Router: 두 판 사이의 차이
편집 요약 없음 |
|||
| (같은 사용자의 중간 판 44개는 보이지 않습니다) | |||
| 16번째 줄: | 16번째 줄: | ||
==Input port function== | ==Input port function== | ||
[[파일:Input port processing.png|섬네일|300x300픽셀|'''Figure 2. Input port processing''' ]] | |||
Figure 2는 입력 포트에 대한 더욱 자세한 이미지를 제공한다. 위 문단에서 다뤘듯이, 입력 포트에는 physical/link layer의 기능에 해당하는 line-termination과 data link processing과 같은 기능을 수행하는 부분도 존재하지만, 해당 문서에서는 입력 포트가 제공하는 '''look up''' 기능에 초점을 맞춘다. 입력 포트에서 조회되는 lookup은 라우터 동작의 핵심이다. 해당 과정에서 라우터는 '''forwarding table을 조회(lookup)'''하여 도착한 패킷이 '''어떤 출력 포트로 전달될 지'''를 결정한다.<ref>Forwarding table은 라우팅 프로세서가 다른 라우터들과 상호작용하여 계산하거나, remote SDN controller로부터 수신한다.</ref><br> | Figure 2는 입력 포트에 대한 더욱 자세한 이미지를 제공한다. 위 문단에서 다뤘듯이, 입력 포트에는 physical/link layer의 기능에 해당하는 line-termination과 data link processing과 같은 기능을 수행하는 부분도 존재하지만, 해당 문서에서는 입력 포트가 제공하는 '''look up''' 기능에 초점을 맞춘다. 입력 포트에서 조회되는 lookup은 라우터 동작의 핵심이다. 해당 과정에서 라우터는 '''forwarding table을 조회(lookup)'''하여 도착한 패킷이 '''어떤 출력 포트로 전달될 지'''를 결정한다.<ref>Forwarding table은 라우팅 프로세서가 다른 라우터들과 상호작용하여 계산하거나, remote SDN controller로부터 수신한다.</ref><br> | ||
Forwarding table은 라우팅 프로세서로부터 별도의 [[bus]]를 통해 line card로 복사된다.<ref>line card는 많은 포트가 모여있는 하드웨어 장치이다.</ref> 이렇게 각 line card에 forwarding table의 복사본이 존재한다면, 각각의 입력 포트가 자체적으로 forwarding 결정을 내릴 수 있게 되고, 매 패킷마다 라우팅 프로세스를 호출하지 않아도 되므로 그 효율성이 증대된다. 이런 방식을 '''decentralized switching'''이라고 하며, 이는 figure 1의 라우팅 프로세스와 입력 포트 사이의 점선에 잘 나타나 있다. | Forwarding table은 라우팅 프로세서로부터 별도의 [[bus]]를 통해 line card로 복사된다.<ref>line card는 많은 포트가 모여있는 하드웨어 장치이다.</ref> 이렇게 각 line card에 forwarding table의 복사본이 존재한다면, 각각의 입력 포트가 자체적으로 forwarding 결정을 내릴 수 있게 되고, 매 패킷마다 라우팅 프로세스를 호출하지 않아도 되므로 그 효율성이 증대된다. 이런 방식을 '''decentralized switching'''이라고 하며, 이는 figure 1의 라우팅 프로세스와 입력 포트 사이의 점선에 잘 나타나 있다. | ||
| 22번째 줄: | 23번째 줄: | ||
===Destination-based forwarding=== | ===Destination-based forwarding=== | ||
<gallery widths="380" heights="250px"> | |||
Else-if forwarding table.png|Figure 3. Else-if forwarding table | |||
Long prefix matching forwarding table.png|Figure 4. Long prefix matching forwarding table | |||
</gallery> | |||
'''Destination-based forwarding'''는 패킷이 목적지 주소(IP 주소)를 바탕으로 어떤 출력 포트로 스위칭(switching)될지 결정하는 작업이다. 이를 구현하는 가장 단순한 방법으로는 forwarding table을 brute-force 방식으로 구현하는 것이다. 이는 모든 IP 주소에 대해 하나의 항목을 1대1 매칭하는 방법으로, 전세계에 수십억개의 IP 주소가 존재하기 때문에 전혀 실현 불가능한 방법이다.<br> | '''Destination-based forwarding'''는 패킷이 목적지 주소(IP 주소)를 바탕으로 어떤 출력 포트로 스위칭(switching)될지 결정하는 작업이다. 이를 구현하는 가장 단순한 방법으로는 forwarding table을 brute-force 방식으로 구현하는 것이다. 이는 모든 IP 주소에 대해 하나의 항목을 1대1 매칭하는 방법으로, 전세계에 수십억개의 IP 주소가 존재하기 때문에 전혀 실현 불가능한 방법이다.<br> | ||
다른 방법으로는, figure 3과 같이 단 4개의 출력 포트에 대한 forwarding table을 구성할 수 있다. figure 3은 IP 주소의 범위를 제시하고, 해당 범위 안에 패킷의 IP 주소가 들어가는지 아닌지를 판별하여 패킷의 출력 포트를 정한다. 하지만 이 방식은 기본적으로 if-else로 구현되기 때문에 비효율적이라는 방식이 있다.<br> | 다른 방법으로는, figure 3과 같이 단 4개의 출력 포트에 대한 forwarding table을 구성할 수 있다. figure 3은 IP 주소의 범위를 제시하고, 해당 범위 안에 패킷의 IP 주소가 들어가는지 아닌지를 판별하여 패킷의 출력 포트를 정한다. 하지만 이 방식은 기본적으로 if-else로 구현되기 때문에 비효율적이라는 방식이 있다.<br> | ||
이러한 한계를 극복한 방식이 '''longest prefix matching'''이다. 이 방식을 사용하기 위해서는 figure 3에 나타난 forwarding table을 figure 4와 같이 바뀌어야 한다. 이와 같은 forwarding table에서 라우터는 패킷의 IP 주소의 prefix를 테이블의 항목들과 비교하여, 일치하면 해당 출력 포트로 forwarding한다. 예를 들어 패킷의 목적지 주소가 <code>11001000 00010111 00010110 10100001</code>라면, 이 주소의 앞 21비트 가 첫 번째 테이블 항목과 일치하므로, 이 패킷은 링크 인터페이스 0번 으로 전달된다. 하지만, 어떤 IP 주소는 테이블의 여러 항목과 동시에 일치할 수 있다. 예를 들어 <code>11001000 00010111 00011000 10101010</code>의 앞 24비트는 두 번째 항목과, 앞의 21비트는 세 번째 항목과 일치한다. 이러한 경우 '''longest prefix matching rule'''을 사용하여 '''가장 긴 prefix를 가진 항목을 찾아, 그 해당 항목에 해당하는 링크 인터페이스로 패킷을 forwarding'''한다. longest prefix matching이 사용되는 이유는 IP 주소를 어떻게 할당하는지와 밀접하게 관련되어 있다. | 이러한 한계를 극복한 방식이 '''longest prefix matching'''이다. 이 방식을 사용하기 위해서는 figure 3에 나타난 forwarding table을 figure 4와 같이 바뀌어야 한다. 이와 같은 forwarding table에서 라우터는 패킷의 IP 주소의 prefix를 테이블의 항목들과 비교하여, 일치하면 해당 출력 포트로 forwarding한다. 예를 들어 패킷의 목적지 주소가 <code>11001000 00010111 00010110 10100001</code>라면, 이 주소의 앞 21비트 가 첫 번째 테이블 항목과 일치하므로, 이 패킷은 링크 인터페이스 0번 으로 전달된다. 하지만, 어떤 IP 주소는 테이블의 여러 항목과 동시에 일치할 수 있다. 예를 들어 <code>11001000 00010111 00011000 10101010</code>의 앞 24비트는 두 번째 항목과, 앞의 21비트는 세 번째 항목과 일치한다. 이러한 경우 '''longest prefix matching rule'''을 사용하여 '''가장 긴 prefix를 가진 항목을 찾아, 그 해당 항목에 해당하는 링크 인터페이스로 패킷을 forwarding'''한다. longest prefix matching이 사용되는 이유는 IP 주소를 어떻게 할당하는지와 밀접하게 관련되어 있다.<br> | ||
위의 메커니즘을 통해서 출력 포트가 결정된 패킷은 switching fabric으로 전달된다. | |||
==Switching== | |||
'''Switching fabric'''은 라우터의 심장부에 해당하며, 이 '''fabric을 통해서 패킷이 입력 포트에서 출력 포트로 실제로 이동(switching)'''된다. 이때 switching의 수행 방식은 메모리를 통한 switching, 버스(bus)를 통한 switching, 상호 연결 네트워크를 통한 switching과 같이 크게 3가지로 나뉜다. | |||
===Switching via memory=== | |||
[[파일:Switching via memory.png|대체글=Figure 5. Switching via memory|섬네일|300x300픽셀|Figure 5. Switching via memory]] | |||
메모리를 통한 switching(switching via memory)은 가장 오래된 switching 방식이다. 해당 방식은 라우터가 전통적인 컴퓨터처럼 CPU(라우팅 프로세서)의 직접 제어하에 입력 포트와 출력 포트 간의 switching을 수행한다. 이는 다음과 같은 방식으로 수행된다: | |||
# 입력 포트와 출력 포트는 전통적인 운영체제에서의 입출력 장치처럼 작동한다. | |||
#* 패킷이 도착하면, 입력 포트는 [[Exception#Interrupts (Asynchronous Exceptions)|인터럽트]]를 통해 라우팅 프로세서에 신호를 보낸다. | |||
# 라우팅 프로세서는 입력 포트에서 패킷을 메모리로 복사하고, 헤더에서 IP 주소를 추출, 포워딩 테이블을 조회하여, 출력 포트 버퍼로 복사한다. | |||
이런 구조에서는 '''메모리 bandwidth가 B라고 할때, 전체 forwarding throughput은 B/2 미만'''이다. 이는 메모리는 한번에 하나의 읽기/쓰기만 가능하기 때문에 서로 다른 출력 포트로 가는 패킷이라도 동시에 forwarding 할 수 없기 때문이다. | |||
===Switching via a bus=== | |||
[[파일:Switching via bus.png|대체글=Figure 6. Switching via bus|섬네일|300x300픽셀|Figure 6. Switching via bus]] | |||
버스를 통한 switching(switching via a bus) 방식에서는, 입력 포트가 '''라우팅 프로세서의 개입 없이, 공유 버스(shared bus)'''를 통해 패킷을 직접 출력 포트로 전송(switching)한다. 이는 다음과 같은 같은 방식으로 수행된다: | |||
# 입력 포트는 패킷에 출력 포트 번호를 포함하는 라벨을 붙여 버스로 전송한다. | |||
# 모든 출력 포트가 이 패킷을 수신하지만, 라벨과 일치하는 출력 포트만 해당 패킷을 받아들인다. | |||
#* 라벨은 스위치 내부에서만 사용되므로 출력 포트에서는 제거된다. | |||
버스를 통한 switching 방식은 각 라우터에 하나의 버스만 존재하기 때문에, 여러 입력 포트에서 동시에 패킷이 도착하더라도 한번에 하나의 패킷만 버스를 사용할 수 있고 나머지 패킷은 대기해야 한다는 문제를 가지고 있다. 결국, 이 방식에서는 버스의 속도에 switching 속도가 제한된다.<br> | |||
이 방식을 사용하는 라우터로는 Cisco 5600 등이 있는데, 이는 32Gbps 버스를 통해 패킷을 switching한다. | |||
===Switching via an interconnection network=== | |||
[[파일:Crossbar switching.png|대체글=Figure 7. Crossbar switching|섬네일|267x267픽셀|Figure 7. Crossbar switching]] | |||
하나의 공유되는 버스의 bandwidth 한계를 해결하기 위해 도입된 방식은 상호연결을 통한 switching(switching via an interconnection network)이다. 해당 방식은 banyan networks, crossbar와 같은 여러가지 구조들을 통해서 수행되지만, 그중에서도 crossbar 구조는 다음과 같이 구현된다: | |||
* '''Crossbar switch''' | |||
** 2N개의 버스로 구성된 네트워크로, N개의 입력 포트와 N개의 출력 포트를 연결한다. | |||
** 각 수직 버스와 수평 버스가 교차하는 교차점(crosspoint) 은 switch fabric controller가 열거나 닫을 수 있다. | |||
예를 들어, crossbar switch에서 포트 A에서 도착한 패킷이 포트 Y로 가야 한다면, controller가 A-Y 교차점을 열고, 포트 A는 자신과 연결된 버스로 패킷을 보내고 출력 버스 Y가 이를 받아간다. 이때, 포트 B에서 포트 Y로 가는 패킷은 A-Y 경로와 겹치지 않으면 동시에 전송 가능하다는 특징이 있다. 즉, crossbar switch 방식은 '''복수의 패킷을 병렬적으로 전달할 수 있다는 이점'''이 있다.<br> | |||
이 방식을 사용하는 라우터로는 Cisco 12000 등이 있는데, 이는 60Gbps crossbar 상호 연결 네트워크를 통해서 패킷을 switching한다. | |||
==Output Port Processing== | |||
[[파일:Output Port Processing.png|대체글=Figure 8. Output Port Processing|가운데|섬네일|300x300픽셀|Figure 8. Output Port Processing]] | |||
출력 포트는 figure 8과 같이 출력 포트의 버퍼에 저장된 패킷들을 꺼내어 출력 링크(link)를 통해 전송하는 과정을 포함한다. 이 과정에는 전송을 위한 패킷 선택 및 큐에서 제거(de-queueing), 필요한 pyhsical/link layer transmission 기능 수행이 포함된다. | |||
==Queueing in input/output port== | |||
패킷 queueing은 입력 포트와 출력 포트 모두에서 형성될 수 있다. Queueing이 어디에서, 얼마나 많이 발생하는지는 다음에 따라 달라진다. | |||
* Traffic load(트래픽 부하) | |||
* Switching fabric의 상대적인 속도 | |||
* link의 transmission rate | |||
위 상황에 대해 알아보기 위해, 예를 들어 입력 및 출력 링크의 전송 속도가 동일하며, 각각 초당 R<sub>line</sub>개의 패킷을 전송할 수 있으며, 입력 포트와 출력 포트가 각각 N개씩 존재한다고 하자. 또한 단순한 논의를 위해 모든 패킷은 고정된 길이를 갖고, 패킷은 synchronous하게 입력 포트에 도착한다고 가정하자.<ref>즉, 어떤 링크든 패킷을 보내는 데 걸리는 시간과 받는 데 걸리는 시간은 같으며, 이 시간 동안 0개 또는 1개의 패킷만 입력 링크로 도착한다.</ref> 이때, 스위칭 패브릭의 전송 속도 R<sub>switch</sub>를 패킷을 입력 포트에서 출력 포트로 전달할 수 있는 속도라고 정의하자.<br> | |||
이때, R<sub>switch</sub> 가 R<sub>line</sub>보다 N배 빠르다면, 입력 포트에서 발생하는 큐잉은 거의 무시할 수 있을 정도로 작다. 그 이유는 최악의 경우, N개의 N개의 입력 라인이 모두 패킷을 받고 있으며, 이 모든 패킷이 동일한 출력 포트로 전달되어야 한다고 하더라도, 각 입력 포트 당 하나씩 총 N개의 패킷들은 다음 패킷이 도착하기 전까지 switch fabric을 통해 모두 처리될 수 있기 때문이다. 하지만, 이 경우에는 단 하나의 출력 포트에 모든 패킷이 몰리므로, 출력 포트의 queue가 증가한다.<br> | |||
이때 queue가 너무 커지면 라우터의 메모리가 결국 소진되며, 더이상 패킷을 저장할 메모리가 없을 경우 패킷 손실이 발생한다. 즉, 패킷의 내트워크 내 손실(loss), 라우터 내 패킷 드랍(drop)들은 실제로는 라우터 내부의 queue에서 해당 패킷들이 손실되는 것이다. | |||
===Input Queueing=== | |||
[[파일:HOL blocking at and input-queued switch.png|대체글=Figure 9. HOL blocking at and input-queued switch|섬네일|'''Figure 9. HOL blocking at and input-queued switch''' ]] | |||
입력 포트에 있는 queue는 switch fabric이 입력 포트에서 수신된 패킷들을 충분히 빠르게 내부로 전달하지 못할 경우, 도착한 패킷들이 일시적으로 입력 포트에 머물게 되어 큐가 증가한다. 이러한 queueing이 가지는 결과를 설명하기 위해, crossbar switching fabric를 가정하고 다음과 같은 조건을 생각해보자: | |||
# 모든 링크 속도는 동일하다. | |||
# 어떤 입력 포트에서 출력 포트로 패킷을 전송하는 데 걸리는 시간은 입력 링크에서 패킷 하나를 수신하는 데 걸리는 시간과 동일하다. | |||
# 각 입력 큐에서 패킷은 FCFS(First-Come, First-Served) 방식으로 전달된다. | |||
이때 각기 다른 출력 포트로 향하는 패킷들은 병렬로 전달될 수 있다. 그러나 만약 두 입력 포트의 입력 queue 맨 앞에 있는 패킷이 같은 출력 포트를 향하고 있다면, 그 중 하나는 차단되어 대기해야 한다.<ref>이는 switching fabric이 한 번에 하나의 패킷만 특정 출력 포트로 보낼 수 있기 때문이다.</ref> Figure 9는 이 상황을 보여준다. 해당 figure에서 1, 3번 포트 queue 앞에 패킷들이 모두 1번 출력 포트를 향하고 있다. 이때 switch fabric이 1번 입력 포트 queue의 패킷을 선택하여 전송하고자 한다면, 그 동안 3번 포트 queue는 대기해야 한다. 그런데 문제는 3번 입력 포트 queue의 첫 패킷 뿐만 아니라 그 뒤에 있는 패킷들로 전송되지 못한다는 것이다. 그 뒤의 패킷은 switch fabric 경쟁이 없는 출력 포트를 향하고 있지만 그 앞의 패킷이 막고 있어 전송되지 못하는 상황이다. 이러한 현상을 '''HOL(Head-of-the-Line) blocking'''이라고 부른다. 즉, 입력 포트의 queue에 있는 '''어떤 패킷이 자신 보다 앞에서 대기하는 패킷 때문에 함께 대기'''하는 현상이다. | |||
===Output Queueuing=== | |||
[[파일:Output port queueing.png|대체글=Figure 10. Output port queueing|섬네일|'''Figure 10. Output port queueing''' ]] | |||
출력 포트도 queueing을 피할 수는 없다. R<sub>switch</sub>가 R<sub>line</sub>보다 N배 빠르다고 가정하고, N개의 입력 포트 각각에서 도착하는 패킷들이 모두 같은 출력 포트를 향하고 있다고 하자. 이 경우, 출력 포트가 출력 링크에 패킷 하나를 전송하는 동안, N개의 새로운 패킷이 해당 출력 포트로 도착한다. 이때 '''출력 포트는 단위 시간당 한 개의 패킷만 전송할 수 있으므로, N-1개의 패킷은 대기열에 저장(queueing)'''된다. 이것이 반복되면 출력 포트의 queueing이 계속해서 증가하며, 결국 '''패킷 드랍(buffer overflow)이 발생'''할 수 있다. 설사 패킷이 손실되지 않더라도 queue가 과도하게 증가하면 '''d<sub>queue</sub>가 증가'''하여 네트워크를 지연시키는 문제가 발생한다. 이는 figure 10에 잘 드러나 있다. 단위 시간 t마다 각각의 입력 포트로부터 패킷이 하나씩 도착하고, 이들은 모두 1번 출력 포트로 향하고 있다. 이때 R<sub>switch</sub>가 R<sub>line</sub>보다 3배 빠르다면, t 시간 후 세 세개의 패킷은 출력 포트로 전송 완료되고 출력 포트 queue에서 대기한다. 그 다음 단위 시간 동안, 이 세 개 중 하나의 패킷이 전송되고, 동시에 입력 포트로부터 새로운 패킷 하나가 1번 출력 포트 queue에 추가된다. | |||
위의 예시를 보면 알 수 있듯이, 출력 포트 버퍼의 크기는 입력 포트 버퍼의 크기보다 반드시 커야 한다. 이때 '''버퍼의 크기(B)는 RTT와 link capacity(C)'''에 의해서 다음과 같은 경험적인 수식으로 결정된다. | |||
B = RTT x C | |||
예를 들어 RTT가 250ms이고 링크가 10Gbps이면 <code>B = 0.25초 × 10Gbps = 2.5Gbit</code> 의 버퍼가 필요하다. | |||
===Discard policy=== | |||
'''Discard policy'''란 입력/출력 포트 버퍼에 패킷이 가득 차면 어떤 패킷을 버릴지 결정하는 정책이다. 아래는 현실에서 자주 사용되는 discard policy에 대한 간략한 설명이다. | |||
{| class="wikitable" | |||
|+ | |||
!Discard policy | |||
!설명 | |||
|- | |||
|tail drop | |||
|가장 나중에 도착한 패킷을 버린다. | |||
|- | |||
|priority-based drop | |||
|priority가 가장 낮은 패킷을 우선적으로 선택하여 버린다. | |||
|- | |||
|random drop | |||
|임의의 패킷을 선택하여 버린다. | |||
|} | |||
===[[Packet Scheduling]]=== | |||
자세한 내용은 [[Packet Scheduling]] 문서를 참조하십시오. | |||
==각주== | ==각주== | ||
[[분류:컴퓨터 네트워크]] | [[분류:컴퓨터 네트워크]] | ||
2025년 4월 19일 (토) 05:10 기준 최신판
상위 문서: Network Layer
개요
라우터(router)는 netwrok layer에서 가장 핵심적인 장치라 해도 과언이 아니다. 특히, SDN 관점에서 라우터는 컴퓨터 네트워크에서 데이터그램(datagram)을 목적지까지 전달하기 위해 경로를 선택하고 전달을 수행(forwarding)하는 네트워크 장비이다. 해당 문서에서는, 라우터의 forwarding 기능에 주목하여 라우터의 구조와, 패킷을 입력 링크(link)에서 적절한 출력 링크로 전달하는 과정에 주목하여 서술한다.
Structure of router
Figure 1에서 볼 수 있듯이, 라우터는 control plane과 data plane으로 나뉘어 구현된다. Control plane(routing)은 보통 소프트웨어적으로 구현되며, 해당 작업에는 보통 수 밀리초가 소요된다. Data plane(forwarding)은 보통 하드웨어적으로 구현되어 보통 수 나노초가 소요된다. 라우터은 일반적으로 네 가지의 구성 요소로 이루어져 있다고 할 수 있다.
먼저, 입력 포트(input port)이다. 이때 'port'라는 용어는 물리적인 입력/출력 인터페이스를 의미하며, applicaton layer의 socket이나, transport layer의 port 번호 등의 개념과는 완전히 구분되는 개념이다. 입력 포트는 아래와 같은 여러 핵심적인 기능을 수행한다.
- physical layer 기능: 수신되는 physical 링크를 라우터에서 종료시킨다.
- link layer 기능: 수신 링크의 반대편에 있는 link layer와 상호 운용하기 위한 기능이다.
- Look up 기능: Forwarding table을 참조하여 도착한 패킷이 switching fabric을 통해 어떤 출력 포트로 전달되어야 하는지를 결정한다.
- Control 패킷 처리: Routing 프로토콜 정보를 담은 control packet 등은 입력 포트에서 라우팅 프로세서로 전달된다.
두 번째로는 Switching fabric이 있다. Switching fabric은 입력 포트와 출력 포트를 연결하는 장치로, 일종의 '라우터 안의 네트워크'처럼 작동한다.
세 번째로는 출력 포트(output port)가 있다. 출력 포트는 switching fabric으로부터 수신한 패킷을 저장하고, link/physical layer 기능을 수행해 적절한 출력 링크로 해당 패킷을 전송한다.
마지막으로, 라우팅 프로세서(routing processor)는 control plane 기능을 수행한다.[1] 전통적인 라우터에서는 routing 프로토콜을 실행하거나, forwarding table을 계산하는 등의 작업을 한다. 하지만 SDN 라우터에서는 라우팅 프로세서가 remote controller와 통신하여 해당 controller가 계산한 forwarding table을 받아 입력 포트에 설치하는 등의 작업을 수행한다. 또한 네트워크 관리 기능도 한다.
Input port function

Figure 2는 입력 포트에 대한 더욱 자세한 이미지를 제공한다. 위 문단에서 다뤘듯이, 입력 포트에는 physical/link layer의 기능에 해당하는 line-termination과 data link processing과 같은 기능을 수행하는 부분도 존재하지만, 해당 문서에서는 입력 포트가 제공하는 look up 기능에 초점을 맞춘다. 입력 포트에서 조회되는 lookup은 라우터 동작의 핵심이다. 해당 과정에서 라우터는 forwarding table을 조회(lookup)하여 도착한 패킷이 어떤 출력 포트로 전달될 지를 결정한다.[2]
Forwarding table은 라우팅 프로세서로부터 별도의 bus를 통해 line card로 복사된다.[3] 이렇게 각 line card에 forwarding table의 복사본이 존재한다면, 각각의 입력 포트가 자체적으로 forwarding 결정을 내릴 수 있게 되고, 매 패킷마다 라우팅 프로세스를 호출하지 않아도 되므로 그 효율성이 증대된다. 이런 방식을 decentralized switching이라고 하며, 이는 figure 1의 라우팅 프로세스와 입력 포트 사이의 점선에 잘 나타나 있다.
이때 forwarding table을 이용하여 lookup을 진행하는 것은 기본적으로 패킷의 헤더 필드와 forwarding table을 비교하는 것이다. 이때 forwarding 방식은 destination-based forwarding과 generalized forwarding로 나뉘어진다.
Destination-based forwarding
-
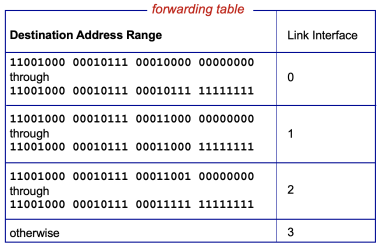 Figure 3. Else-if forwarding table
Figure 3. Else-if forwarding table -
 Figure 4. Long prefix matching forwarding table
Figure 4. Long prefix matching forwarding table


Destination-based forwarding는 패킷이 목적지 주소(IP 주소)를 바탕으로 어떤 출력 포트로 스위칭(switching)될지 결정하는 작업이다. 이를 구현하는 가장 단순한 방법으로는 forwarding table을 brute-force 방식으로 구현하는 것이다. 이는 모든 IP 주소에 대해 하나의 항목을 1대1 매칭하는 방법으로, 전세계에 수십억개의 IP 주소가 존재하기 때문에 전혀 실현 불가능한 방법이다.
다른 방법으로는, figure 3과 같이 단 4개의 출력 포트에 대한 forwarding table을 구성할 수 있다. figure 3은 IP 주소의 범위를 제시하고, 해당 범위 안에 패킷의 IP 주소가 들어가는지 아닌지를 판별하여 패킷의 출력 포트를 정한다. 하지만 이 방식은 기본적으로 if-else로 구현되기 때문에 비효율적이라는 방식이 있다.
이러한 한계를 극복한 방식이 longest prefix matching이다. 이 방식을 사용하기 위해서는 figure 3에 나타난 forwarding table을 figure 4와 같이 바뀌어야 한다. 이와 같은 forwarding table에서 라우터는 패킷의 IP 주소의 prefix를 테이블의 항목들과 비교하여, 일치하면 해당 출력 포트로 forwarding한다. 예를 들어 패킷의 목적지 주소가 11001000 00010111 00010110 10100001라면, 이 주소의 앞 21비트 가 첫 번째 테이블 항목과 일치하므로, 이 패킷은 링크 인터페이스 0번 으로 전달된다. 하지만, 어떤 IP 주소는 테이블의 여러 항목과 동시에 일치할 수 있다. 예를 들어 11001000 00010111 00011000 10101010의 앞 24비트는 두 번째 항목과, 앞의 21비트는 세 번째 항목과 일치한다. 이러한 경우 longest prefix matching rule을 사용하여 가장 긴 prefix를 가진 항목을 찾아, 그 해당 항목에 해당하는 링크 인터페이스로 패킷을 forwarding한다. longest prefix matching이 사용되는 이유는 IP 주소를 어떻게 할당하는지와 밀접하게 관련되어 있다.
위의 메커니즘을 통해서 출력 포트가 결정된 패킷은 switching fabric으로 전달된다.
Switching
Switching fabric은 라우터의 심장부에 해당하며, 이 fabric을 통해서 패킷이 입력 포트에서 출력 포트로 실제로 이동(switching)된다. 이때 switching의 수행 방식은 메모리를 통한 switching, 버스(bus)를 통한 switching, 상호 연결 네트워크를 통한 switching과 같이 크게 3가지로 나뉜다.
Switching via memory

메모리를 통한 switching(switching via memory)은 가장 오래된 switching 방식이다. 해당 방식은 라우터가 전통적인 컴퓨터처럼 CPU(라우팅 프로세서)의 직접 제어하에 입력 포트와 출력 포트 간의 switching을 수행한다. 이는 다음과 같은 방식으로 수행된다:
- 입력 포트와 출력 포트는 전통적인 운영체제에서의 입출력 장치처럼 작동한다.
- 패킷이 도착하면, 입력 포트는 인터럽트를 통해 라우팅 프로세서에 신호를 보낸다.
- 라우팅 프로세서는 입력 포트에서 패킷을 메모리로 복사하고, 헤더에서 IP 주소를 추출, 포워딩 테이블을 조회하여, 출력 포트 버퍼로 복사한다.
이런 구조에서는 메모리 bandwidth가 B라고 할때, 전체 forwarding throughput은 B/2 미만이다. 이는 메모리는 한번에 하나의 읽기/쓰기만 가능하기 때문에 서로 다른 출력 포트로 가는 패킷이라도 동시에 forwarding 할 수 없기 때문이다.
Switching via a bus

버스를 통한 switching(switching via a bus) 방식에서는, 입력 포트가 라우팅 프로세서의 개입 없이, 공유 버스(shared bus)를 통해 패킷을 직접 출력 포트로 전송(switching)한다. 이는 다음과 같은 같은 방식으로 수행된다:
- 입력 포트는 패킷에 출력 포트 번호를 포함하는 라벨을 붙여 버스로 전송한다.
- 모든 출력 포트가 이 패킷을 수신하지만, 라벨과 일치하는 출력 포트만 해당 패킷을 받아들인다.
- 라벨은 스위치 내부에서만 사용되므로 출력 포트에서는 제거된다.
버스를 통한 switching 방식은 각 라우터에 하나의 버스만 존재하기 때문에, 여러 입력 포트에서 동시에 패킷이 도착하더라도 한번에 하나의 패킷만 버스를 사용할 수 있고 나머지 패킷은 대기해야 한다는 문제를 가지고 있다. 결국, 이 방식에서는 버스의 속도에 switching 속도가 제한된다.
이 방식을 사용하는 라우터로는 Cisco 5600 등이 있는데, 이는 32Gbps 버스를 통해 패킷을 switching한다.
Switching via an interconnection network

하나의 공유되는 버스의 bandwidth 한계를 해결하기 위해 도입된 방식은 상호연결을 통한 switching(switching via an interconnection network)이다. 해당 방식은 banyan networks, crossbar와 같은 여러가지 구조들을 통해서 수행되지만, 그중에서도 crossbar 구조는 다음과 같이 구현된다:
- Crossbar switch
- 2N개의 버스로 구성된 네트워크로, N개의 입력 포트와 N개의 출력 포트를 연결한다.
- 각 수직 버스와 수평 버스가 교차하는 교차점(crosspoint) 은 switch fabric controller가 열거나 닫을 수 있다.
예를 들어, crossbar switch에서 포트 A에서 도착한 패킷이 포트 Y로 가야 한다면, controller가 A-Y 교차점을 열고, 포트 A는 자신과 연결된 버스로 패킷을 보내고 출력 버스 Y가 이를 받아간다. 이때, 포트 B에서 포트 Y로 가는 패킷은 A-Y 경로와 겹치지 않으면 동시에 전송 가능하다는 특징이 있다. 즉, crossbar switch 방식은 복수의 패킷을 병렬적으로 전달할 수 있다는 이점이 있다.
이 방식을 사용하는 라우터로는 Cisco 12000 등이 있는데, 이는 60Gbps crossbar 상호 연결 네트워크를 통해서 패킷을 switching한다.
Output Port Processing

출력 포트는 figure 8과 같이 출력 포트의 버퍼에 저장된 패킷들을 꺼내어 출력 링크(link)를 통해 전송하는 과정을 포함한다. 이 과정에는 전송을 위한 패킷 선택 및 큐에서 제거(de-queueing), 필요한 pyhsical/link layer transmission 기능 수행이 포함된다.
Queueing in input/output port
패킷 queueing은 입력 포트와 출력 포트 모두에서 형성될 수 있다. Queueing이 어디에서, 얼마나 많이 발생하는지는 다음에 따라 달라진다.
- Traffic load(트래픽 부하)
- Switching fabric의 상대적인 속도
- link의 transmission rate
위 상황에 대해 알아보기 위해, 예를 들어 입력 및 출력 링크의 전송 속도가 동일하며, 각각 초당 Rline개의 패킷을 전송할 수 있으며, 입력 포트와 출력 포트가 각각 N개씩 존재한다고 하자. 또한 단순한 논의를 위해 모든 패킷은 고정된 길이를 갖고, 패킷은 synchronous하게 입력 포트에 도착한다고 가정하자.[4] 이때, 스위칭 패브릭의 전송 속도 Rswitch를 패킷을 입력 포트에서 출력 포트로 전달할 수 있는 속도라고 정의하자.
이때, Rswitch 가 Rline보다 N배 빠르다면, 입력 포트에서 발생하는 큐잉은 거의 무시할 수 있을 정도로 작다. 그 이유는 최악의 경우, N개의 N개의 입력 라인이 모두 패킷을 받고 있으며, 이 모든 패킷이 동일한 출력 포트로 전달되어야 한다고 하더라도, 각 입력 포트 당 하나씩 총 N개의 패킷들은 다음 패킷이 도착하기 전까지 switch fabric을 통해 모두 처리될 수 있기 때문이다. 하지만, 이 경우에는 단 하나의 출력 포트에 모든 패킷이 몰리므로, 출력 포트의 queue가 증가한다.
이때 queue가 너무 커지면 라우터의 메모리가 결국 소진되며, 더이상 패킷을 저장할 메모리가 없을 경우 패킷 손실이 발생한다. 즉, 패킷의 내트워크 내 손실(loss), 라우터 내 패킷 드랍(drop)들은 실제로는 라우터 내부의 queue에서 해당 패킷들이 손실되는 것이다.
Input Queueing

입력 포트에 있는 queue는 switch fabric이 입력 포트에서 수신된 패킷들을 충분히 빠르게 내부로 전달하지 못할 경우, 도착한 패킷들이 일시적으로 입력 포트에 머물게 되어 큐가 증가한다. 이러한 queueing이 가지는 결과를 설명하기 위해, crossbar switching fabric를 가정하고 다음과 같은 조건을 생각해보자:
- 모든 링크 속도는 동일하다.
- 어떤 입력 포트에서 출력 포트로 패킷을 전송하는 데 걸리는 시간은 입력 링크에서 패킷 하나를 수신하는 데 걸리는 시간과 동일하다.
- 각 입력 큐에서 패킷은 FCFS(First-Come, First-Served) 방식으로 전달된다.
이때 각기 다른 출력 포트로 향하는 패킷들은 병렬로 전달될 수 있다. 그러나 만약 두 입력 포트의 입력 queue 맨 앞에 있는 패킷이 같은 출력 포트를 향하고 있다면, 그 중 하나는 차단되어 대기해야 한다.[5] Figure 9는 이 상황을 보여준다. 해당 figure에서 1, 3번 포트 queue 앞에 패킷들이 모두 1번 출력 포트를 향하고 있다. 이때 switch fabric이 1번 입력 포트 queue의 패킷을 선택하여 전송하고자 한다면, 그 동안 3번 포트 queue는 대기해야 한다. 그런데 문제는 3번 입력 포트 queue의 첫 패킷 뿐만 아니라 그 뒤에 있는 패킷들로 전송되지 못한다는 것이다. 그 뒤의 패킷은 switch fabric 경쟁이 없는 출력 포트를 향하고 있지만 그 앞의 패킷이 막고 있어 전송되지 못하는 상황이다. 이러한 현상을 HOL(Head-of-the-Line) blocking이라고 부른다. 즉, 입력 포트의 queue에 있는 어떤 패킷이 자신 보다 앞에서 대기하는 패킷 때문에 함께 대기하는 현상이다.
Output Queueuing

출력 포트도 queueing을 피할 수는 없다. Rswitch가 Rline보다 N배 빠르다고 가정하고, N개의 입력 포트 각각에서 도착하는 패킷들이 모두 같은 출력 포트를 향하고 있다고 하자. 이 경우, 출력 포트가 출력 링크에 패킷 하나를 전송하는 동안, N개의 새로운 패킷이 해당 출력 포트로 도착한다. 이때 출력 포트는 단위 시간당 한 개의 패킷만 전송할 수 있으므로, N-1개의 패킷은 대기열에 저장(queueing)된다. 이것이 반복되면 출력 포트의 queueing이 계속해서 증가하며, 결국 패킷 드랍(buffer overflow)이 발생할 수 있다. 설사 패킷이 손실되지 않더라도 queue가 과도하게 증가하면 dqueue가 증가하여 네트워크를 지연시키는 문제가 발생한다. 이는 figure 10에 잘 드러나 있다. 단위 시간 t마다 각각의 입력 포트로부터 패킷이 하나씩 도착하고, 이들은 모두 1번 출력 포트로 향하고 있다. 이때 Rswitch가 Rline보다 3배 빠르다면, t 시간 후 세 세개의 패킷은 출력 포트로 전송 완료되고 출력 포트 queue에서 대기한다. 그 다음 단위 시간 동안, 이 세 개 중 하나의 패킷이 전송되고, 동시에 입력 포트로부터 새로운 패킷 하나가 1번 출력 포트 queue에 추가된다.
위의 예시를 보면 알 수 있듯이, 출력 포트 버퍼의 크기는 입력 포트 버퍼의 크기보다 반드시 커야 한다. 이때 버퍼의 크기(B)는 RTT와 link capacity(C)에 의해서 다음과 같은 경험적인 수식으로 결정된다.
B = RTT x C
예를 들어 RTT가 250ms이고 링크가 10Gbps이면 B = 0.25초 × 10Gbps = 2.5Gbit 의 버퍼가 필요하다.
Discard policy
Discard policy란 입력/출력 포트 버퍼에 패킷이 가득 차면 어떤 패킷을 버릴지 결정하는 정책이다. 아래는 현실에서 자주 사용되는 discard policy에 대한 간략한 설명이다.
| Discard policy | 설명 |
|---|---|
| tail drop | 가장 나중에 도착한 패킷을 버린다. |
| priority-based drop | priority가 가장 낮은 패킷을 우선적으로 선택하여 버린다. |
| random drop | 임의의 패킷을 선택하여 버린다. |
Packet Scheduling
자세한 내용은 Packet Scheduling 문서를 참조하십시오.