가리키는 레코드에서 시작해서, 파일 내에서 포인터를 따라가며 원하는 레코드를 찾을 때까지 순차적으로 읽는다.
-
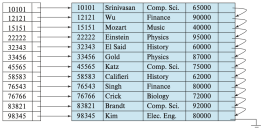 Figure 3. Dense index
Figure 3. Dense index -
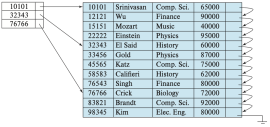 Figure 4. Sparse index
Figure 4. Sparse index -
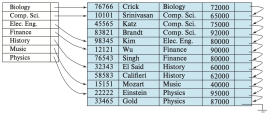 Figure 5. Dense index with dept_name
Figure 5. Dense index with dept_name



Figure 3와 Figure 4는 각각 instructor 파일에 대한 조밀 인덱스와 희소 인덱스를 보여준다. 예를 들어, ID가 “22222”인 instructor의 레코드를 찾고자 한다고 하자. Figure 3의 조밀 인덱스를 사용하는 경우, 해당 레코드로 바로 연결되는 포인터를 따라가서 원하는 레코드를 직접 찾을 수 있다. Figure 4의 희소 인덱스를 사용하는 경우에는 “22222”에 대한 인덱스 항목은 존재하지 않는다. 이 경우, “22222”보다 작은 인덱스 항목 중 가장 마지막 값인 “10101”을 찾고, 그 포인터를 따라간다. 그런 다음 instructor 파일을 순차적으로 읽으면서 원하는 레코드를 찾는다.
또 다른 예시로, 검색 키 값이 기본키가 아니라고 가정하자. Figure 5는 검색 키가 name인 instructor 파일에 대한 조밀 클러스터링 인덱스를 보여준다. 이 경우 instructor 파일은 ID가 아닌 dept_name을 기준으로 정렬되어 있으므로, dept_name에 대한 인덱스는 클러스터링 인덱스가 된다. History 학과에 해당하는 레코드를 찾는다고 가정하면, 포인터를 따라가 첫 번째 History 레코드를 직접 찾는다. 해당 레코드를 처리하고, 그 레코드에 있는 포인터를 따라가서 History가 아닌 다른 학과 레코드가 나타날 때까지 다음 레코드를 찾는다.
위와 같이, 일반적으로 조밀 인덱스가 있을 때가 희소 인덱스보다 레코드를 더 빠르게 찾을 수 있다. 그러나 희소 인덱스는 더 적은 공간을 사용하거나, 삽입 및 삭제 시 유지 관리 비용이 더 적다는 장점이 있다. 따라서 접근 시간(access time)과 공간 오버헤드(space overhead) 사이에서 시스템 설계자가 균형(trade-off)을 선택해야 한다.
Multilevel Indices
어떤 릴레이션에 대해 1,000,000개의 튜플이 있을 때, 조밀 인덱스를 구축한다고 가정하자. 이때 4킬로바이트 블록 하나에 100개의 인덱스 항목이 들어간다고 하면, 인덱스는 10,000개의 블록을 차지한다. 만약 이러한 방식으로 구축된 인덱스가 충분히 작아서 메인 메모리에 전부 보관 가능하다면, 항목을 찾는 데 걸리는 검색 시간은 짧다. 하지만 인덱스가 너무 커서 전부 메모리에 올릴 수 없다면, 인덱스 블록은 필요할 때마다 디스크에서 불러와야 한다. 이 경우, 인덱스 항목 하나를 찾기 위해 여러 디스크 블록을 읽는 작업이 필요하다. 즉, 큰 인덱스를 검색하는 것은 상당한 비용이 든다.

이 문제를 해결하기 위해서 내부 인덱스(inner index)를 정의하여 일반적인 순차 파일처럼 다루고, 그 위에 희소 외부 인덱스(sparse outer index)를 구성한다. 이는 figure 6에 잘 나타나 있다. 레코드를 찾기 위해서는 먼저, 외부 인덱스에서 이진 탐색(binary search)을 수행하여 원하는 검색키 값에 대해서 작거나 같은 값 중 가장 큰 검색키 값을 가진 항목을 찾는다. 이 항목에 대한 포인터는 내부 인덱스의 어떤 블록을 가리킨다. 그리고 이 블록을 스캔하여, 원하는 검색 키 값보다 작거나 같은 가장 큰 값을 가진 인덱스 항목을 찾는다. 해당 항목의 포인터는 찾고자한 실제 레코드가 저장된 파일 블록을 가리킨다. 이는 아래 표에 잘 정리되어 있다:
| 단계 | 대상 | 수행 작업 | 결과 |
|---|---|---|---|
| 1단계 | 외부 인덱스 | <=22222 중 최대값 찾기
|
내부 인덱스 블록에 접근 가능하게 됨 |
| 2단계 | 내부 인덱스 | <=22222 중 최대값 찾기
|
실제 레코드 블록에 접근 가능하게 됨 |
| 3단계 | 데이터 파일 | 해당 블록에서 레코드 직접 검색 | 원하는 튜플 도달 |
파일이 매우 커서 외부 인덱스 조차 메모리에 들어가지 못할 정도가 되며, 외부 인덱스 위에 또 다른 인덱스를 구성할 수 있으며, 이를 필요한 만큼 반복할 수 있다. 이와 같이 두 단계 이상의 계층 구조를 가진 인덱스를 다단계 인덱스(multilevel index)라고 부른다.
Index Update
자세한 내용은 Index Update 문서를 참조하십시오.
Secondary Indices
세컨더리 인덱스(Secondary Indices)는 반드시 조밀해야 하며, 파일 내의 모든 검색키 값에 대해 인덱스 항목이 존재해야 하고, 파일 내의 모든 레코드에 대한 포인터를 가져야 한다. 이는 파일의 일부에 순차적으로 접근하여 특정 검색 키 값을 가진 레코드들을 찾아낼 수 있는 클러스터링 인덱스과는 달리, 세컨더리 인덱스는 레코드가 일반적으로 파일 내에 임의의 위치에 존재하여 파일 전체를 검색해야 찾을 수 있기 때문이다.

후보키(Candidate key)에 대한 세컨더리 인덱스는 조밀 클러스터링 인덱스와 그 형태가 같지만, 인덱스에서 연속적인 키 값을 가리키는 레코드들이 파일 내에 순차적으로 저장되어 있지 않다는 점만 다르다. 만약 하나의 릴레이션이 같은 검색키 값을 가지는 레코드를 둘 이상 가질 수 있다면, 그 검색키는 비고유(nonunique) 검색키라고 한다. 비고유 검색 키에 대한 세컨더리 인덱스를 구현하는 한 가지 방법은 다음과 같다:
클러스터링 인덱스의 경우와는 달리, 세컨더리 인덱스의 포인터들은 레코드를 직접 가리키지 않는다. 대신 인덱스 내의 각 포인터는 "버킷(bucket)"을 가리키며, 이 버킷은 다시 파일 내 레코드들을 가리키는 포인터들을 포함한다. Figure 7은 instructor 릴레이션의 dept_name을 검색 키로 사용할 때, 이러한 간접 참조(indirection)를 이용하는 세컨더리 인덱스 구조를 보여준다.
하지만 이 방식에는 몇 가지 단점이 존재한다. 먼저 간접 참조가 추가되기 때문에, 인덱스 접근이 느려진다. 또한 어떤 검색 키 값에 중복이 거의 없거나 아예 없을 경우, 버킷 하나에 전체 블록이 할당되면 공간이 낭비된다.
아래는 클러스터링 인덱스와 세컨더리 인덱스 사이의 차이점을 보여주는 표이다:
| 항목 | Clustering Index | Secondary Index |
|---|---|---|
| 정의 | 데이터 파일이 인덱스 키 순으로 정렬됨 | 데이터 파일이 정렬 순서와 무관하게 배치됨 |
| 성능 | 순차 접근 및 범위 질의에 효율적 | 랜덤 접근[3] 많아 느림 (특히 디스크 I/O 많음) |
| 구조 | 하나의 인덱스 엔트리가 하나의 레코드 포인터 | 하나의 인덱스 엔트리가 다수 포인터를 포함하는 버킷 |
Indices on Multiple Keys
일반적으로 검색키는 둘 이상의 속성을 가질 수 있으며, 둘 이상의 속성을 포함하는 검색 키를 복합 검색 키(composite search key)라고 한다. 인덱스의 구조는 다른 인덱스와 동일하며, 유일한 차이점은 검색키가 하나의 속성이 아니라 속성들의 리스트라는 것이다. 검색 키는 (a₁, ..., aₙ) 형태를 가지는 값들의 튜플(tuple)로 표현될 수 있으며, 여기서 인덱싱된 속성들은 A₁, ..., Aₙ이다.
검색 키 값의 순서는 사전식 순서(lexicographic ordering)에 따른다. 예를 들어, 두 개의 속성으로 이루어진 검색 키의 경우, (a₁, a₂) < (b₁, b₂) 이려면 다음 조건 중 하나가 참이어야 한다:
- a₁ < b₁ 이거나,
- a₁ = b₁ 이면서 a₂ < b₂
즉, 사전식 순서는 말그대로 튜플의 각 원소를 하나의 글자로 볼때, 튜플이라는 단어가 사전에 정렬되는 순서와 동일하다. 예를 들어:
- (John, 12121) < (John, 13514)
- (John, 13514) < (Peter, 11223)