위 프로그램은 두 개의 쓰레드를 생성하며, 각 쓰레드는 이름의 전역 공유 카운터 변수인 cnt를 반복문의 반복 횟수 만큼 증가시킨다. 이때 각 쓰레드가 cnt를 niters 횟수만큼 증가시키기 때문에, 최종 값이 <code>2 * niters</code>인 것은 언뜻 명확해 보인다. 하지만 이를 리눅스 시스템에서 실행시키면, 아래와 같은 결과를 얻는다:
위 프로그램은 두 개의 쓰레드를 생성하며, 각 쓰레드는 이름의 전역 공유 카운터 변수인 cnt를 반복문의 반복 횟수 만큼 증가시킨다. 이때 각 쓰레드가 cnt를 niters 횟수만큼 증가시키기 때문에, 최종 값이 <code>2 * niters</code>인 것은 언뜻 명확해 보인다. 하지만 이를 리눅스 시스템에서 실행시키면, 아래와 같은 결과를 얻는다:
<syntaxhighlight lang="shell">
<syntaxhighlight lang="bash">
linux> ./badcnt 1000000
linux> ./badcnt 1000000
BOOM! cnt=1445085
BOOM! cnt=1445085
157번째 줄:
157번째 줄:
예를 들어, figure 2(a)는 올바른 명령어 순서를 단계별로 보여준다. 각 쓰레드가 공유 변수 cnt를 업데이트한 후 메모리에 있는 cnt의 값은 2이며, 이는 기대한 결과이다. 반면, figure 2(b)에 나타난 명령어 실행 순서는 cnt에 대해 의도되지 않은 결과를 만든다. 이는 2번 쓰레드가 step5에서 cnt를 불러오는데, 이는 1번 쓰레드가 step2에서 cnt를 불러오고, 이를 step6에서 수정한 값을 저장한 사이에 있기 때문이다. 그 결과, cnt에는 두번의 갱신 작업이 수행되었지만, 여전히 값은 1이다.
예를 들어, figure 2(a)는 올바른 명령어 순서를 단계별로 보여준다. 각 쓰레드가 공유 변수 cnt를 업데이트한 후 메모리에 있는 cnt의 값은 2이며, 이는 기대한 결과이다. 반면, figure 2(b)에 나타난 명령어 실행 순서는 cnt에 대해 의도되지 않은 결과를 만든다. 이는 2번 쓰레드가 step5에서 cnt를 불러오는데, 이는 1번 쓰레드가 step2에서 cnt를 불러오고, 이를 step6에서 수정한 값을 저장한 사이에 있기 때문이다. 그 결과, cnt에는 두번의 갱신 작업이 수행되었지만, 여전히 값은 1이다.
쓰레드의 장점 중 하나는 여러 쓰레드가 동일한 프로그램 변수를 쉽게 공유할 수 있다는 것이다. 이때 보통 단순히 “전역 변수는 공유되고, 스택 변수는 독립적이다”라고 말하지만, 현실은 그렇게 단순하지 않다. 먼저, 어떤 변수 x가 공유(shared)된다는 것은, 둘 이상의 쓰레드가 해당 변수의 인스턴스[1]를 참조한다는 뜻이다. 이때 어떤 C 프로그램 변수의 공유 여부를 이해하기 위해 다음과 같은 기본적인 질문들을 검토해야 한다:
쓰레드의 메모리 모델은 무엇인가?
해당 모델에 대해, 변수 인스터스는 메모리에 어떻게 매핑되는가?
이러한 인스턴스를 참조하는 쓰레드는 몇 개인가?
그리고 이에 대해 구체적으로 논의하기 위해서 아래와 같은 코드를 예제로서 사용한다:
#include"csapp.h"#define N 2void*thread(void*vargp);char**ptr;//전역 변수, 메인 쓰레드 내의 msg 배열에 접근할 수 있도록 설정됨intmain(){inti;pthread_ttid;char*msgs[N]={"Hello from foo","Hello from bar"};//문자열 배열 선언ptr=msgs;for(i=0;i<N;i++)//N(2) 개의 쓰레드를 만든다.Pthread_create(&tid,NULL,thread,(void*)i);//i를 포인터로 캐스팅하여 인자로 전달Pthread_exit(NULL);}void*thread(void*vargp){intmyid=(int)vargp;//쓰레드에 전달된 인자를 받음staticintcnt=0;//여러번 실행되도 한 번만 초기화됨printf("[%d]: %s (cnt=%d)\n",myid,ptr[myid],++cnt);//id에 따라 문자열 배열 출력, 총 쓰레드 실행 횟수 출력returnNULL;}
위 예제 프로그램은 하나의 메인 쓰레드가 두 개의 피어 쓰레드를 생성하는 구조이다. 메인 쓰레드는 각각의 동료 쓰레드에게 고유한 ID를 전달하며, 동료 쓰레드는 이 ID를 사용해 그에 대응되는 메시지와 함께 쓰레드 루틴이 호출된 총 횟수를 출력한다.
Threads Memory Model
동시에 실행되는 쓰레드 모음(pool)은 하나의 프로세스 컨텍스트(context)에서 실행된다. 각 쓰레드는 고유한 쓰레드 컨텍스트를 가지며, 이에는 TID, 스택, 스택 포인터, 프로그램 카운터, 조건 코드(Condition codes), 범용 레지스터(general-purpose register) 값들이 포함된다. 그리고 각 쓰레드는 다른 쓰레드들과 나머지 프로세스 컨텍스트를 공유한다. 공유되는 컨텍스트에는 Code/Data/Heap 메모리 공간, 공유 라이브러리, 열린 파일 디스크립터 등을 포함하는 전체 가상 주소 공간(virtual address space)이 포함된다.
이러한 관점에서 볼 때, 쓰레드는 다른 쓰레드의 레지스터 값을 읽거나 쓸 수는 없다. 하지만 어떤 쓰레드든 공유되어 있는 가상 메모리(virtual memory)의 위치에는 접근할 수 있으며, 만약 한 쓰레드가 해당 메모리 주소를 수정하면, 다른 모든 쓰레드는 해당 주소를 읽을 경우 변경 사항을 읽게 된다. 따라서 레지스터는 절대 공유되지 않지만, 가상 메모리는 항상 공유된다.
개별 쓰레드 스택에 대한 메모리 모델은 명확하지 않다. 이러한 스택은 가상 주소 공간의 스택 영역에 존재하며, "일반적으로" 각 쓰레드가 자신의 스택에만 접근한다. "일반적으로"라고 표현한 이유는 각각의 쓰레드 스택들이 다른 쓰레드들로부터 보호되지 않기 때문이다. 따라서 어떤 쓰레드가 다른 쓰레드의 스택에 대한 포인터를 얻는다면, 그 스택의 어느 부분이든 읽거나 쓸 수 있다. 예제 코드에서도 전역 변수 ptr을 통해 피어 쓰레드가 메인 쓰레드의 스택에 저장된 msg 문자열 배열을 참조하는 것이 나와 있다.
Mapping Variables to Memory
쓰레드 기반의 C 프로그램에서, 변수는 어떻게 저장되는지에 따라 아래와 같이 가상 메모리에 매핑된다:
1. 전역 변수(Global variables)
전역 변수는 함수 외부에서 선언된 모든 변수를 의미한다. 실행 시점에 가상 메모리의 읽기/쓰기(read/write) 영역은 각각의 전역 변수에 대해 정확히 하나의 인스턴스를 가진다. 이 인스턴스는 어떤 쓰레드에서든 참조 가능하다. 예제 코드에서 선언된 전역 변수 ptr은 가상 메모리의 읽기/쓰기 영역에 하나의 인스턴스를 가진다.
2. 자동 지역 변수(Local automatic variables)
자동 지역 변수는 static 속성 없이 함수 내부에 선언된 변수이다. 실행 시점에 각 쓰레드의 스택에는 해당 지역 변수의 인스턴스가 하나씩 존재한다. 이는 여러 쓰레드가 동일한 루틴을 실행하는 경우에도 마찬가지이다. 예를 들어, 지역 변수 tid는 메인 쓰레드의 스택에 하나의 인스턴스를 가지고 있으며, 이를 tid.m이라 표기한다. 다른 예시로는, 역 변수 myid는 두 개의 인스턴스를 가지며, 하나는 피어 쓰레드 0의 스택에, 다른 하나는 피어 쓰레드 1의 스택에 존재한다. 이를 각각 myid.p0, myid.p1이라 표기한다.
3. 정적 지역 변수(Local static variables)
static 속성으로 선언된 함수 내부 변수는 정적 지역 변수이다. 전역 변수와 마찬가지로, 가상 메모리의 읽기/쓰기 영역에 정확히 하나의 인스턴스를 가진다. 예제 프로그램에서 선언된 정적 변수 cnt는 여러 피어 쓰레드에 의해서 선언하더라도, 실제로는 한 번만 선언되며, 이는 가상 메모리의 읽기/쓰기 영역에 존재한다. 모든 피어 쓰레드는 이에 접근하여 cnt의 인스턴스를 읽고 쓴다.
Shared Variables
변수 v가 공유된(shared)다는 것은 변수 v의 인스턴스 중 하나 이상을 둘 이상의 쓰레드가 참조한다는 뜻이다. 예제 프로그램에서 변수 cnt는 런타임 인스턴스가 하나 뿐인데, 이를 두 개의 피어 쓰레드가 모두 참조하므로 공유된 변수이다. 반면, myid는 인스턴스가 두 개 있으며, 각각의 인스턴스는 한 쓰레드에 의해서만 참조되므로 공유되지 않는다. 이때, msgs와 같은 자동 지역 변수도 공유될 수 있다는 점을 주의해야 한다. 이를 바탕으로 ptr, cnt, i.m, msg.m, myid.p0, myid.p1의 공유 여부를 표로 나타내면 다음과 같다.
변수 인스턴스
메인 쓰레드에 의해 참조되는가?
쓰레드 p0에 의해 참조되는가?
쓰레드 p1에 의해 참조되는가?
공유되는가?
ptr
yes
yes
yes
yes
cnt
no
yes
yes
yes
i.m
yes
no
no
no
myid.p0
no
yes
no
no
myid.p1
no
no
yes
no
Synchronizing Threads
쓰레드의 큰 장점 중 하나는 쓰레드 간에 편리하게 변수를 공유할 수 있다는 것이다. 하지만 이는 때때로 심각한 동기화 오류를 초래하기도 한다. 이에 대해 설명하기 위해, 아래의 badcnt.c 프로그램을 참고하자:
/* WARNING: This code is buggy! */#include"csapp.h"void*thread(void*vargp);/* Thread routine prototype */volatilelongcnt=0;//counter로 사용되는 전역 변수intmain(intargc,char**argv){longniters;pthread_ttid1,tid2;/* Check input argument */if(argc!=2){printf("usage: %s <niters>\n",argv[0]);exit(0);}niters=atoi(argv[1]);//thread에 있는 루프의 반복 횟수//쓰레드 생성, niters의 주소를 넘겨서 각 쓰레드가 niters번 루프 돌도록 함Pthread_create(&tid1,NULL,thread,&niters);Pthread_create(&tid2,NULL,thread,&niters);//두 쓰레드가 모두 종료될 때까지 대기Pthread_join(tid1,NULL);Pthread_join(tid2,NULL);/* Check result */if(cnt!=(2*niters))printf("BOOM! cnt=%ld\n",cnt);//예측된 결과(cnt = 2 * niters)가 아님elseprintf("OK cnt=%ld\n",cnt);//예측된 결과(cnt = 2 * niters)가 맞음exit(0);}/* Thread routine */void*thread(void*vargp){longniters=*((long*)vargp);for(longi=0;i<niters;i++)cnt++;//인자로 받은 niters 만큼 cnt를 증가returnNULL;}
위 프로그램은 두 개의 쓰레드를 생성하며, 각 쓰레드는 이름의 전역 공유 카운터 변수인 cnt를 반복문의 반복 횟수 만큼 증가시킨다. 이때 각 쓰레드가 cnt를 niters 횟수만큼 증가시키기 때문에, 최종 값이 2 * niters인 것은 언뜻 명확해 보인다. 하지만 이를 리눅스 시스템에서 실행시키면, 아래와 같은 결과를 얻는다:
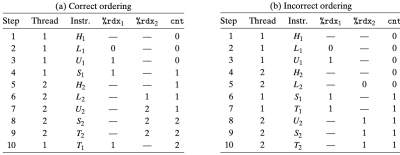
Figure 2. Instruction orderings for the first loop iteration in badcnt.c.Ti: 루프의 뒷부분에 해당하는 명령어 블록
루프의 앞부분과 뒷부분은 오직 각 쓰레드의 스택에 저장된 변수만을 다루는 반면, Li, Ui, Si는 공유 카운터 변수(cnt)를 다룬다. badcnt.c의 두 피어 쓰레드가 단일 프로세서(uniprocessor)에서 동시에(concurrently) 실행될 때, 쓰레드의 어셈블리 명령어들은 어떤 순서로든 하나씩 완료된다. 따라서, 각각의 동시 실행(concurrent execution)은 두 쓰레드의 명령어들에 대한 임의의 실행 순서 를 정의하게 된다. 이렇게 실행되고 정의된 명령어들의 순서들 중 일부는 올바른 결과를 도출하지만, 다른 순서들은 그렇지 않다. 이때 핵심은 OS가 여러 피어 쓰레드의 명령어의 실행 순서를 예측하는 방법은 없다는 것이다.
예를 들어, figure 2(a)는 올바른 명령어 순서를 단계별로 보여준다. 각 쓰레드가 공유 변수 cnt를 업데이트한 후 메모리에 있는 cnt의 값은 2이며, 이는 기대한 결과이다. 반면, figure 2(b)에 나타난 명령어 실행 순서는 cnt에 대해 의도되지 않은 결과를 만든다. 이는 2번 쓰레드가 step5에서 cnt를 불러오는데, 이는 1번 쓰레드가 step2에서 cnt를 불러오고, 이를 step6에서 수정한 값을 저장한 사이에 있기 때문이다. 그 결과, cnt에는 두번의 갱신 작업이 수행되었지만, 여전히 값은 1이다.
Progress Graphs
각주
↑인스턴스는 메모리 상의 복사본을 의미하며, 인스턴스를 참조한다는 것은 해당 메모리 주소를 참조한다는 것을 의미한다.