Three Kinds of Cache Mapping: 두 판 사이의 차이
| 77번째 줄: | 77번째 줄: | ||
또한 LFU(Least Frequently Used)라는 replacement policy도 존재하며, 이는 가장 적게 사용되지 않은 캐시 라인을 교체하는 방식이다. | 또한 LFU(Least Frequently Used)라는 replacement policy도 존재하며, 이는 가장 적게 사용되지 않은 캐시 라인을 교체하는 방식이다. | ||
==Cache Performance== | |||
==각주== | ==각주== | ||
[[분류:컴퓨터 시스템]] | [[분류:컴퓨터 시스템]] | ||
2025년 6월 7일 (토) 05:04 판
개요
- Figure 1. Cache category
-
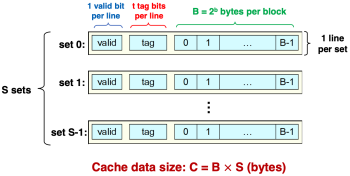 Figure 1.(a) Direct-Mapped Cache
Figure 1.(a) Direct-Mapped Cache -
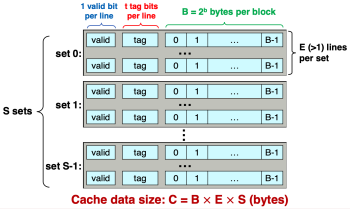 Figure 1 (b). Set-Associative Cache
Figure 1 (b). Set-Associative Cache -
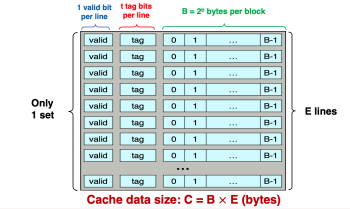 Figure 1 (c). Fully Associative Cache
Figure 1 (c). Fully Associative Cache



캐시(Cache)는 크게 Direct-mapped 캐시, Set-associatice 캐시, Fully associative 캐시로 구분된다. 이는 각각 Figure 1(a), (b), (c)와 같은 형태이다. Direct-mapped 캐시는 E = 1인 캐시이며, 각 set에 대해 하나의 라인이 할당된다. Set-associatice 캐시는 E>1, S > 1인 캐시이며, 여러 set가 존재할 수 있고 하나의 set에 여러 라인이 할당될 수 있다. Fully associative 캐시는 S = 1인 캐시이며, 하나의 set에 모든 라인이 할당된다.
Analyzing cache hit and cache miss


캐시 히트(hit)와 미스(miss)를 분석하기 위해, Direct-mapped 캐시와 접근할 주소가 주어졌다고 가정하자:
먼저 캐시 내에 해당 주소가 가리키는 데이터가 있는지 확인하기 위해서는 set index bit를 사용해야 한다. Figure 2는 set index = 0b00001이므로, set 1에 접근하여 캐시 블록을 탐색하는 것을 보여준다. 이때 주의해야 할 것은 다수의 메모리 블록이 여러 set 내에 존재할 수 있다는 것이다. 하지만 해당 케이스는 E = 1이고, 하나의 캐시 라인(캐시 블록)에는 하나의 메모리 블록을 저장하므로 해당 예시에는 하나의 set에는 하나의 메모리 블록이 저장된다.

Set index를 통해 탐색해야 할 set가 선택된 이후에는 valid bit = 1인지와, tag bits가 주어진 주소의 tag bits와 일치하는지 체크한다. 만약 두 조건이 모두 만족된다면, 캐시 히트에 해당한다. 캐시 히트라면, 마지막으로 block offset을 사용하여 접근하고자 하는 데이터의 위치를 특정한다. 이는 figure 3에 잘 나타나 있다. 만약 두 조건 중 하나 이상이 맞지 않는다면 이는 캐시 미스에 해당한다. 이 경우 해당 set와 캐시 블록에 주어진 주소가 가리키는 메모리 블록으로 덮어 쓴다. 또한 valid bit = 1로 설정하고, tag bits는 주어진 주소의 tag bits로 설정한다. 이러한 메커니즘은 figure 4에 잘 나타나 있다.
이때 중요한 것은 캐시 히트와 캐시 미스 사이에는 굉장히 큰 퍼포먼스 차이가 존재한다는 것이다. 캐시 미스가 발생하여 메인 메모리에 접근하는 경우는 캐시 히트의 경우보다 약 100배는 느리며, 따라서 캐시 히트의 확률을 높이는 것이 굉장히 중요하다. 이때 어떤 메모리 접근에 대해 캐시 히트가 발생할 확률을 hit rate라고 하고, 캐시 미스가 발생할 확률을 miss rate라고 한다. 이때 hit rate와 miss rate는 다음과 같이 계산된다:
Hit Rate = # of cache hits / # of total accesses
Miss Rate = # of cache misses / # of total accesses
= 1 - hit rate
Analyzing Cache Hit/Miss Exercise

Figure 5와 같은 상황이 주어졌을 때, 다음 네가지 질문에 답해보자.
- What are S, t, s and b?
- What is the cache hit rate of this code?
- If m is changed to 64, does cache hit rate change?
- If the size of array element is changed to 8, does cache hit rate change?
1. C = B x E x S = 212 = 24 x 1 x E이므로, S = 28 = 256이다. 이에 따라, b = log2B = 4, s = log2S = 8이다. 또한 m = t + s + b이므로 t = 20이다.
2. B = 16bytes이므로, set 1에는 a[0~3]이, set 2에는 a[4~7]이, ..., set 256에는 a[1020~1023]이 저장된다. 이 경우 a[0], a[4],...,a[1020]일 때에는 캐시 미스가 발생한다. 하지만 a[1~3], a[5~7],..., a[1021~1023]의 경우는 이미 캐시 미스로 인해 캐시에 데이터가 로드된 후 접근하므로 캐시 히트가 발생한다. 따라서 hit rate = 75%이다.
3. m = 64가 바뀌어도 바뀌는 것은 tag bits의 개수만 42로 바뀐다. 이때 t는 hit rate에 직접적인 연관이 있는 변수는 아니므로 hit rate를 바꿀 수 없다.
4. B = 16bytes이므로, set 1에는 a[0~1]이, set 2에는 a[2~3]이, ..., set 256에는 a[510~511]이 저장된다. 이에 따라 hit rate를 계산하면 50%이다.
Thrashing

Trashing에 대해 알아보기 위해, figure 6에 제시된 예제 상황에서의 hit rate를 구해보자. 이 경우 아래와 같이 각 객체의 주소를 분석할 수 있다.[1]
buf[0][0]: 0xAB0000 =... 1011 0000 0000 0000 0000 0000 buf[1][0]: 0xAB0400 =... 1011 0000 0000 0100 0000 0000 buf[2][0]: 0xAB0800 =... 1011 0000 0000 1000 0000 0000 ...
위를 관찰하면 알 수 있듯이, figure 6에 주어진 코드에서 접근하는 객체는 tag bits만 다를 뿐, 모두 캐시의 같은 set에 저장된다. 이 경우 주소를 이용한 모든 접근은 모두 캐시 미스에 해당하며, 이에 따라 hit rate = 0%이다. 이렇게 하나 이상의 스레드(또는 프로세서)나 제어 흐름(control flow)이 동일한 캐시 라인(또는 캐시 set)을 반복적으로 점유하면서, 캐시에 저장된 데이터가 무의미하게 계속 덮어쓰기 되는 현상을 thrashing이라고 한다. 이러한 trashing은 최대한 피하는 것이 좋으며, 이를 위해 다음과 같은 방식을 사용할 수 있다:
- 캐시 내의 set의 숫자(S)를 증가시킨다.
- 각 set안의 캐시 라인의 수(E)를 증가시킨다.
- 즉, Set-associatice 캐시나 Fully associative 캐시를 사용한다.
하지만 Direct-mapped 캐시가 단점만 있는 것은 아니다. 해당 캐시는 하나의 set에 단 하나의 캐시 라인만이 존재하므로 캐시에 접근하는 속도가 매우 빠르고 구조가 간단하다. 또한 캐시 미스가 발생하더라도 어떤 캐시 라인을 교체해야 할지가 정해져 있으므로, 캐시 미스에 대한 페널티(penalty)가 적다. 이를 바탕으로 Direct-mapped 캐시, Set-associative 캐시, Fully-associative 캐시의 차이를 비교하면 아래와 같다:
| Direct-mapped cache | Set-associative cache | Fully-associative cache |
|---|---|---|
| 구조가 간단함 | 중간 | 구조가 복잡함 |
| 캐시에 대한 접근이 빠름 | ... | 캐시에 대한 접근이 느림 |
| 캐시 미스에 대한 페널티가 적음 | ... | 캐시 미스에 대한 페널티가 많음 |
| Trashing이 자주 발생함 | ... | Trashing이 덜 발생함 |
| Hit rate가 작음 | ... | Hit rate가 적음 |
Replacement(Eviction) Policy

LRU (Least Recently Used) 기법은 가장 널리 사용되는 교체(replacement) 정책이다. 이 기법은 가장 오랫동안 사용되지 않은 캐시 라인을 교체하는 방식으로, 각 라인의 "나이(Age)"를 추적하여 가장 오래된 캐시 라인을 식별한다. 이 방식은 Figure 7에 나타나 있으며, 오른쪽에 각 캐시 라인의 나이를 나타내는 항목이 추가된 것을 볼 수 있다.
각 캐시 라인의 age는 해당 라인이 속한 set에 접근할 때마다 1씩 증가하고, 해당 라인이 갱신되거나 저장된 블록이 접근될 경우 0으로 초기화된다. 특정 set에서 캐시 미스가 발생하면, age가 가장 큰 (즉, 가장 오랫동안 사용되지 않은) 캐시 라인이 선택되어 새로운 블록으로 덮어써진다.
또한 LFU(Least Frequently Used)라는 replacement policy도 존재하며, 이는 가장 적게 사용되지 않은 캐시 라인을 교체하는 방식이다.
Cache Performance
각주
- ↑ 취소선은 tag bits, 밑줄은 block offset에 해당한다.