System-Level I/O: 두 판 사이의 차이
| (같은 사용자의 중간 판 22개는 보이지 않습니다) | |||
| 36번째 줄: | 36번째 줄: | ||
==Opening and Closing Files== | ==Opening and Closing Files== | ||
===Opening files=== | ===Opening files=== | ||
애플리케이션은 <code> | 애플리케이션은 <code>open()</code> 함수를 통해 커널에게 특정 파일을 열도록 요철하며, 해당 I/O 장치에 접근한다. | ||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
#include <sys/types.h> | #include <sys/types.h> | ||
#include <sys/stat.h> | #include <sys/stat.h> | ||
#include <fcntl.h> | #include <fcntl.h> | ||
int open(char *filename, int flags, mode_t mode); // | int open(char *filename, int flags, mode_t mode); //새 파일 디스크립터를 반환, 오류가 있으면 -1 반환 | ||
</syntaxhighlight> | </syntaxhighlight> | ||
커널은 해당 파일 이름을 파일 디스크립터(file descriptor)<ref>0 이상의 정수이다</ref>로 변환하고 그 디스크립터 번호를 반환한다. 반환되는 디스크립터는 항상 프로세스에서 현재 열려 있지 않은 가장 작은 디스크립터 번호이다. 이 디스크립터는 이후 파일에 대한 모든 연산에서 사용된다.<ref>커널은 열려있는 파일에 대한 모든 정보를 추적하고 관리하나, 애플리케이션은 디스크립터만을 추적한다.</ref> 위 <code> | 커널은 해당 파일 이름을 파일 디스크립터(file descriptor)<ref>0 이상의 정수이다</ref>로 변환하고 그 디스크립터 번호를 반환한다. 반환되는 디스크립터는 항상 프로세스에서 현재 열려 있지 않은 가장 작은 디스크립터 번호이다. 이 디스크립터는 이후 파일에 대한 모든 연산에서 사용된다.<ref>커널은 열려있는 파일에 대한 모든 정보를 추적하고 관리하나, 애플리케이션은 디스크립터만을 추적한다.</ref> 위 <code>open()</code> 함수에서 flag 인자는 프로세스가 파일에 어떻게 접근하려는지를 나타내며, 이는 아래와 같다: | ||
* O_RDONLY: 읽기 전용 | * O_RDONLY: 읽기 전용 | ||
* O_WRONLY: 쓰기 전용 | * O_WRONLY: 쓰기 전용 | ||
| 93번째 줄: | 93번째 줄: | ||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
#include <unistd.h> | #include <unistd.h> | ||
int close(int fd); // | int close(int fd); //0 반환, 오류가 있을 때만 -1 반환 | ||
</syntaxhighlight> | </syntaxhighlight> | ||
커널은 위 함수의 호출 결과로 파일을 열 때 생성한 데이터 구조들을 해제하고, 디스크립터를 사용 가능한 디스크립터 풀로 되돌린다. 이때 이미 닫혀있는 디스크립터를 닫는 것은 오류이다. 또한 프로세스가 어떤 이유로든 종료되면, 커널은 열려있는 모든 파일들을 닫고 그 메모리 자원들을 해제한다. | 커널은 위 함수의 호출 결과로 파일을 열 때 생성한 데이터 구조들을 해제하고, 디스크립터를 사용 가능한 디스크립터 풀로 되돌린다. 이때 이미 닫혀있는 디스크립터를 닫는 것은 오류이다. 또한 프로세스가 어떤 이유로든 종료되면, 커널은 열려있는 모든 파일들을 닫고 그 메모리 자원들을 해제한다. | ||
==Reading and Writing Files== | ==Reading and Writing Files== | ||
| 102번째 줄: | 102번째 줄: | ||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
#include <unistd.h> | #include <unistd.h> | ||
ssize_t read(int fd, void *buf, size_t n); // | ssize_t read(int fd, void *buf, size_t n); //읽은 바이트 수 반환, 오류 시에는 -1 반환 | ||
</syntaxhighlight> | </syntaxhighlight> | ||
<code>read()</code> 함수는 디스크립터 fd의 현재 파일 위치(current file position) k로부터 최대 n 바이트를 buf에 복사하고, 그 후에 k를 n만큼 증가시킨다. 이때 파일 크기가 m 바이트일 때, <code>k≥m</code>인 상태에서 읽기 연산을 수행하면 EOF(end of file) 상태가 발생한다.<ref>파일 끝에는 명시적인 EOF 문자는 존재하지 않는다.</ref> 예를 들어 아래의 코드는 100바이트씩 계속 읽다가 더 이상 읽을 게 없으면, <code>read()</code> 함수는 EOF 상태이므로 0을 반환한다. | <code>read()</code> 함수는 디스크립터 fd의 현재 파일 위치(current file position) k로부터 최대 n 바이트를 buf에 복사하고, 그 후에 k를 n만큼 증가시킨다. 이때 파일 크기가 m 바이트일 때, <code>k≥m</code>인 상태에서 읽기 연산을 수행하면 EOF(end of file) 상태가 발생한다.<ref>파일 끝에는 명시적인 EOF 문자는 존재하지 않는다.</ref> 예를 들어 아래의 코드는 100바이트씩 계속 읽다가 더 이상 읽을 게 없으면, <code>read()</code> 함수는 EOF 상태이므로 0을 반환한다. | ||
| 121번째 줄: | 121번째 줄: | ||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
#include <unistd.h> | #include <unistd.h> | ||
ssize_t write(int fd, const void *buf, size_t n); // | ssize_t write(int fd, const void *buf, size_t n); //쓴 바이트 수 반환, 오류시에만 -1 반환 | ||
</syntaxhighlight> | </syntaxhighlight> | ||
<code>write()</code> 함수는 buf 안에 있는 데이터에서 최대 n 바이트를 복사하여 fd에 해당하는 파일의 현재 파일 위치 k에 적고 k를 갱신한다. 예를 들어, 아래 코드는 "hello"라는 5바이트짜리 문자열을 파일 fd에 쓴다: | <code>write()</code> 함수는 buf 안에 있는 데이터에서 최대 n 바이트를 복사하여 fd에 해당하는 파일의 현재 파일 위치 k에 적고 k를 갱신한다. 예를 들어, 아래 코드는 "hello"라는 5바이트짜리 문자열을 파일 fd에 쓴다: | ||
| 133번째 줄: | 133번째 줄: | ||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
#include <unistd.h> | #include <unistd.h> | ||
off_t lseek(int fd, off_t offset, int whence); // | off_t lseek(int fd, off_t offset, int whence); //현재 파일 위치 반환, 오류시 -1 반환 | ||
</syntaxhighlight> | </syntaxhighlight> | ||
<code>lseek</code> 함수는 fd에 해당하는 파일의 현재 파일 위치를 offset byte만큼 옮긴다. 이때 옮긴 위치에 기준을 잡기 위해서 아래 표에 정리되어 있는 whence 옵션이 사용된다: | <code>lseek</code> 함수는 fd에 해당하는 파일의 현재 파일 위치를 offset byte만큼 옮긴다. 이때 옮긴 위치에 기준을 잡기 위해서 아래 표에 정리되어 있는 whence 옵션이 사용된다: | ||
| 181번째 줄: | 181번째 줄: | ||
* 네트워크 소켓을 읽고 쓰는 경우: 열린 파일이 네트워크 소켓에 해당한다면, 내부 버퍼 제약과 긴 네트워크 지연으로 인해 <code>read()</code>, <code>write()</code> 함수는 짧은 수치를 반환할 수 있다. 또한, 리눅스 파이프(pipe)를 <code>read()</code>, <code>write()</code> 함수로 호출할 때도 발생할 수 있다. | * 네트워크 소켓을 읽고 쓰는 경우: 열린 파일이 네트워크 소켓에 해당한다면, 내부 버퍼 제약과 긴 네트워크 지연으로 인해 <code>read()</code>, <code>write()</code> 함수는 짧은 수치를 반환할 수 있다. 또한, 리눅스 파이프(pipe)를 <code>read()</code>, <code>write()</code> 함수로 호출할 때도 발생할 수 있다. | ||
==Robust I/O package== | ==[[Robust I/O package]]== | ||
자세한 내용은 [[Robust I/O package]] 문서를 참조하십시오. | |||
== | ==Reading File Metadata== | ||
응용 프로그램은 <code> | [[파일:The stat structure..png|대체글=Figure 3. The stat structure.|섬네일|400x400픽셀|Figure 3. The stat structure.]] | ||
응용 프로그램은 <code>stat()</code> 혹은 <code>fstat()</code> 함수를 호출하여 파일의 메타데이터(metadata)를 가져올 수 있다. 메타데이터란 파일 그 자체가 아니라, 파일을 설명하는 정보를 의미한다.<ref>파일 크기, 파일 종류, 접근 권한, 생성 시간 등이 이에 해당한다.</ref> 이때 메타 데이터는 커널에 의해서 관리된다. | |||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
#include | #include <unistd.h> | ||
#include <sys/stat.h> | |||
//Returns: | //Returns: 0 if OK, −1 on error | ||
int stat(const char *filename, struct stat *buf); | |||
int fstat(int fd, struct stat *buf); | |||
</syntaxhighlight> | </syntaxhighlight> | ||
<code> | <code>stat()</code> 함수는 파일 이름을 입력으로 받아, Figure 3에 나타난 stat 구조체의 필드를 채운다.<br> | ||
<code>fstat()</code> 함수는 이와 유사하지만, 파일 이름 대신 파일 디스크립터를 입력으로 받는다.<br> | |||
stat 구조체의 필드 중 실제로 많이 쓰는 건 st_mode, st_size, st_mtime 정도이다. | |||
* st_size 멤버: 파일 크기(바이트 단위)를 담고 있다. | |||
* st_mode 멤버: 파일 권한 비트와 파일 타입 둘을 인코딩한 값이다. | |||
아래는 file metadata에 대한 접근 예제이다: | |||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
int main(int argc, char **argv) | |||
{ | { | ||
struct stat stat; | |||
char *type, *readok; | |||
Stat(argv[1], &stat); | |||
//파일 타입을 식별한다. | |||
if (S_ISREG(stat.st_mode)) type = "regular"; | |||
else if (S_ISDIR(stat.st_mode)) type = "directory"; | |||
else type = "other"; | |||
//read address를 확인한다. | |||
if ((stat.st_mode & S_IRUSR)) readok = "yes"; | |||
else readok = "no"; | |||
printf("type: %s, read: %s\n", type, readok); | |||
exit(0); | |||
} | } | ||
</syntaxhighlight> | </syntaxhighlight> | ||
<syntaxhighlight lang="bash"> | |||
linux> ./statcheck statcheck.c | |||
type: regular, read: yes | |||
linux> chmod 000 statcheck.c | |||
linux> ./statcheck statcheck.c | |||
type: regular, read: no | |||
linux> ./statcheck .. | |||
type: directory, read: yes | |||
</syntaxhighlight> | </syntaxhighlight> | ||
위는 stat 구조체를 바탕으로 파일에 메타데이터에 접근하고 있다. 이때, 위에서 Linux가 정의한 매크로 조건 함수들(predicate macros)을 사용하였다. 이는 아래와 같다. | |||
* S_ISREG(m): 이 파일은 일반 파일(regular file)인가? | |||
* S_ISDIR(m): 이 파일은 디렉터리 파일인가? | |||
* S_ISSOCK(m): 이 파일은 네트워크 소켓인가? | |||
== | ==Reading Directory Contents== | ||
응용 프로그램은 readdir 계열의 함수들을 사용하여 디렉터리의 내용을 읽을 수 있다. | |||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
#include | #include <sys/types.h> | ||
#include <dirent.h> | |||
DIR *opendir(const char *name); //Returns: pointer to handle if OK, NULL on error | |||
</syntaxhighlight> | </syntaxhighlight> | ||
<code> | <code>opendir()</code> 함수는 경로 이름(pathname)을 받아서 디렉터리 스트림에 대한 포인터를 반환한다. 스트림(stream)이란 항목들의 ordered list에 대한 abstraction이며, 여기서는 디렉터리 엔트리(entry)들의 리스트이다. | ||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
#include <dirent.h> | |||
//Returns: pointer to next directory entry if OK, NULL if no more entries or error | |||
struct dirent *readdir(DIR *dirp); | |||
</syntaxhighlight> | </syntaxhighlight> | ||
<code>readdir()</code> 함수는 스트림 dirp에서 다음 디렉터리 항목에 대한 포인터를 반환하며, 더 이상 항목이 없으면 NULL을 반환한다. 이때 각각의 디렉토리 항목은 다음과 같은 형태를 가지고 있는 구조체이다: | |||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
struct dirent { | |||
{ | ino_t d_ino; /* inode 번호(해당 파일의 위치) */ | ||
char d_name[256]; /* 파일 이름 */ | |||
}; | |||
</syntaxhighlight> | </syntaxhighlight> | ||
<code>closedir()</code> 함수는 디렉터리 스트림을 닫고 관련된 리소스를 해제한다. | |||
<syntaxhighlight lang="cpp"> | <syntaxhighlight lang="cpp"> | ||
#include <dirent.h> | |||
int closedir(DIR *dirp);//Returns: 0 on success, −1 on error | |||
</syntaxhighlight> | |||
==Sharing Files== | |||
Linux 파일은 여러 가지 방식으로 공유될 수 있다. 이때 커널이 열린 파일(open file)을 어떻게 표현하는지를 명확히 이해하지 않으면, 파일 공유라는 개념은 매우 혼란스러울 수 있다. 커널은 열린 파일을 다음의 세 가지 자료 구조를 사용하여 표현한다: | |||
# 디스크립터 테이블(Descriptor table) | |||
#* 각 프로세스는 자신만의 디스크립터 테이블을 가지며, 각 항목은 프로세스의 열린 파일 디스크립터 번호로 인덱싱된다. | |||
#* 각 디스크립터 항목은 파일 테이블(file table)의 항목을 가리킨다. | |||
# 파일 테이블(File table) | |||
#* 모든 프로세스는 하나의 파일 테이블을 공유하며, 이는 열린 파일들의 집합을 표현하고 관리한다. | |||
#* 각 파일 테이블 항목은 다음을 포함한다: | |||
#** 현재 파일 위치(file position) | |||
#** 이 항목을 가리키는 디스크립터 수를 나타내는 reference count | |||
#** v-node 테이블 항목에 대한 포인터 | |||
#* 디스크립터를 닫을 때, 해당 파일 테이블 항목의 reference count는 감소하며, 커널은 reference count가 0이 될 때까지 해당 파일 테이블 항목을 삭제하지 않는다. | |||
# v-node 테이블 | |||
#* 파일 테이블과 마찬가지로, v-node 테이블도 모든 프로세스가 공유한다. | |||
#* 각 항목은 stat 구조체의 대부분의 정보(st_mode, st_size 등)를 포함한다. | |||
<gallery widths="430" heights="250"> | |||
파일:Typical kernel data structures for open files.png|Figure 4. Typical kernel data structures for open files | |||
파일:File sharing.png|Figure 5. File sharing | |||
</gallery> | |||
[[파일:How a child process inherits the parent’s open files.png|대체글=Figure 6. How a child process inherits the parent’s open files|섬네일|Figure 6. How a child process inherits the parent’s open files|400x400픽셀]]Figure 4는 디스크립터 1번과 4번이 서로 다른 파일 테이블 항목을 통해 서로 다른 파일을 참조하는 것을 보여준다. 이는 일반적인 경우로, 파일이 공유되지 않고 각 디스크립터가 별개의 파일을 참조하는 경우이다. 하지만, 여러 개의 디스크립터가 서로 다른 파일 테이블 항목을 통해 동일한 파일을 참조할 수도 있다. 이는 Figure 5에서 잘 나타나 있다. 이러한 상황은 같은 파일 이름으로 <code>open()</code> 함수를 두 번 이상 호출할 때 발생한다. 이때 '''각 디스크립터는 자체적인 파일 위치(file position)'''를 가지며, '''서로 다른 디스크립터로 읽기를 수행하면, 파일의 서로 다른 위치에서 데이터를 읽어올 수 있다'''는 것이다. Figure 5의 경우에서 fd1과 fd4는 동일한 파일을 참조하고 있음에도, 서로 다른 파일 위치를 가지고 있어 독립적인 읽기, 쓰기의 수행이 가능하다. | |||
부모와 자식 프로세스가 '''파일을 공유한다는 것은 서로의 디스크립터가 같은 파일 위치를 가지고 있다는 것을 의미'''한다. <code>fork()</code> 호출 이전에, 부모 프로세스가 Figure 4와 같은 열린 파일을 가지고 있다고 가정하자. Figure 6는 <code>fork()</code> 함수가 실행된 후에 자식 프로세스는 부모의 디스크립터 테이블의 복사본을 가지고 있는 상황을 보여준다. 즉, '''부모와 자식은 동일한 파일 테이블 항목들을 공유'''하며, | |||
따라서 동일한 파일 위치(file position)를 공유한다. 따라서 부모와 자식 모두 해당 파일 테이블을 참조하는 디스크립터를 닫아야 커널이 해당 파일 테이블 항목을 삭제할 수 있다. | |||
==I/O Redirection== | |||
Linux 셸은 사용자가 표준 입력 및 출력을 디스크 파일과 연결할 수 있도록 하는 I/O 리디렉션 연산자들을 제공한다. 예를 들어, | |||
<syntaxhighlight lang="shell"> | |||
linux> ls > foo.txt | |||
</syntaxhighlight> | |||
를 입력하면 셸은 ls 프로그램을 로드하고 실행하며, 표준 출력을 디스크 파일 foo.txt로 리디렉션한다. [[파일:Dup2() function call.png|대체글=Figure 7. dup2() function call|섬네일|Figure 7. dup2() function call]] | |||
[[파일:Kernel data structures after redirecting standard output by calling dup2(4,1).png|대체글=Fgure 8. Kernel data structures after redirecting standard output by calling dup2(4,1)|섬네일|300x300px|Fgure 8. Kernel data structures after redirecting standard output by calling dup2(4,1)]]이때 I/O redirection을 실행하는 방법은 몇가지가 있지만, 그중 대표적인 방법은 <code>'''dup2()'''</code> 함수를 이용하는 것이다. | |||
<syntaxhighlight lang="c"> | |||
#include <unistd.h> | |||
int dup2(int oldfd, int newfd); //양수인 파일 디스크립터, 오류일 때 -1 반환 | |||
</syntaxhighlight> | |||
dup2 함수는 디스크립터 테이블 항목 oldfd를 newfd에 복사한다. 이때 newfd의 기존 항목은 덮어쓰며, 만약 newfd가 이미 열려 있다면 dup2는 먼저 그것을 닫은 다음 oldfd를 복사한다. 해당 함수의 동작 방식은 figure 7에 나타나 있다. 예를 들어 <code>dup2(4, 1)</code>을 호출하기 전 상황이 Figure 4와 같다고 하자. 만약 <code>dup2(4, 1)</code>을 호출한 후에는 상황은 Figure 8과 같이 되어 있다: | |||
* 두 디스크립터 모두 파일 B를 가리킨다. | |||
* 파일 A는 닫혔고, 그에 해당하는 파일 테이블 및 v-node 테이블 항목도 삭제되었다. | |||
* 그리고 파일 B의 referential count는 1 증가한다. | |||
이 시점부터, 표준 출력으로 쓰이는 모든 데이터는 파일 B로 리디렉션된다. | |||
==Standard I/O== | |||
C 언어는 프로그래머에게 Unix I/O보다 더 고수준의 대안을 제공하는 고수준 입력 및 출력 함수 집합, 즉 표준 I/O 라이브러리를 정의한다. 해당 라이브러리는 다음과 같은 함수들을 제공한다. | |||
* 파일 열고 닫기: <code>fopen()</code>, <code>fclose()</code> | |||
* 바이트 I/O: <code>fread()</code>, <code>fwrite()</code> | |||
* 문자열 I/O: <code>fgets()</code>, <code>fputs()</code> | |||
* formatted I/O: <code>scanf()</code>, <code>printf()</code> | |||
표준 I/O 라이브러리는 열린 파일을 스트림(stream)으로 모델링한다. 이때 스트림이란 FILE 타입의 구조체를 가리키는 포인터이다. 모든 ANSI C 프로그램은 다음과 같은 세 개의 열린 스트림으로 시작한다: | |||
<syntaxhighlight lang="shell"> | |||
#include <stdio.h> | |||
extern FILE *stdin; /* 표준 입력 (디스크립터 0) */ | |||
extern FILE *stdout; /* 표준 출력 (디스크립터 1) */ | |||
extern FILE *stderr; /* 표준 에러 (디스크립터 2) */ | |||
</syntaxhighlight> | </syntaxhighlight> | ||
[[파일:Stream Buffer.png|대체글=Figure 9. Stream Buffer|가운데|섬네일|331x331px|Figure 9. Stream Buffer]] | |||
[[파일:Buffering in Standard I-O.png|대체글=Figure 10. Buffering in Standard I/O|섬네일|300x300픽셀|'''Figure 10. Buffering in Standard I/O''']] | |||
FILE 타입의 스트림은 파일 디스크립터와 스트림 버퍼에 대한 abstraction이며, 해당 스트림 버퍼의 목적은 RIO I/O의 그것과 같다. 즉, 비용이 많이 드는 Linux I/O 시스템 호출의 수를 최소화하기 위함이다. 응용 프로그램은 종종 한번에 하나의 문자를 읽고 쓰는 경우가 있다. 만약 스트림 버퍼가 없다면 각각의 입출력에 대해 커널이 호출되어 프로그램의 동작 속도가 느려질 것이다. 하지만 스트림 버퍼는 이를 해결할 수 있다.<br> | |||
예를 들어, 어떤 프로그램이 <code>getc</code> 표준 I/O 함수를 반복 호출한다고 가정하자. | |||
# <code>getc()</code> 함수가 처음 호출되면, 라이브러리는 <code>read()</code> 함수를 한 번 호출하여 스트림 버퍼를 채운다. | |||
# 그 다음, 버퍼의 첫 바이트를 응용 프로그램에 반환한다. | |||
# 버퍼에 읽히지 않은 바이트가 남아 있는 한, 이후의 <code>getc()</code> 함수 호출들은 스트림 버퍼에서 처리될 수 있다. | |||
[[파일:Linux strace.png|대체글=Figure 11. Linux strace|섬네일|'''Figure 11. Linux strace''' ]] | |||
Figure 10은 스트림 버퍼(lined-buffer)가 어떻게 작동하는지 보여주는 예시이다. 각 문자 출력은 stdout의 내부 버퍼에 저장되며, '\n'을 만나거나, fflush(stdout)을 하거나, exit() 또는 main 종료 시 write() 호출되어 출력된다. 해당 예시에서는, | |||
# printf("h"); → 버퍼에 'h' 저장 | |||
# printf("e"); → 버퍼에 'e' 추가 | |||
# printf("l"); → 버퍼에 'l' 추가 | |||
# printf("l"); → 버퍼에 'l' 추가 | |||
# printf("o"); → 버퍼에 'o' 추가 | |||
# printf("\n"); → 버퍼에 '\n' 추가됨과 동시에 버퍼 플러시 발생 | |||
이를 리눅스 strace로 관찰하면, Figure 11과 같이 5개의 printf()가 모두 버퍼에 쌓였다가, write(1, ...)이 한 번만 호출되고 "hello\n" 전체가 출력된 것처럼 보인다. | |||
==Unix I/O vs. Standard I/O vs. RIO== | |||
[[파일:Standard I-O and RIO are implemented using low-level Unix I-O.png|대체글=Figure 12. Standard I/O and RIO are implemented using low-level Unix I/O|가운데|섬네일|500x500픽셀|'''Figure 12. Standard I/O and RIO are implemented using low-level Unix I/O''' ]] | |||
Unix I/O 모델은 OS 커널에 의해 구현된다. 이 모델은 애플리케이션에 <code>open()</code>, <code>close()</code>, <code>lseek()</code>, <code>read()</code>, <code>write()</code>, <code>stat()</code>과 같은 함수를 통해 제공된다. 더 고수준의 Rio 함수들과 표준 I/O 함수들은 Unix I/O 함수들을 기반으로 하여 구현된다. | |||
* Rio 함수들은 read와 write에 대한 견고한(wrapper) 래퍼 함수로, 정식으로 제공되는 함수는 아니다. | |||
** Rio 함수들은 short count를 자동으로 처리하고, 효율적인 버퍼링 I/O 방식을 제공한다. | |||
* 표준 I/O 함수들은 <code>printf()</code>와 <code>scanf()</code> 함수와 같은 형식화된(formatted) I/O 함수를 포함해, 보다 완전한 버퍼링 I/O 함수를 제공한다. | |||
이때 어떠한 기준으로 I/O 함수들을 사용해야 하는가? | |||
# 가능한 한 가장 고수준의 I/O 함수들을 이용해야 한다. | |||
# 표준 I/O 함수: 디스크와 터미널 장치에서의 I/O에 가장 적합한 방법이다.<ref><code>stat()</code> 함수는 예외인데, 이는 표준 I/O에는 대응 함수가 없기 때문이다.</ref> | |||
# Unix I/O 함수: 시그널 핸들러 내에서는 UNIX I/O 함수가 async-signal-safe하므로 사용되어야 한다. | |||
# RIO I/O 함수: 네트워크 소켓에 대한 I/O를 실행하고자 할 때 사용되어야 한다. | |||
# 마지막으로, <code>scanf()</code>나 <code>rio_readlineb()</code>를 binary 파일 읽기에 사용해서는 안된다. | |||
===Pros and Cons of Unix I/O=== | |||
Unix I/O의 장점은 아래와 같다. | |||
* 가장 일반적이고 오버헤드가 가장 낮은 I/O 방식으로, 모든 I/O 패키지들이 Unix I/O 함수들 위에 구현된다. | |||
* 파일 메타데이터에 접근할 수 있어 <code>stat()</code>, <code>fstat()</code>와 같은 함수를 사용할 수 있다. | |||
* 시그널 핸들러에서 안전하게 사용 가능(async-signal-safe)하여 <code>read()</code>, <code>write</code> 함수는 시그널 핸들러 안에서도 안심하고 쓸 수 있다. | |||
Unix I/O의 단점은 아래와 같다. | |||
* short count를 직접 처리해야 하므로 반복해서 <code>read()</code>, <code>write</code> 함수를 호출해야 한다. | |||
* 텍스트 라인 읽기를 효율적으로 하려면 버퍼링이 필요한데, 직접 버퍼를 만들고 다루는 것은 오류 발생 가능성이 높다. | |||
===Pros and Cons of Standard I/O=== | |||
표준 I/O의 장점은 아래와 같다. | |||
* 버퍼를 이용해 시스템 콜(read, write) 횟수를 줄여 성능을 향상시킬 수 있다. | |||
** <code>getc()</code> 함수를 여러 번 호출해도 실제 <code>read()</code> 함수 호출은 한 번만 이루어진다. | |||
** short count를 자동으로 처리할 수 있다. | |||
</ | 표준 I/O의 단점은 아래와 같다. | ||
* 파일 메타데이터에 접근하는 기능이 없어 <code>stat()</code> 함수 호출 등은 Unix I/O로만 가능하다. | |||
* async-signal-safe한 함수가 아니기 때문에 시그널 핸들러에서 쓰면 예기치 않은 동작이 발생할 수 있다. | |||
* 네트워크 소켓의 I/O에는 부적합하다. | |||
==각주== | ==각주== | ||
[[분류:컴퓨터 시스템]] | [[분류:컴퓨터 시스템]] | ||
2025년 4월 22일 (화) 08:14 기준 최신판
상위 문서: 컴퓨터 시스템
개요
입출력(I/O)은 주기억장치(main memory)와 디스크 드라이브, 터미널, 네트워크와 같은 외부 장치(external devices) 사이에서 데이터를 복사하는 과정이다. 입력 연산(input operation)은 I/O 장치로부터 데이터를 주기억장치로 복사하고, 출력 연산(output operation)은 데이터를 주기억장치에서 장치로 복사한다.
해당 문서에서는 UNIX I/O와 표준 I/O의 일반적인 개념과, C 프로그램에서 이를 안정적으로 사용하는 방법을 설명한다.
UNIX I/O
리눅스 파일은 아래와 같은 m 바이트의 시퀸스로 구성된다.
B1, B2, ..., Bk, ..., Bm-1
모든 I/O 장치들(예: 네트워크, 디스크, 터미널, 커널! 등)은 아래와 같이 파일로 모델링되며, 모든 I/O는 해당 파일들을 읽고 쓰는 방식으로 수행된다.
/dev/sda2 (/usrdiskpartition) /dev/tty2 (terminal) /boot/vmlinuz-3.13.0-55-generic (kernel image) /proc (kernel data structures)
I/O 장치들을 모두 파일로 매핑하는 방식 덕분에, 리눅스 커널은 UNIX I/O로 불리는 단순하고 저수준(low-level)의 인터페이스를 제공할 수 있다. 이를 통해 모든 I/O 작업들을 일관되고 통일된 방식으로 수행할 수 있다.
Files
각 리눅스 시스템 내에서의 역할을 나타내는 type을 가진다:
- 일반 파일(regular file)은 임의의 데이터로 구성된다. 애플리케이션 들은 종종 일반 파일 들을 ASCII 혹은 유니코드 문자만을 포함하는 텍스트 파일(text file)과, 그 외의 모든 것을 포함하는 바이너리 파일(binary file) 을 구분하지만, 커널은 이를 구분하지 않는다. 따라서 UNIX I/O도 텍스트 파일과 바이너리 파일을 구분하지 않는다. 리눅스 텍스트 파일은 단순히 텍스트 라인들의 시퀸스(sequence of text lines)로 구성되며, 각 줄(text line)은 문자들의 시퀸스(sequence of characters)로 이루어지고 줄바꿈 문자('\n')[1]로 종료된다.
- 디렉토리(directory)는 링크(link)들의 배열로 구성된 파일이며, 각 링크는 파일 이름을 파일(혹은 디렉토리)에 매핑한다. 각 디렉토리는 적어도 두 개의 항목을 가지고 있다. 먼저
.는 디렉토리 자신을 가리키는 링크이고,..는 디렉토리 계층 구조에서 상위 디렉토리를 가리키는 링크이다. 디렉토리는mkdir명령어로 만들 수 있고,ls명령어로 안의 내용을 볼 수 있으며,rmdir명령어를 통해서 삭제할 수 있다. - 소켓(socket)은 네트워크를 통해 다른 프로세스와 통신하기 위해 사용되는 파일이다.
그외에도 named pipe, symbolic link, character and block deviced와 같은 여러 type들이 추가로 존재하나, 이에 대해서는 다루지 않느다.
Directory hierarchy

리눅스 커널은 모든 파일을 루트(root) 디렉터리 /로 고정된 단일 디렉터리 계층 구조 안에 조직한다. 시스템 내의 각 파일은 루트 디렉터리의 직계 또는 간접 후손(direct or indirect descendant)이다. Figure 1은 리눅스 시스템 내의 디렉토리 계층의 일부를 보여준다.
각 프로세스는 컨텍스트의 일부로 현재의 작업 디렉터리(current working directory)를 가지며, 이는 디렉토리 계층 내에서 현재 위치를 나타낸다. 이때, cd 명령어를 통해 셸(shell)의 현재 작업 디렉터리를 변경할 수 있다.
디렉더리 계층에서의 위치는 경로명(pathname) 으로 지정된다. 경로명은 /로 구분된 일련의 파일 이름들로 구성된 문자열이다.[2] 경로명은 두 가지 형태가 있다:
- 절대 경로명(absolute pathname):
/로 시작하며, 루트 디렉토리로부터의 경로를 나타낸다.- hello.c의 절대 경로명:
/home/droh/hello.c
- hello.c의 절대 경로명:
- 상대 경로명(relative pathname): 파일 이름으로 시작하며, 현재 작업 디렉터리로부터의 경로를 나타낸다.
/home/droh가 현재 작업 디렉터리일 때 hello.c의 상대 경로명:./hello.c/home/bryant가 현재 작업 디렉터리일 때 hello.c의 상대 경로명:../home/droh/hello.c
Opening and Closing Files
Opening files
애플리케이션은 open() 함수를 통해 커널에게 특정 파일을 열도록 요철하며, 해당 I/O 장치에 접근한다.
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(char *filename, int flags, mode_t mode); //새 파일 디스크립터를 반환, 오류가 있으면 -1 반환
커널은 해당 파일 이름을 파일 디스크립터(file descriptor)[3]로 변환하고 그 디스크립터 번호를 반환한다. 반환되는 디스크립터는 항상 프로세스에서 현재 열려 있지 않은 가장 작은 디스크립터 번호이다. 이 디스크립터는 이후 파일에 대한 모든 연산에서 사용된다.[4] 위 open() 함수에서 flag 인자는 프로세스가 파일에 어떻게 접근하려는지를 나타내며, 이는 아래와 같다:
- O_RDONLY: 읽기 전용
- O_WRONLY: 쓰기 전용
- O_RDWR: 읽기 및 쓰기
또한, flags 인자는 추가적인 옵션을 제공하는 하나 이상의 비트 마스크(bit mask)와 OR 연산으로 결합될 수 있다.
- O_CREAT: 파일이 존재하지 않으면 빈 파일을 새로 만든다.
- O_TRUNC: 파일이 이미 존재하면 해당 파일을 빈 파일로 만든다.
- O_APPEND: 쓰기 작업(
write())을 할 때마다, 커널이 자동으로 파일의 맨 끝으로 이동해서 쓰게 한다.[5]
예를 들어, 이어 쓰고자 할 때, 파일을 쓰기 전용으로 여는 방법은 다음과 같다.
fd = Open("foo.txt", O_WRONLY|O_APPEND, 0);
또한 모든 리눅스 프로세스는 생성되거나 시작하는 즉시 기본으로 열려있는 세개의 파일(디스크립터)를 가지고 있는데, 이는 다음 표와 같다:
| 이름 | 디스크립터 | 상수 | 역할 |
|---|---|---|---|
| standard input | 0 | STDIN_FILENO | 키보드 등에서 입력 받기 |
| standard output | 1 | STDOUT_FILENO | 화면(터미널)으로 출력하기 |
| standard error | 2 | STDERR_FILENO | 에러 메시지 출력하기 |
아래는 기본 디스크립터를 이용하여 터미널에서 1byte씩 읽고 출력하는 예제 프로그램이다.
#include "csapp.h"
int main(void) {
char c;
while (Read(STDIN_FILENO, &c, 1) != 0)
Write(STDOUT_FILENO, &c, 1);
exit(0);
}
Colsing files
애플리케이션이 파일에 대한 접근을 마치면, close() 함수를 호출하여 해당 파일을 닫아달라고 커널에 요청한다:
#include <unistd.h>
int close(int fd); //0 반환, 오류가 있을 때만 -1 반환
커널은 위 함수의 호출 결과로 파일을 열 때 생성한 데이터 구조들을 해제하고, 디스크립터를 사용 가능한 디스크립터 풀로 되돌린다. 이때 이미 닫혀있는 디스크립터를 닫는 것은 오류이다. 또한 프로세스가 어떤 이유로든 종료되면, 커널은 열려있는 모든 파일들을 닫고 그 메모리 자원들을 해제한다.
Reading and Writing Files
Reading files
애플리케이션은 read() 함수를 호출하여 입력 연산을 수행한다:
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t n); //읽은 바이트 수 반환, 오류 시에는 -1 반환
read() 함수는 디스크립터 fd의 현재 파일 위치(current file position) k로부터 최대 n 바이트를 buf에 복사하고, 그 후에 k를 n만큼 증가시킨다. 이때 파일 크기가 m 바이트일 때, k≥m인 상태에서 읽기 연산을 수행하면 EOF(end of file) 상태가 발생한다.[6] 예를 들어 아래의 코드는 100바이트씩 계속 읽다가 더 이상 읽을 게 없으면, read() 함수는 EOF 상태이므로 0을 반환한다.
int fd = open("myfile.txt", O_RDONLY);
char buf[100];
int n;
while ((n = read(fd, buf, 100)) > 0) {
// 여기서 buf 안의 데이터를 사용함
}
if (n == 0) {
//n == 0 이면 EOF 도달, n == -1이면 에러 종료
}
Writing files
애플리케이션은 write() 함수를 호출하여 쓰기 연산을 수행한다:
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t n); //쓴 바이트 수 반환, 오류시에만 -1 반환
write() 함수는 buf 안에 있는 데이터에서 최대 n 바이트를 복사하여 fd에 해당하는 파일의 현재 파일 위치 k에 적고 k를 갱신한다. 예를 들어, 아래 코드는 "hello"라는 5바이트짜리 문자열을 파일 fd에 쓴다:
char msg[] = "hello";
write(fd, msg, 5);
Changing the current file position
애플리케이션은 lseek 함수를 호출하여 현재의 파일 위치를 바꾼다:
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence); //현재 파일 위치 반환, 오류시 -1 반환
lseek 함수는 fd에 해당하는 파일의 현재 파일 위치를 offset byte만큼 옮긴다. 이때 옮긴 위치에 기준을 잡기 위해서 아래 표에 정리되어 있는 whence 옵션이 사용된다:
| 옵션 | 설명 |
|---|---|
| SEEK_SET | Move from the start of the file |
| SEEK_CUR | Move from the current position of the file |
| SEEK_END | Move from the end of the file |
아래는 lseek 함수가 사용된 코드의 예시이다.
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd = open("example.txt", O_RDWR); //파일 열기
if (fd == -1) { //적절한 파일 디스크립터인지 확인
perror("open");
return 1;
}
off_t pos = lseek(fd, 0, SEEK_CUR); //pos에 현재 파일 위치 저장
printf("Current position: %ld\n", pos);
lseek(fd, 5, SEEK_SET); // 파일 시작에서 5바이트 앞으로 이동
write(fd, "HELLO", 5); // 파일 처음에서 5번째 바이트에 HELLO 덮어쓰기
off_t end = lseek(fd, 0, SEEK_END); //현재 파일 위치를 파일의 끝으로 이동
printf("File size: %ld bytes\n", end);
close(fd); //파일 닫기
return 0;
}
Short counts
어떤 상황에서는 read(), write() 함수가 요청받은 바이트(n)보다 적은 양을 전송하기도 한다. 이를 short counts라고 하며, 이는 오류를 의미하지 않는다. 이는 다음과 같은 상황일때 발생한다:
- 읽기 도중 EOF를 만난 경우: 예를 들어, 현재 파일 위치로부터 남은 바이트가 20바이트뿐인 파일을 50바이트씩 읽고 있다고 하자. 이 경우 다음 read 호출은 20이라는 짧은 수치를 반환하고, 그 다음 호출은 0을 반환하여 EOF를 나타낸다.
- 터미널에서 텍스트 줄을 읽는 경우: 열린 파일이 터미널(즉, 키보드와 디스플레이)과 연결되어 있다면, 각
read()함수 호출은 한 줄의 텍스트만 전송하고, 이 줄의 크기만큼의 short counts를 반환한다. - 네트워크 소켓을 읽고 쓰는 경우: 열린 파일이 네트워크 소켓에 해당한다면, 내부 버퍼 제약과 긴 네트워크 지연으로 인해
read(),write()함수는 짧은 수치를 반환할 수 있다. 또한, 리눅스 파이프(pipe)를read(),write()함수로 호출할 때도 발생할 수 있다.
Robust I/O package
자세한 내용은 Robust I/O package 문서를 참조하십시오.
Reading File Metadata

응용 프로그램은 stat() 혹은 fstat() 함수를 호출하여 파일의 메타데이터(metadata)를 가져올 수 있다. 메타데이터란 파일 그 자체가 아니라, 파일을 설명하는 정보를 의미한다.[7] 이때 메타 데이터는 커널에 의해서 관리된다.
#include <unistd.h>
#include <sys/stat.h>
//Returns: 0 if OK, −1 on error
int stat(const char *filename, struct stat *buf);
int fstat(int fd, struct stat *buf);
stat() 함수는 파일 이름을 입력으로 받아, Figure 3에 나타난 stat 구조체의 필드를 채운다.
fstat() 함수는 이와 유사하지만, 파일 이름 대신 파일 디스크립터를 입력으로 받는다.
stat 구조체의 필드 중 실제로 많이 쓰는 건 st_mode, st_size, st_mtime 정도이다.
- st_size 멤버: 파일 크기(바이트 단위)를 담고 있다.
- st_mode 멤버: 파일 권한 비트와 파일 타입 둘을 인코딩한 값이다.
아래는 file metadata에 대한 접근 예제이다:
int main(int argc, char **argv)
{
struct stat stat;
char *type, *readok;
Stat(argv[1], &stat);
//파일 타입을 식별한다.
if (S_ISREG(stat.st_mode)) type = "regular";
else if (S_ISDIR(stat.st_mode)) type = "directory";
else type = "other";
//read address를 확인한다.
if ((stat.st_mode & S_IRUSR)) readok = "yes";
else readok = "no";
printf("type: %s, read: %s\n", type, readok);
exit(0);
}
linux> ./statcheck statcheck.c
type: regular, read: yes
linux> chmod 000 statcheck.c
linux> ./statcheck statcheck.c
type: regular, read: no
linux> ./statcheck ..
type: directory, read: yes
위는 stat 구조체를 바탕으로 파일에 메타데이터에 접근하고 있다. 이때, 위에서 Linux가 정의한 매크로 조건 함수들(predicate macros)을 사용하였다. 이는 아래와 같다.
- S_ISREG(m): 이 파일은 일반 파일(regular file)인가?
- S_ISDIR(m): 이 파일은 디렉터리 파일인가?
- S_ISSOCK(m): 이 파일은 네트워크 소켓인가?
Reading Directory Contents
응용 프로그램은 readdir 계열의 함수들을 사용하여 디렉터리의 내용을 읽을 수 있다.
#include <sys/types.h>
#include <dirent.h>
DIR *opendir(const char *name); //Returns: pointer to handle if OK, NULL on error
opendir() 함수는 경로 이름(pathname)을 받아서 디렉터리 스트림에 대한 포인터를 반환한다. 스트림(stream)이란 항목들의 ordered list에 대한 abstraction이며, 여기서는 디렉터리 엔트리(entry)들의 리스트이다.
#include <dirent.h>
//Returns: pointer to next directory entry if OK, NULL if no more entries or error
struct dirent *readdir(DIR *dirp);
readdir() 함수는 스트림 dirp에서 다음 디렉터리 항목에 대한 포인터를 반환하며, 더 이상 항목이 없으면 NULL을 반환한다. 이때 각각의 디렉토리 항목은 다음과 같은 형태를 가지고 있는 구조체이다:
struct dirent {
ino_t d_ino; /* inode 번호(해당 파일의 위치) */
char d_name[256]; /* 파일 이름 */
};
closedir() 함수는 디렉터리 스트림을 닫고 관련된 리소스를 해제한다.
#include <dirent.h>
int closedir(DIR *dirp);//Returns: 0 on success, −1 on error
Sharing Files
Linux 파일은 여러 가지 방식으로 공유될 수 있다. 이때 커널이 열린 파일(open file)을 어떻게 표현하는지를 명확히 이해하지 않으면, 파일 공유라는 개념은 매우 혼란스러울 수 있다. 커널은 열린 파일을 다음의 세 가지 자료 구조를 사용하여 표현한다:
- 디스크립터 테이블(Descriptor table)
- 각 프로세스는 자신만의 디스크립터 테이블을 가지며, 각 항목은 프로세스의 열린 파일 디스크립터 번호로 인덱싱된다.
- 각 디스크립터 항목은 파일 테이블(file table)의 항목을 가리킨다.
- 파일 테이블(File table)
- 모든 프로세스는 하나의 파일 테이블을 공유하며, 이는 열린 파일들의 집합을 표현하고 관리한다.
- 각 파일 테이블 항목은 다음을 포함한다:
- 현재 파일 위치(file position)
- 이 항목을 가리키는 디스크립터 수를 나타내는 reference count
- v-node 테이블 항목에 대한 포인터
- 디스크립터를 닫을 때, 해당 파일 테이블 항목의 reference count는 감소하며, 커널은 reference count가 0이 될 때까지 해당 파일 테이블 항목을 삭제하지 않는다.
- v-node 테이블
- 파일 테이블과 마찬가지로, v-node 테이블도 모든 프로세스가 공유한다.
- 각 항목은 stat 구조체의 대부분의 정보(st_mode, st_size 등)를 포함한다.
-
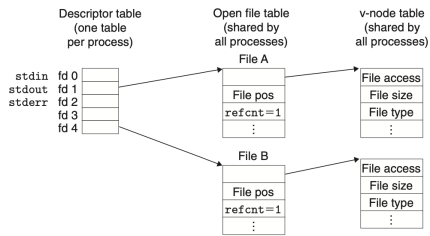 Figure 4. Typical kernel data structures for open files
Figure 4. Typical kernel data structures for open files -
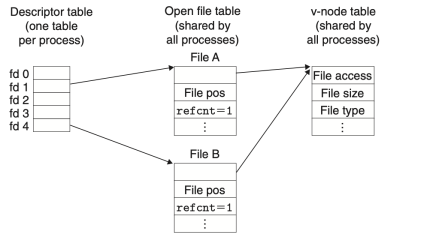 Figure 5. File sharing
Figure 5. File sharing



Figure 4는 디스크립터 1번과 4번이 서로 다른 파일 테이블 항목을 통해 서로 다른 파일을 참조하는 것을 보여준다. 이는 일반적인 경우로, 파일이 공유되지 않고 각 디스크립터가 별개의 파일을 참조하는 경우이다. 하지만, 여러 개의 디스크립터가 서로 다른 파일 테이블 항목을 통해 동일한 파일을 참조할 수도 있다. 이는 Figure 5에서 잘 나타나 있다. 이러한 상황은 같은 파일 이름으로 open() 함수를 두 번 이상 호출할 때 발생한다. 이때 각 디스크립터는 자체적인 파일 위치(file position)를 가지며, 서로 다른 디스크립터로 읽기를 수행하면, 파일의 서로 다른 위치에서 데이터를 읽어올 수 있다는 것이다. Figure 5의 경우에서 fd1과 fd4는 동일한 파일을 참조하고 있음에도, 서로 다른 파일 위치를 가지고 있어 독립적인 읽기, 쓰기의 수행이 가능하다.
부모와 자식 프로세스가 파일을 공유한다는 것은 서로의 디스크립터가 같은 파일 위치를 가지고 있다는 것을 의미한다. fork() 호출 이전에, 부모 프로세스가 Figure 4와 같은 열린 파일을 가지고 있다고 가정하자. Figure 6는 fork() 함수가 실행된 후에 자식 프로세스는 부모의 디스크립터 테이블의 복사본을 가지고 있는 상황을 보여준다. 즉, 부모와 자식은 동일한 파일 테이블 항목들을 공유하며,
따라서 동일한 파일 위치(file position)를 공유한다. 따라서 부모와 자식 모두 해당 파일 테이블을 참조하는 디스크립터를 닫아야 커널이 해당 파일 테이블 항목을 삭제할 수 있다.
I/O Redirection
Linux 셸은 사용자가 표준 입력 및 출력을 디스크 파일과 연결할 수 있도록 하는 I/O 리디렉션 연산자들을 제공한다. 예를 들어,
linux> ls > foo.txt
를 입력하면 셸은 ls 프로그램을 로드하고 실행하며, 표준 출력을 디스크 파일 foo.txt로 리디렉션한다.
_function_call.png)
.png)
이때 I/O redirection을 실행하는 방법은 몇가지가 있지만, 그중 대표적인 방법은 dup2() 함수를 이용하는 것이다.
#include <unistd.h>
int dup2(int oldfd, int newfd); //양수인 파일 디스크립터, 오류일 때 -1 반환
dup2 함수는 디스크립터 테이블 항목 oldfd를 newfd에 복사한다. 이때 newfd의 기존 항목은 덮어쓰며, 만약 newfd가 이미 열려 있다면 dup2는 먼저 그것을 닫은 다음 oldfd를 복사한다. 해당 함수의 동작 방식은 figure 7에 나타나 있다. 예를 들어 dup2(4, 1)을 호출하기 전 상황이 Figure 4와 같다고 하자. 만약 dup2(4, 1)을 호출한 후에는 상황은 Figure 8과 같이 되어 있다:
- 두 디스크립터 모두 파일 B를 가리킨다.
- 파일 A는 닫혔고, 그에 해당하는 파일 테이블 및 v-node 테이블 항목도 삭제되었다.
- 그리고 파일 B의 referential count는 1 증가한다.
이 시점부터, 표준 출력으로 쓰이는 모든 데이터는 파일 B로 리디렉션된다.
Standard I/O
C 언어는 프로그래머에게 Unix I/O보다 더 고수준의 대안을 제공하는 고수준 입력 및 출력 함수 집합, 즉 표준 I/O 라이브러리를 정의한다. 해당 라이브러리는 다음과 같은 함수들을 제공한다.
- 파일 열고 닫기:
fopen(),fclose() - 바이트 I/O:
fread(),fwrite() - 문자열 I/O:
fgets(),fputs() - formatted I/O:
scanf(),printf()
표준 I/O 라이브러리는 열린 파일을 스트림(stream)으로 모델링한다. 이때 스트림이란 FILE 타입의 구조체를 가리키는 포인터이다. 모든 ANSI C 프로그램은 다음과 같은 세 개의 열린 스트림으로 시작한다:
#include <stdio.h>
extern FILE *stdin; /* 표준 입력 (디스크립터 0) */
extern FILE *stdout; /* 표준 출력 (디스크립터 1) */
extern FILE *stderr; /* 표준 에러 (디스크립터 2) */


FILE 타입의 스트림은 파일 디스크립터와 스트림 버퍼에 대한 abstraction이며, 해당 스트림 버퍼의 목적은 RIO I/O의 그것과 같다. 즉, 비용이 많이 드는 Linux I/O 시스템 호출의 수를 최소화하기 위함이다. 응용 프로그램은 종종 한번에 하나의 문자를 읽고 쓰는 경우가 있다. 만약 스트림 버퍼가 없다면 각각의 입출력에 대해 커널이 호출되어 프로그램의 동작 속도가 느려질 것이다. 하지만 스트림 버퍼는 이를 해결할 수 있다.
예를 들어, 어떤 프로그램이 getc 표준 I/O 함수를 반복 호출한다고 가정하자.
getc()함수가 처음 호출되면, 라이브러리는read()함수를 한 번 호출하여 스트림 버퍼를 채운다.- 그 다음, 버퍼의 첫 바이트를 응용 프로그램에 반환한다.
- 버퍼에 읽히지 않은 바이트가 남아 있는 한, 이후의
getc()함수 호출들은 스트림 버퍼에서 처리될 수 있다.

Figure 10은 스트림 버퍼(lined-buffer)가 어떻게 작동하는지 보여주는 예시이다. 각 문자 출력은 stdout의 내부 버퍼에 저장되며, '\n'을 만나거나, fflush(stdout)을 하거나, exit() 또는 main 종료 시 write() 호출되어 출력된다. 해당 예시에서는,
- printf("h"); → 버퍼에 'h' 저장
- printf("e"); → 버퍼에 'e' 추가
- printf("l"); → 버퍼에 'l' 추가
- printf("l"); → 버퍼에 'l' 추가
- printf("o"); → 버퍼에 'o' 추가
- printf("\n"); → 버퍼에 '\n' 추가됨과 동시에 버퍼 플러시 발생
이를 리눅스 strace로 관찰하면, Figure 11과 같이 5개의 printf()가 모두 버퍼에 쌓였다가, write(1, ...)이 한 번만 호출되고 "hello\n" 전체가 출력된 것처럼 보인다.
Unix I/O vs. Standard I/O vs. RIO

Unix I/O 모델은 OS 커널에 의해 구현된다. 이 모델은 애플리케이션에 open(), close(), lseek(), read(), write(), stat()과 같은 함수를 통해 제공된다. 더 고수준의 Rio 함수들과 표준 I/O 함수들은 Unix I/O 함수들을 기반으로 하여 구현된다.
- Rio 함수들은 read와 write에 대한 견고한(wrapper) 래퍼 함수로, 정식으로 제공되는 함수는 아니다.
- Rio 함수들은 short count를 자동으로 처리하고, 효율적인 버퍼링 I/O 방식을 제공한다.
- 표준 I/O 함수들은
printf()와scanf()함수와 같은 형식화된(formatted) I/O 함수를 포함해, 보다 완전한 버퍼링 I/O 함수를 제공한다.
이때 어떠한 기준으로 I/O 함수들을 사용해야 하는가?
- 가능한 한 가장 고수준의 I/O 함수들을 이용해야 한다.
- 표준 I/O 함수: 디스크와 터미널 장치에서의 I/O에 가장 적합한 방법이다.[8]
- Unix I/O 함수: 시그널 핸들러 내에서는 UNIX I/O 함수가 async-signal-safe하므로 사용되어야 한다.
- RIO I/O 함수: 네트워크 소켓에 대한 I/O를 실행하고자 할 때 사용되어야 한다.
- 마지막으로,
scanf()나rio_readlineb()를 binary 파일 읽기에 사용해서는 안된다.
Pros and Cons of Unix I/O
Unix I/O의 장점은 아래와 같다.
- 가장 일반적이고 오버헤드가 가장 낮은 I/O 방식으로, 모든 I/O 패키지들이 Unix I/O 함수들 위에 구현된다.
- 파일 메타데이터에 접근할 수 있어
stat(),fstat()와 같은 함수를 사용할 수 있다. - 시그널 핸들러에서 안전하게 사용 가능(async-signal-safe)하여
read(),write함수는 시그널 핸들러 안에서도 안심하고 쓸 수 있다.
Unix I/O의 단점은 아래와 같다.
- short count를 직접 처리해야 하므로 반복해서
read(),write함수를 호출해야 한다. - 텍스트 라인 읽기를 효율적으로 하려면 버퍼링이 필요한데, 직접 버퍼를 만들고 다루는 것은 오류 발생 가능성이 높다.
Pros and Cons of Standard I/O
표준 I/O의 장점은 아래와 같다.
- 버퍼를 이용해 시스템 콜(read, write) 횟수를 줄여 성능을 향상시킬 수 있다.
getc()함수를 여러 번 호출해도 실제read()함수 호출은 한 번만 이루어진다.- short count를 자동으로 처리할 수 있다.
표준 I/O의 단점은 아래와 같다.
- 파일 메타데이터에 접근하는 기능이 없어
stat()함수 호출 등은 Unix I/O로만 가능하다. - async-signal-safe한 함수가 아니기 때문에 시그널 핸들러에서 쓰면 예기치 않은 동작이 발생할 수 있다.
- 네트워크 소켓의 I/O에는 부적합하다.